
Strongly Type Those Table-Valued Parameters
Table-valued parameters have been around since SQL Server 2008 and provide a useful mechanism for sending multiple rows of data to SQL Server, brought together as a single parameterized call. Any rows are then available in a table variable which can then be used in standard T-SQL coding, which eliminates the need to write specialized processing logic for breaking the data down again. By their very definition, table-valued parameters are strongly-typed to a user-defined table type that must exist within the database where the call is being made. However, strongly-typed isn’t really strictly “strongly-typed” as you would expect, as this article is going to demonstrate, and performance could be impacted as a result.
To demonstrate the potential performance impacts of incorrectly typed table-valued parameters with SQL Server, we are going to create an example user-defined table type with the following structure:
CREATE TYPE dbo.PharmacyData AS TABLE
(
Dosage int,
Drug varchar(20),
FirstName varchar(50),
LastName varchar(50),
AddressLine1 varchar(250),
PhoneNumber varchar(50),
CellNumber varchar(50),
EmailAddress varchar(100),
FillDate datetime
);Then we will need a .NET application that is going to use this user-defined table type as an input parameter for passing data into SQL Server. To use a table-valued parameter from our application, a DataTable object is typically populated and then passed as the value for the parameter with a type of SqlDbType.Structured. The DataTable can be created multiple ways in the .NET code, but a common way to create the table is something like the following:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData");
DefaultTable.Columns.Add("Dosage", typeof(int));
DefaultTable.Columns.Add("Drug", typeof(string));
DefaultTable.Columns.Add("FirstName", typeof(string));
DefaultTable.Columns.Add("LastName", typeof(string));
DefaultTable.Columns.Add("AddressLine1", typeof(string));
DefaultTable.Columns.Add("PhoneNumber", typeof(string));
DefaultTable.Columns.Add("CellNumber", typeof(string));
DefaultTable.Columns.Add("EmailAddress", typeof(string));
DefaultTable.Columns.Add("Date", typeof(DateTime));You can also create the DataTable using the inline definition as follows:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{"Dosage", typeof(int)},
{"Drug", typeof(string)},
{"FirstName", typeof(string)},
{"LastName", typeof(string)},
{"AddressLine1", typeof(string)},
{"PhoneNumber", typeof(string)},
{"CellNumber", typeof(string)},
{"EmailAddress", typeof(string)},
{"Date", typeof(DateTime)},
},
Locale = CultureInfo.InvariantCulture
};Either of these definitions of the DataTable object in .NET can be used as a table-valued parameter for the user-defined data type that was created, but take notice of the typeof(string) definition for the various string columns; these may all be “properly” typed but they aren’t actually strongly-typed to the data types implemented in the user-defined data type. We can populate the table with random data and pass it to SQL Server as a parameter to a very simple SELECT statement that is going to return back the exact same rows as the table that we passed in, as follows:
using (SqlCommand cmd = new SqlCommand("SELECT * FROM @tvp;", connection))
{
var pList = new SqlParameter("@tvp", SqlDbType.Structured);
pList.TypeName = "dbo.PharmacyData";
pList.Value = DefaultTable;
cmd.Parameters.Add(pList);
cmd.ExecuteReader().Dispose();
}We can then use a debug break so we can inspect the definition of DefaultTable during execution, as show below:
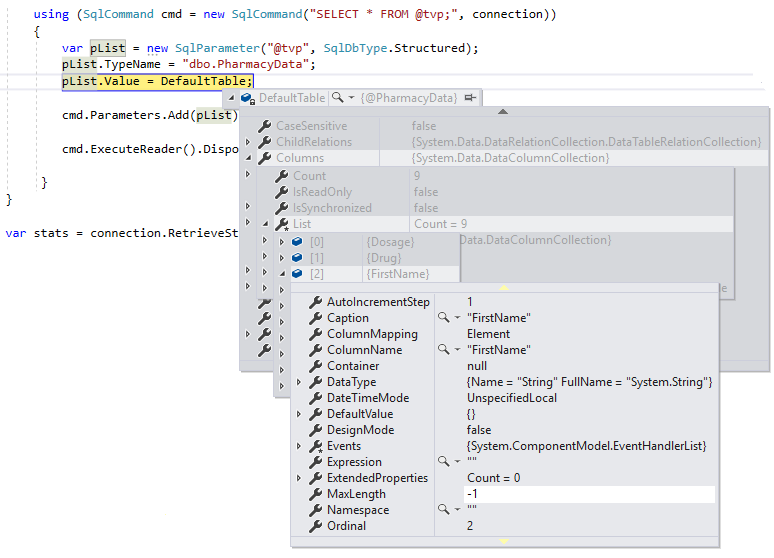
We can see that the MaxLength for the string columns is set at -1, meaning they are being passed over TDS to SQL Server as LOBs (Large Objects) or essentially as MAX datatyped columns, and this can impact performance in a negative manner. If we change the .NET DataTable definition to be strongly-typed to the schema definition of the user-defined table type as follows and look at the MaxLength of the same column using a debug break:
System.Data.DataTable SchemaTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{new DataColumn() { ColumnName = "Dosage", DataType = typeof(int)} },
{new DataColumn() { ColumnName = "Drug", DataType = typeof(string), MaxLength = 20} },
{new DataColumn() { ColumnName = "FirstName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "LastName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "AddressLine1", DataType = typeof(string), MaxLength = 250} },
{new DataColumn() { ColumnName = "PhoneNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "CellNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "EmailAddress", DataType = typeof(string), MaxLength = 100} },
{new DataColumn() { ColumnName = "Date", DataType = typeof(DateTime)} },
},
Locale = CultureInfo.InvariantCulture
};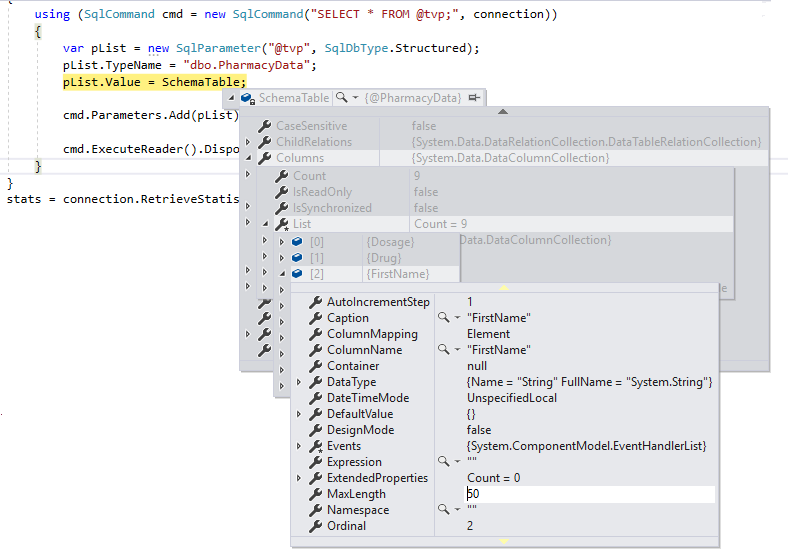
We now have correct lengths for the column definitions, and we won’t be passing them as LOBs over TDS to SQL Server.
How does this impact performance you may wonder? It affects the number of TDS buffers that are sent across the network to SQL Server, and it also impacts the overall processing time for the commands.
Using the exact same data set for the two data tables, and leveraging the RetrieveStatistics method on the SqlConnection object allows us to get the ExecutionTime and BuffersSent statistics metrics for the calls to the same SELECT command, and just using the two different DataTable definitions as parameters and calling the SqlConnection object’s ResetStatistics method allows the execution stats to be cleared between tests.
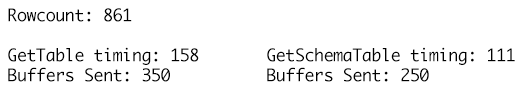
The GetSchemaTable definition specifies the MaxLength for each of the string columns correctly where GetTable just adds columns of type string that have a MaxLength value set to -1 resulting in 100 additional TDS buffers being sent for 861 rows of data in the table and a runtime of 158 milliseconds compared to only 250 buffers being sent for the strongly-typed DataTable definition and a run time of 111 milliseconds. While this might not seem like much in the grand scheme of things, this is a single call, single execution, and the accumulated impact over time for many thousands or millions of such executions is where the benefits begin to add up and have a noticeable impact on workload performance and throughput.
Where this really can make a difference is in cloud implementations where you are paying for more than just compute and storage resources. In addition to having the fixed costs of hardware resources for Azure VM, SQL Database, or AWS EC2 or RDS, there is an added cost for network traffic to and from the cloud that is tacked on to the billing for each month. Reducing the buffers going across the wire will lower the TCO for the solution over time, and the code changes required to implement this savings are relatively simple.
4 thoughts on “Strongly Type Those Table-Valued Parameters”
Comments are closed.

Interestingly enough, to avoid conversion for varchar you need to use SqlDataRecord, not a DataTable, and you also need to set a primary key (if applicable) to avoid a sort. Also SqlDataRecord can stream without buffering, unlike DataTable. But it is more coding work for little gain on small datasets.
Sommarskog points all this out in his famous article:
http://www.sommarskog.se/arrays-in-sql-2008.html
in section 5.
Should numeric/decimal data types Decimal include precision & scale? We're dealing with $$ amounts at scale numeric(38,4)
(Not the author, but) I believe precision / scale / length etc. for any variable length types should just always be specified, as a best practice.
I can add those to a test and rerun it pretty quickly and give you numbers that would reflect if there is a significant TDS buffer difference in the packets sent for different sizes but the default wouldn't be as bad as a LOB string being passed due to limits on how large those types can be.