
Improve Performance of UDFs with NULL ON NULL INPUT
At PASS Summit a few weeks ago, Microsoft released CTP2.1 of SQL Server 2019, and one of the big feature enhancements that is included in the CTP is Scalar UDF Inlining. Prior to this release I wanted to play around with the performance difference between the inlining of scalar UDFs and the RBAR (row-by-agonizing-row) execution of scalar UDFs in earlier versions of SQL Server and I happened upon a syntax option for the CREATE FUNCTION statement in the SQL Server Books Online that I had never seen before.
The DDL for CREATE FUNCTION supports a WITH clause for function options and while reading the Books Online I noticed that the syntax included the following:
-- Transact-SQL Function Clauses
<function_option>::=
{
[ ENCRYPTION ]
| [ SCHEMABINDING ]
| [ RETURNS NULL ON NULL INPUT | CALLED ON NULL INPUT ]
| [ EXECUTE_AS_Clause ]
}I was really curious about the RETURNS NULL ON NULL INPUT function option so I decided to do some testing. I was very surprised to find out that it’s actually a form of scalar UDF optimization that has been in the product since at least SQL Server 2008 R2.
It turns out that if you know that a scalar UDF will always return a NULL result when a NULL input is provided then the UDF should ALWAYS be created with the RETURNS NULL ON NULL INPUT option, because then SQL Server doesn’t even run the function definition at all for any rows where the input is NULL – short-circuiting it in effect and avoiding the wasted execution of the function body.
To show you this behavior, I am going to use a SQL Server 2017 instance with the latest Cumulative Update applied to it and the AdventureWorks2017 database from GitHub (you can download it from here) which ships with a dbo.ufnLeadingZeros function that simply adds leading zeros to the input value and returns an eight character string which includes those leading zeros. I am going to create a new version of that function that includes the RETURNS NULL ON NULL INPUT option so I can compare it against the original function for execution performance.
USE [AdventureWorks2017];
GO
CREATE FUNCTION [dbo].[ufnLeadingZeros_new](
@Value int
)
RETURNS varchar(8)
WITH SCHEMABINDING, RETURNS NULL ON NULL INPUT
AS
BEGIN
DECLARE @ReturnValue varchar(8);
SET @ReturnValue = CONVERT(varchar(8), @Value);
SET @ReturnValue = REPLICATE('0', 8 - DATALENGTH(@ReturnValue)) + @ReturnValue;
RETURN (@ReturnValue);
END;
GOFor the purposes of testing the execution performance differences within the database engine of the two functions, I decided to create an Extended Events session on the server to track the sqlserver.module_end event, which fires at the end of each execution of the scalar UDF for each row. This let me demonstrate the row-by-row processing semantics, and also let me track how many times the function was actually invoked during the test. I decided to also collect the sql_batch_completed and sql_statement_completed events and filter everything by session_id to make sure that I was only capturing information related to the session I was actually running the tests on (if you want to replicate these results, you’ll need to change the 74 in all places in the code below to whatever session ID your test code will be running in). The event session is using TRACK_CAUSALITY so that it is easy to count how many executions of the function occurred through the activity_id.seq_no value for the events (which increases by one for each event that satisfies the session_id filter).
CREATE EVENT SESSION [Session72] ON SERVER
ADD EVENT sqlserver.module_end(
WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))),
ADD EVENT sqlserver.sql_batch_completed(
WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))),
ADD EVENT sqlserver.sql_batch_starting(
WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))),
ADD EVENT sqlserver.sql_statement_completed(
WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))),
ADD EVENT sqlserver.sql_statement_starting(
WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74))))
WITH (TRACK_CAUSALITY=ON)
GOOnce I started the event session and opened the Live Data Viewer in Management Studio, I ran two queries; one using the original version of the function to pad zeros to the CurrencyRateID column in the Sales.SalesOrderHeader table, and the new function to produce the identical output but using the RETURNS NULL ON NULL INPUT option, and I captured the Actual Execution Plan information for comparison.
SELECT SalesOrderID, dbo.ufnLeadingZeros(CurrencyRateID)
FROM Sales.SalesOrderHeader;
GO
SELECT SalesOrderID, dbo.ufnLeadingZeros_new(CurrencyRateID)
FROM Sales.SalesOrderHeader;
GOReviewing the Extended Events data showed a couple of interesting things. First, the original function ran 31,465 times (from the count of module_end events) and the total CPU time for the sql_statement_completed event was 204ms with 482ms of duration.
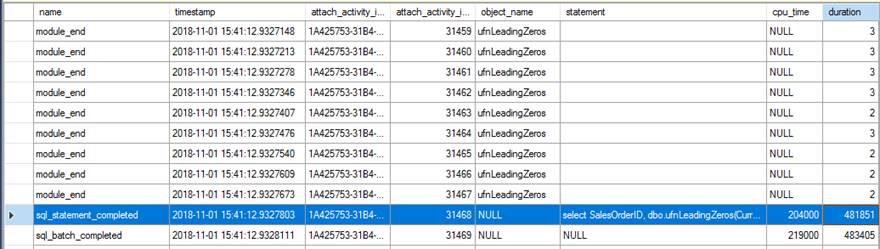
The new version with the RETURNS NULL ON NULL INPUT option specified only ran 13,976 times (again, from the count of module_end events) and the CPU time for the sql_statement_completed event was 78ms with 359ms of duration.

I found this interesting so to verify the execution counts I ran the following query to count NOT NULL value rows, NULL value rows, and total rows in the Sales.SalesOrderHeader table.
SELECT SUM(CASE WHEN CurrencyRateID IS NOT NULL THEN 1 ELSE 0 END) AS NOTNULL,
SUM(CASE WHEN CurrencyRateID IS NULL THEN 1 ELSE 0 END) AS NULLVALUE,
COUNT(*)
FROM Sales.SalesOrderHeader;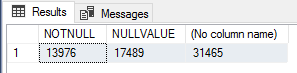
These numbers correspond exactly to the number of module_end events for each of the tests, so this is definitely a very simple performance optimization for scalar UDFs that should be used if you know that the result of the function will be NULL if the input values are NULL, to short-circuit/bypass function execution entirely for those rows.
The QueryTimeStats information in the Actual Execution Plans also reflected the performance gains:
<QueryTimeStats CpuTime="204" ElapsedTime="482" UdfCpuTime="160" UdfElapsedTime="218" />
<QueryTimeStats CpuTime="78" ElapsedTime="359" UdfCpuTime="52" UdfElapsedTime="64" />This is quite a significant reduction in CPU time alone, which can be a significant pain point for some systems.
The usage of scalar UDFs is a well-known design anti-pattern for performance and there are a variety of methods for rewriting the code to avoid their use and performance hit. But if they’re already in place and can’t easily be changed or removed, simply recreating the UDF with the RETURNS NULL ON NULL INPUT option could be a very simple way to enhance performance if there are a lot of NULL inputs across the data set where the UDF is used.
1 thought on “Improve Performance of UDFs with NULL ON NULL INPUT”
Comments are closed.
Just for the record, one of the principles we followed when designing SQL was that "nulls propagate", so returning nulls on null input is the most likely, most expected behavior of the construct in this language.