
"0 to 60" : Switching to indirect checkpoints
In a recent tip, I described a scenario where a SQL Server 2016 instance seemed to be struggling with checkpoint times. The error log was populated with an alarming number of FlushCache entries like this one:
FlushCache: cleaned up 394031 bufs with 282252 writes in 65544 ms (avoided 21 new dirty bufs) for db 19:0
average writes per second: 4306.30 writes/sec
average throughput: 46.96 MB/sec, I/O saturation: 53644, context switches 101117
last target outstanding: 639360, avgWriteLatency 1
I was a bit perplexed by this issue, since the system was certainly no slouch — plenty of cores, 3TB of memory, and XtremIO storage. And none of these FlushCache messages were ever paired with the telltale 15 second I/O warnings in the error log. Still, if you stack a bunch of high-transaction databases on there, checkpoint processing can get pretty sluggish. Not so much because of the direct I/O, but more reconciliation that has to be done with a massive number of dirty pages (not just from committed transactions) scattered across such a large amount of memory, and potentially waiting on the lazywriter (since there is only one for the whole instance).
I did some quick "freshen-up" reading of some very valuable posts:
- How do checkpoints work and what gets logged
- Database Checkpoints (SQL Server)
- What does checkpoint do for tempdb?
- A SQL Server DBA myth a day: (15/30) checkpoint only writes pages from committed transactions
- FlushCache messages might not be an actual IO stall
- Indirect Checkpoint and tempdb – the good, the bad and the non-yielding scheduler
- Change the Target Recovery Time of a Database
- How It Works: When is the FlushCache message added to SQL Server Error Log?
- Changes in SQL Server 2016 Checkpoint Behavior
- Target Recovery Interval and Indirect Checkpoint – New Default of 60 Seconds in SQL Server 2016
- SQL 2016 – It Just Runs Faster: Indirect Checkpoint Default
- SQL Server : large RAM and DB Checkpointing
I quickly decided that I wanted to track checkpoint durations for a few of these more troublesome databases, before and after changing their target recovery interval from 0 (the old way) to 60 seconds (the new way). Back in January, I borrowed an Extended Events session from friend and fellow Canadian Hannah Vernon:
CREATE EVENT SESSION CheckpointTracking ON SERVER
ADD EVENT sqlserver.checkpoint_begin
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
, ADD EVENT sqlserver.checkpoint_end
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
ADD TARGET package0.event_file
(
SET filename = N'L:\SQL\CP\CheckPointTracking.xel',
max_file_size = 50, -- MB
max_rollover_files = 50
)
WITH
(
MAX_MEMORY = 4096 KB,
MAX_DISPATCH_LATENCY = 30 SECONDS,
TRACK_CAUSALITY = ON,
STARTUP_STATE = ON
);
GO
ALTER EVENT SESSION CheckpointTracking ON SERVER
STATE = START;I marked the time that I changed each database, and then analyzed the results from the Extended Events data using a query published in the original tip. The results showed that after changing to indirect checkpoints, each database went from checkpoints averaging 30 seconds to checkpoints averaging less than a tenth of a second (and far fewer checkpoints in most cases, too). There's a lot to unpack from this graphic, but this is the raw data I used to present my argument (click to enlarge):
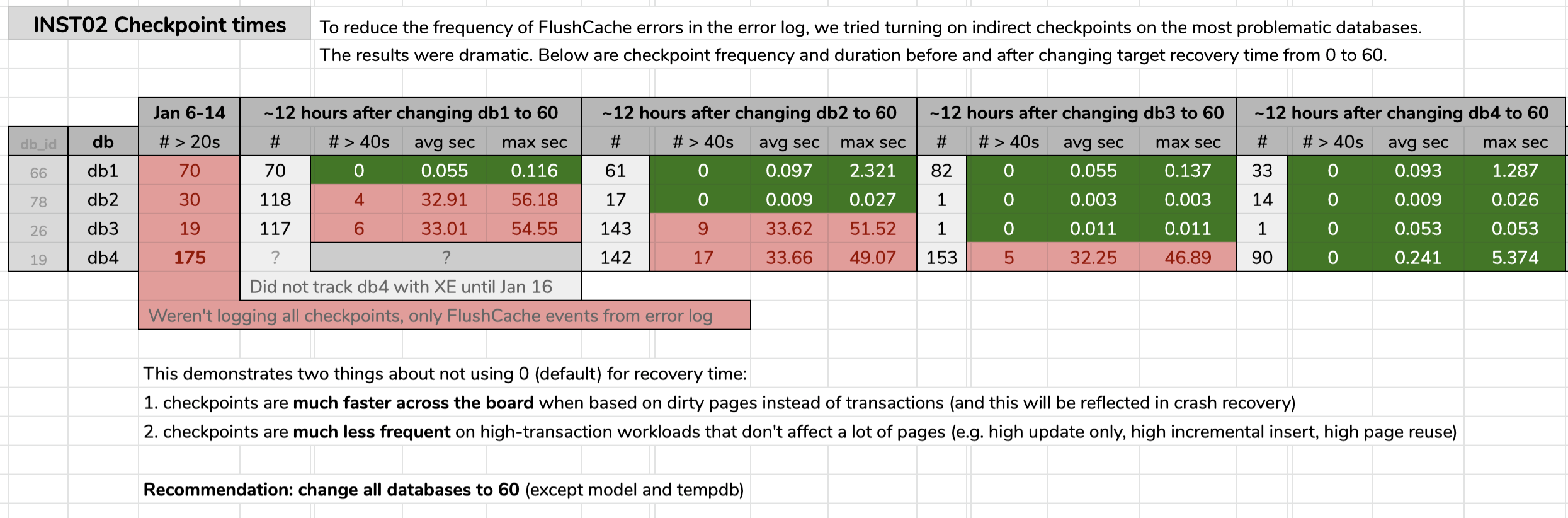 My evidence
My evidence
Once I proved my case across these problematic databases, I got the green light to implement this across all of our user databases throughout our environment. In dev first, and then in production, I ran the following via a CMS query to get a gauge for how many databases we were talking about:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += CASE
WHEN (ag.role = N'PRIMARY' AND ag.ag_status = N'READ_WRITE') OR ag.role IS NULL THEN N'
ALTER DATABASE ' + QUOTENAME(d.name) + N' SET TARGET_RECOVERY_TIME = 60 SECONDS;'
ELSE N'
PRINT N''-- fix ' + QUOTENAME(d.name) + N' on Primary.'';'
END
FROM sys.databases AS d
OUTER APPLY
(
SELECT role = s.role_desc,
ag_status = DATABASEPROPERTYEX(c.database_name, N'Updateability')
FROM sys.dm_hadr_availability_replica_states AS s
INNER JOIN sys.availability_databases_cluster AS c
ON s.group_id = c.group_id
AND d.name = c.database_name
WHERE s.is_local = 1
) AS ag
WHERE d.target_recovery_time_in_seconds <> 60
AND d.database_id > 4
AND d.[state] = 0
AND d.is_in_standby = 0
AND d.is_read_only = 0;
SELECT DatabaseCount = @@ROWCOUNT, Version = @@VERSION, cmd = @sql;
--EXEC sys.sp_executesql @sql;Some notes about the query:
database_id > 4
I didn't want to touchmasterat all, and I didn't want to changetempdbyet because we're not on the latest SQL Server 2017 CU (see KB #4497928 for one reason that detail is important). The latter rules outmodel, too, because changing model would affecttempdbon the next failover / restart. I could have changedmsdb, and I may go back to do that at some point, but my focus here was on user databases.
[state] / is_read_only / is_in_standby
We need to make sure the databases we're trying to change are online and not read only (I hit one that was currently set to read only, and will have to come back to that one later).
OUTER APPLY (...)
We want to restrict our actions to databases that are either the primary in an AG or not in an AG at all (and also have to account for distributed AGs, where we can be primary and local but still not be writable). If you happen to run the check on a secondary, you can't fix the issue there, but you should still get a warning about it. Thanks to Erik Darling for helping with this logic, and Taylor Martell for motivating improvements.
- If you have instances running older versions like SQL Server 2008 R2 (I found one!), you'll have to tweak this a little bit, since the
target_recovery_time_in_secondscolumn doesn't exist there. I had to use dynamic SQL to get around this in one case, but you could also temporarily move or remove where those instances fall in your CMS hierarchy. You could also not be lazy like me, and run the code in Powershell instead of a CMS query window, where you could easily filter out databases given any number of properties before ever hitting compile-time issues.
In production, there were 102 instances (about half) and 1,590 total databases using the old setting. Everything was on SQL Server 2017, so why was this setting so prevalent? Because they were created before indirect checkpoints became the default in SQL Server 2016. Here is a sample of the results:
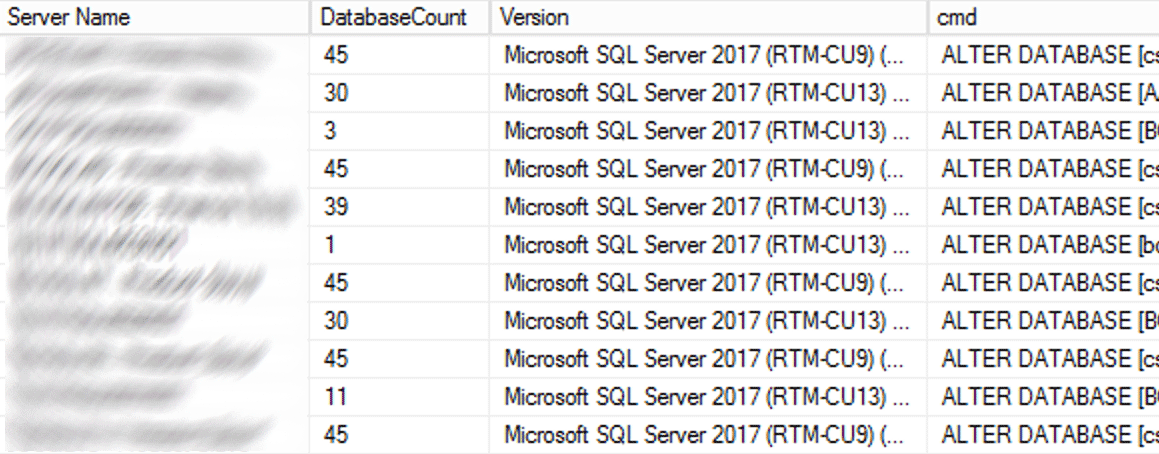 Partial results from CMS query.
Partial results from CMS query.
Then I ran the CMS query again, this time with sys.sp_executesql uncommented. It took about 12 minutes to run that across all 1,590 databases. Within the hour, I was already getting reports of people observing a significant drop in CPU on some of the busier instances.
I still have more to do. For example, I need to test out the potential impact on tempdb, and whether there is any weight in our use case to the horror stories I've heard. And we need to make sure that the 60 second setting is part of our automation and all database creation requests, especially those that are scripted or restored from backups.
4 thoughts on “"0 to 60" : Switching to indirect checkpoints”
Comments are closed.

Why should we leave model DB to 0. Why not set the model DB to 60 as well and If you would like to disable indirect checkpoint on tempdb you can add TF 3468 to the startup parameters of your SQL Server instance.
Dev, it was a choice, like any other. You can make your own decision; these are the criteria I used. While setting model to 60 would ensure new databases inherit the new setting:
If you have different priorities, cool, set model to 60 and use the trace flag. I was merely explaining what I did in my case.
Thanks for the clarification. We have seen benefit on setting the model to 60 every new databases, except tempdb, so we chose to enable at the model db, so we don't have to keep checking for the new databases. But we have seen a drastic poor performance at the tempdb, so we have enabled TF 3468. Moreover, we set all DB properties we require at the model DB and rely on that heavily. Yes I agree, it is a choice based on the requirements.
Thanks for this! I had been getting those messages in the error log, and didn't know they were related to checkpointing. I captured the xevents for a day before the change, and went from 1000 seconds/hour across all DBs on one of my servers, to 10 seconds/hour.