
Migrating from AnswerHub to WordPress : A Tale of 10 Technologies
We recently launched a new support site, where you can ask questions, submit product feedback or feature requests, or open support tickets. Part of the goal was to centralize all of the places where we were offering assistance to the community. This included the SQLPerformance.com Q&A site, where Paul White, Hugo Kornelis, and many others have been helping solve your most complicated query tuning and execution plan questions, going all the way back to February 2013. I tell you with mixed feelings that the Q&A site has been shut down.
There's an upside, though. You can now ask those tough questions at the new support forum. If you're looking for the old content, well, it's still there, but it looks a little different. For a variety of reasons I won't get into today, once we decided to sunset the original Q&A site, we ultimately decided to simply host all of the existing content on a read-only WordPress site, rather than migrate it into the back end of the new site.
This post isn't about the reasons behind that decision.
I felt really bad about how quickly the answers site had to come offline, the DNS switched, and the content migrated. Since a warning banner was implemented on the site but AnswerHub didn't actually make it visible, this was a shock to many users. So I wanted to make sure I properly kept as much of the content as I could, and I wanted it to be right. This post is here because I thought it would be interesting to talk about the actual process, how many different pieces of technology were involved with pulling it off, and to show off the result. I don't expect any of you to benefit from this end-to-end, as this is a relatively obscure migration path, but more as an example of tying a bunch of technologies together to accomplish a task. It also serves as a good reminder to myself that many things don't end up being as easy as they sound before you start.
The TL;DR is this: I spent a bunch of time and effort making the archived content look good, though I am still trying to recover the last few posts that came in toward the end. I used these technologies:
- Perl
- SQL Server
- PowerShell
- Transmit (FTP)
- HTML
- CSS
- C#
- MarkdownSharp
- phpMyAdmin
- MySQL
Hence the title. If you want a big chunk of the gory details, here they are. If you have any questions or feedback, please reach out or comment below.
AnswerHub provided a 665 MB dump file from the MySQL database that hosted the Q&A content. Every editor I tried choked on it, so I first had to break it up into a file per table using this handy Perl script from Jared Cheney. The tables I needed were called network11_nodes (questions, answers, and comments), network11_authoritables (users), and network11_managed_files (all attachments, including plan uploads):
perl extract_sql.pl -t network11_authoritables -r dump.sql >> users.sql
perl extract_sql.pl -t network11_managed_files -r dump.sql >> files.sql
Now those were not extremely fast to load in SSMS, but at least there I could use Ctrl+H to change (for example) this:
CREATE TABLE `network11_managed_files` (
`c_id` bigint(20) NOT NULL,
...
);
INSERT INTO `network11_managed_files` (`c_id`, ...) VALUES (1, ...);To this:
CREATE TABLE dbo.files
(
c_id bigint NOT NULL,
...
);
INSERT dbo.files (c_id, ...) VALUES (1, ...);Then I could load the data into SQL Server so I could manipulate it. And believe me, I manipulated it.
Next, I had to retrieve all of the attachments. See, the MySQL dump file I got from the vendor contained a gazillion INSERT statements, but none of the actual plan files that users had uploaded — the database only had the relative paths to the files. I used T-SQL to build a series of PowerShell commands that would call Invoke-WebRequest to retrieve all the files and store them locally (many ways to skin this cat, but this was drop dead easy). From this:
SELECT 'Invoke-WebRequest -Uri '
+ '"$($url)' + RTRIM(c_id) + '-' + c_name + '"'
+ ' -OutFile "E:\s\temp\' + RTRIM(c_id) + '-' + c_name + '";'
FROM dbo.files
WHERE LOWER(c_mime_type) LIKE 'application/%';That yielded this set of commands (along with a pre-command to resolve this TLS issue); the whole thing ran pretty quickly, but I don't recommend this approach for any combination of {massive set of files} and/or {low bandwidth}:
$AllProtocols = [System.Net.SecurityProtocolType]'Ssl3,Tls,Tls11,Tls12';
[System.Net.ServicePointManager]::SecurityProtocol = $AllProtocols;
$u = "https://answers.sqlperformance.com/s/temp/";
Invoke-WebRequest -Uri "$($u)/1-proc.pesession" -OutFile "E:\s\temp\1-proc.pesession";
Invoke-WebRequest -Uri "$($u)/14-test.pesession" -OutFile "E:\s\temp\14-test.pesession";
Invoke-WebRequest -Uri "$($u)/15-a.QueryAnalysis" -OutFile "E:\s\temp\15-a.QueryAnalysis";
...This downloaded almost all of the attachments but, admittedly, some were missed due to errors on the old site when they were initially uploaded. So, on the new site, you may occasionally see a reference to an attachment that doesn't exist.
Then I used Panic Transmit 5 to upload the temp folder to the new site, and now when the content gets uploaded, links to /s/temp/1-proc.pesession will continue to work.
Next, I moved on to SSL. In order to request a certificate on the new WordPress site, we had to update the DNS for answers.sqlperformance.com to point at the CNAME over at our WordPress host, WPEngine. It was kind of chicken and egg here — we had to suffer some downtime for https URLs, which would fail for no certificate on the new site. This was okay because the certificate on the old site had expired, so really, we were no worse off. I also had to wait to do this until I had downloaded all of the files from the old site, because once DNS flipped over, there would be no way to get to them except through some back door.
While I was waiting for DNS to propagate, I started working on the logic to pull all of the questions, answers, and comments into something consumable in WordPress. Not only were the table schemas different from WordPress, the types of entities are also quite different. My vision was to combine each question — and any answers and/or comments — into a single post.
The tricky part is that the nodes table just contains all of the three content types in the same table, with parent and original ("master") parent references. Their front-end code likely uses some kind of cursor to step through and display the content in a hierarchical and chronological order. I wouldn't have that luxury in WordPress, so I had to string the HTML together in one shot. Just as an example, here is what the data looked like:
SELECT c_type, c_id, c_parent, oParent = c_originalParent, c_creation_date, c_title
FROM dbo.nodes
WHERE c_originalParent = 285;
/*
c_type c_id c_parent oParent c_creation_date accepted c_title
---------- ------ -------- ------- ---------------- -------- -------------------------
question 285 NULL 285 2013-02-13 16:30 why is the MERGE JOIN ...
answer 287 285 285 2013-02-14 01:15 1 NULL
comment 289 285 285 2013-02-14 13:35 NULL
answer 293 285 285 2013-02-14 18:22 NULL
comment 294 287 285 2013-02-14 18:29 NULL
comment 298 285 285 2013-02-14 20:40 NULL
comment 299 298 285 2013-02-14 18:29 NULL
*/
I couldn't order by id, or type, or by parent, since sometimes a comment would come later on an earlier answer, the first answer wouldn't always be the accepted answer, and so on. I wanted this output (where ++ represents one level of indent):
/*
c_type c_id c_parent oParent c_creation_date reason
---------- ------ -------- ------- ---------------- -------------------------
question 285 NULL 285 2013-02-13 16:30 question is ALWAYS first
++comment 289 285 285 2013-02-14 13:35 comments on the question before answers
answer 287 285 285 2013-02-14 01:15 first answer (accepted = 1)
++comment 294 287 285 2013-02-14 18:29 first comment on first answer
++comment 298 287 285 2013-02-14 20:40 second comment on first answer
++++comment 299 298 285 2013-02-14 18:29 reply to second comment on first answer
answer 293 285 285 2013-02-14 18:22 second answer
*/I started writing a recursive CTE and,
DECLARE @foo TABLE
(
c_type varchar(255),
c_id int,
c_parent int,
oParent int,
accepted bit
);
INSERT @foo(c_type, c_id, c_parent, oParent, accepted) VALUES
('question', 285, NULL, 285, 0),
('answer', 287, 285 , 285, 1),
('comment', 289, 285 , 285, 0),
('comment', 294, 287 , 285, 0),
('comment', 298, 287 , 285, 0),
('comment', 299, 298 , 285, 0),
('answer', 293, 285 , 285, 0);
;WITH cte AS
(
SELECT
lvl = 0,
f.c_type,
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f WHERE f.c_parent IS NULL
UNION ALL
SELECT
lvl = c.lvl + 1,
c_type = CONVERT(varchar(255), CASE
WHEN f.accepted = 1 THEN 'accepted answer'
WHEN f.c_type = 'comment' THEN c.c_type + ' ' + f.c_type
ELSE f.c_type
END),
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),c.Sort + RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f INNER JOIN cte AS c ON c.c_id = f.c_parent
)
SELECT lvl = CASE lvl WHEN 0 THEN 1 ELSE lvl END, c_type, c_id, c_parent, oParent, Sort
FROM cte
ORDER BY
oParent,
CASE
WHEN c_type LIKE 'question%' THEN 1 -- it's a question *or* a comment on the question
WHEN c_type LIKE 'accepted answer%' THEN 2 -- accepted answer *or* comment on accepted answer
ELSE 3 END,
Sort;Results:
/*
lvl c_type c_id c_parent oParent Sort
---- --------------------------------- ----------- ----------- ----------- --------------------
1 question 285 NULL 285 00285
1 question comment 289 285 285 0028500289
1 accepted answer 287 285 285 0028500287
2 accepted answer comment 294 287 285 002850028700294
2 accepted answer comment 298 287 285 002850028700298
3 accepted answer comment comment 299 298 285 00285002870029800299
1 answer 293 285 285 0028500293
*/Genius. I spot checked a dozen or so others, and was glad to be moving on to the next step. I've thanked Andy profusely, several times, but let me do it again: Thanks Andy!
Now that I could return the whole set in the order I liked, I had to perform some manipulation of the output to apply HTML elements and class names that would let me mark questions, answers, comments, and indentation in a meaningful way. The end goal was output that looked like this (and keep in mind, this is one of the simpler cases):
<div class="question">
<span class="authorq" title=" Author : author name ">
<i class="fas fa-user"></i>Author name</span>
<span class="createdq" title=" February 13th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-13 16:30:36</span>
<div class=mainbodyq>I don't understand why the merge operator is passing over 4million
rows to the hash match operator when there is only 41K and 19K from other operators.
<div class=attach><i class="fas fa-file"></i>
<a target="_blank" href="/s/temp/254-tmp4DA0.queryanalysis" rel="noopener noreferrer">
/s/temp/254-tmp4DA0.queryanalysis</a>
</div>
</div>
<div class="comment indent1 ">
<div class=linecomment>
<span class="authorc" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createdc" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 13:35:39</span>
</div>
<div class=mainbodyc>
I am still trying to understand the significant amount of rows from the MERGE operator.
Unless it's a result of a Cartesian product from the two inputs then finally the WHERE
predicate is applied to filter out the unmatched rows leaving the 4 million row count.
</div>
</div>
<div class="answer indent1 [accepted]">
<div class=lineanswer>
<span class="authora" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createda" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 01:15:42</span>
</div>
<div class=mainbodya>
The reason for the large number of rows can be seen in the Plan Explorer tool tip for
the Merge Join operator:
<img decoding="async" src="/s/temp/259-sp.png" alt="Merge Join tool tip" />
...
</div>
</div>
</div>I won't step through the ridiculous number of iterations I had to go through in order to land on a reliable form of that output for all 5,000+ items (which translated to almost 1,000 posts once everything was glued together). On top of that, I needed to generate these in the form of INSERT statements that I could then paste into phpMyAdmin on the WordPress site, which meant adhering to their bizarre syntax diagram. Those statements needed to include other additional information required by WordPress, but not present or accurate in the source data (like post_type). And that admin console would time out given too much data, so I had to chunk it out into ~750 inserts at a time. Here is the procedure I ended up with (this is not really to learn anything specific from, just a demonstration of how much manipulation of the imported data was necessary):
CREATE /* OR ALTER */ PROCEDURE dbo.BuildMySQLInserts
@LowerBound int = 1,
@UpperBound int = 750
AS
BEGIN
SET NOCOUNT ON;
;WITH CTE AS
(
SELECT lvl = 0,
[type] = CONVERT(varchar(100),f.[type]),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
WHERE f.type = 'question'
AND master_parent BETWEEN @LowerBound AND @UpperBound
UNION ALL
SELECT lvl = c.lvl + 1,
CONVERT(varchar(100),CASE
WHEN f.[state] = '[accepted]' THEN 'accepted answer'
WHEN f.type = 'comment' THEN c.type + ' ' + f.type
ELSE f.type
END),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),c.sort + RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
JOIN CTE AS c ON c.id = f.parent
)
SELECT
master_parent,
prefix = CASE WHEN lvl = 0 THEN
CONVERT(varchar(11), master_parent) + ', 3, ''' + created + ''', '''
+ created + ''',''' END,
bodypre = '<div class="' + COALESCE(c_type, RTRIM(LEFT([type],8)))
+ CASE WHEN c_type <> 'question' THEN ' indent' + RTRIM(lvl)
+ COALESCE(' ' + [state], '') ELSE '' END + '">'
+ CASE WHEN c_type <> 'question' THEN
'<div class=line' + c_type + '>' ELSE '' END
+ '<span class="author' + LEFT(c_type, 1) + '" title=" Author : '
+ REPLACE(REPLACE(Fullname,'''','\'''),'"','')
+ ' "><i class="fas fa-user"></i>' + REPLACE(Fullname,'''','\''') --"
+ '</span> <span class="created' + LEFT(c_type,1) + '" title=" '
+ DATENAME(MONTH, c_creation_date) + ' ' + RTRIM(DAY(c_creation_date))
+ CASE
WHEN DAY(c_creation_date) IN (1,21,31) THEN 'st'
WHEN DAY(c_creation_date) IN (2,22) THEN 'nd'
WHEN DAY(c_creation_date) IN (3,23) THEN 'rd' ELSE 'th' END
+ ', ' + RTRIM(YEAR(c_creation_date))
+ ' "><i class="fas fa-calendar-alt"></i>' + created + '</span>'
+ CASE WHEN c_type <> 'question' THEN '</div>' ELSE '' END,
body = '<div class=mainbody' + left(c_type,1) + '>'
+ REPLACE(REPLACE(c_body, char(39), '\' + char(39)), '’', '\' + char(39)),
bodypost = COALESCE(urls, '') + '</div></div>',--'
+ CASE WHEN c_type = 'question' THEN '</div>' ELSE '' END,
suffix = ''',''' + REPLACE(n.c_title, '''', '\''') + ''','''',''publish'',
''closed'',''closed'','''',''' + REPLACE(n.c_plug, '''', '\''')
+ ''','''','''',''' + created + ''',''' + created + ''','''',0,
''https://answers.sqlperformance.com/?p=' + CONVERT(varchar(11), master_parent)
+ ''', 0, ''post'','''',0);',
rn = RTRIM(ROW_NUMBER() OVER (PARTITION BY master_parent
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort)),
c = RTRIM(COUNT(*) OVER (PARTITION BY master_parent))
FROM CTE
LEFT OUTER JOIN dbo.network11_nodes AS n
ON cte.id = n.c_id
LEFT OUTER JOIN dbo.Users AS u
ON n.c_author = u.UserID
LEFT OUTER JOIN
(
SELECT NodeID, urls = STRING_AGG('<div class=attach>
<i class="fas fa-file'
+ CASE WHEN c_mime_type IN ('image/jpeg','image/png')
THEN '-image' ELSE '' END
+ '"></i><a target="_blank" href=' + url + ' rel="noopener noreferrer">' + url + '</a></div>', '\n')
FROM dbo.Attachments
GROUP BY NodeID
) AS a
ON n.c_id = a.NodeID
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort;
END
GOThe output from that is not complete and not ready to stuff into WordPress just yet:
 Sample output (click to enlarge)
Sample output (click to enlarge)
I would need some additional help from C# to turn the actual content (including markdown) into HTML and CSS that I could control better, and write the output (a bunch of INSERT statements that happened to include a bunch of HTML code) to files on the disk I could open and paste into phpMyAdmin. For the HTML, plain text + markdown that started like this:
SELECT something from dbo.sometable;
[1]: https://elsewhere
Would need to become this:
<pre lang="tsql">SELECT something from dbo.sometable;</pre>
To pull this off, I enlisted the help of MarkdownSharp, an open source library originating at Stack Overflow that handles much of the markdown-to-HTML conversion. It was a good fit for my needs, but not perfect; I would still have to perform further manipulation:
- MarkdownSharp doesn't allow for things like
target=_blank, so I would have to inject those myself after processing; - code (anything prefixed with four spaces) inherits <pre><code> wrappers, which I would need to convert to my WP-GeSHi-friendly
<pre lang="tsql">tags, so I would have to replace those as well; - underscores in URLs would be interpreted as italic markdown, so I would have to use the
StrictBoldItalicoption; - carriage returns, single quotes,
<,>, and<p>tags would all prove to present formatting issues, so I would have to deal with all of those at various points of processing.
Again, to avoid all the tedious iterations this took to perfect, the C# code ended up like this:
using System.Text;
using System.Data;
using System.Data.SqlClient;
using MarkdownSharp;
using System.IO;
namespace AnswerHubMigrator
{
class Program
{
static void Main(string[] args)
{
StringBuilder output;
string suffix = "";
string thisfile = "";
// pass two arguments on the command line, e.g. 1, 750
int LowerBound = int.Parse(args[0]);
int UpperBound = int.Parse(args[1]);
// auto-expand URLs, and only accept bold/italic markdown
// when it completely surrounds an entire word
var options = new MarkdownOptions
{
AutoHyperlink = true,
StrictBoldItalic = true
};
MarkdownSharp.Markdown mark = new MarkdownSharp.Markdown(options);
using (var conn = new SqlConnection("Server=.\\SQL2017;Integrated Security=true"))
using (var cmd = new SqlCommand("MigrateDB.dbo.BuildMySQLInserts", conn))
{
cmd.CommandType = CommandType.StoredProcedure;
cmd.Parameters.Add("@LowerBound", SqlDbType.Int).Value = LowerBound;
cmd.Parameters.Add("@UpperBound", SqlDbType.Int).Value = UpperBound;
conn.Open();
using (var reader = cmd.ExecuteReader())
{
// use a StringBuilder to dump output to a file
output = new StringBuilder();
while (reader.Read())
{
// on first pass, make a new delete/insert
// delete is to make the commands idempotent
if (reader["rn"].Equals("1"))
{
// for each master parent, I would create a
// new WordPress post, inheriting the parent ID
output.Append("DELETE FROM `wp_posts` WHERE ID = ");
output.Append(reader["master_parent"].ToString());
output.Append("; INSERT INTO `wp_posts` (`ID`, `post_author`, ");
output.Append("`post_date`, `post_date_gmt`, `post_content`, ");
output.Append("`post_title`, `post_excerpt`, `post_status`, ");
output.Append("`comment_status`, `ping_status`, `post_password`,");
output.Append(" `post_name`, `to_ping`, `pinged`, `post_modified`,");
output.Append(" `post_modified_gmt`, `post_content_filtered`, ");
output.Append("`post_parent`, `guid`, `menu_order`, `post_type`, ");
output.Append("`post_mime_type`, `comment_count`) VALUES (");
// I'm sure some of the above columns are optional, but identifying
// those would not be a valuable use of time IMHO
output.Append(reader["prefix"]);
// hold on to the additional values until last row
suffix = reader["suffix"].ToString();
}
// manipulate the body content to be WordPress and INSERT statement-friendly
string body = reader["body"].ToString().Replace(@"\n", "\n");
body = mark.Transform(body).Replace("href=", "target=_blank href=");
body = body.Replace("", "").Replace("", "");
body = body.Replace("<code>", "");
body = body.Replace("</code></"+"pre>", "</"+"pre>");
body = body.Replace(@"'", "\'").Replace(@"’", "\'");
body = reader["bodypre"].ToString() + body.Replace("\n", @"\n");
body += reader["bodypost"].ToString();
body = body.Replace("<", "<").Replace(">", ">");
output.Append(body);
// if we are on the last row, add additional values from the first row
if (reader["c"].Equals(reader["rn"]))
{
output.Append(suffix);
}
}
thisfile = UpperBound.ToString();
using (StreamWriter w = new StreamWriter(@"C:\wp\" + thisfile + ".sql"))
{
w.WriteLine(output);
w.Flush();
}
}
}
}
}
}Yes, that's an ugly bunch of code, but it finally got me to the set of output that would not make phpMyAdmin puke, and that WordPress would present nicely (enough). I simply called the C# program multiple times with the different parameter ranges:
AnswerHubMigrator 1 750
AnswerHubMigrator 751 1500
AnswerHubMigrator 1501 2250
...Then I opened each of the files, pasted them into phpMyAdmin, and hit GO:
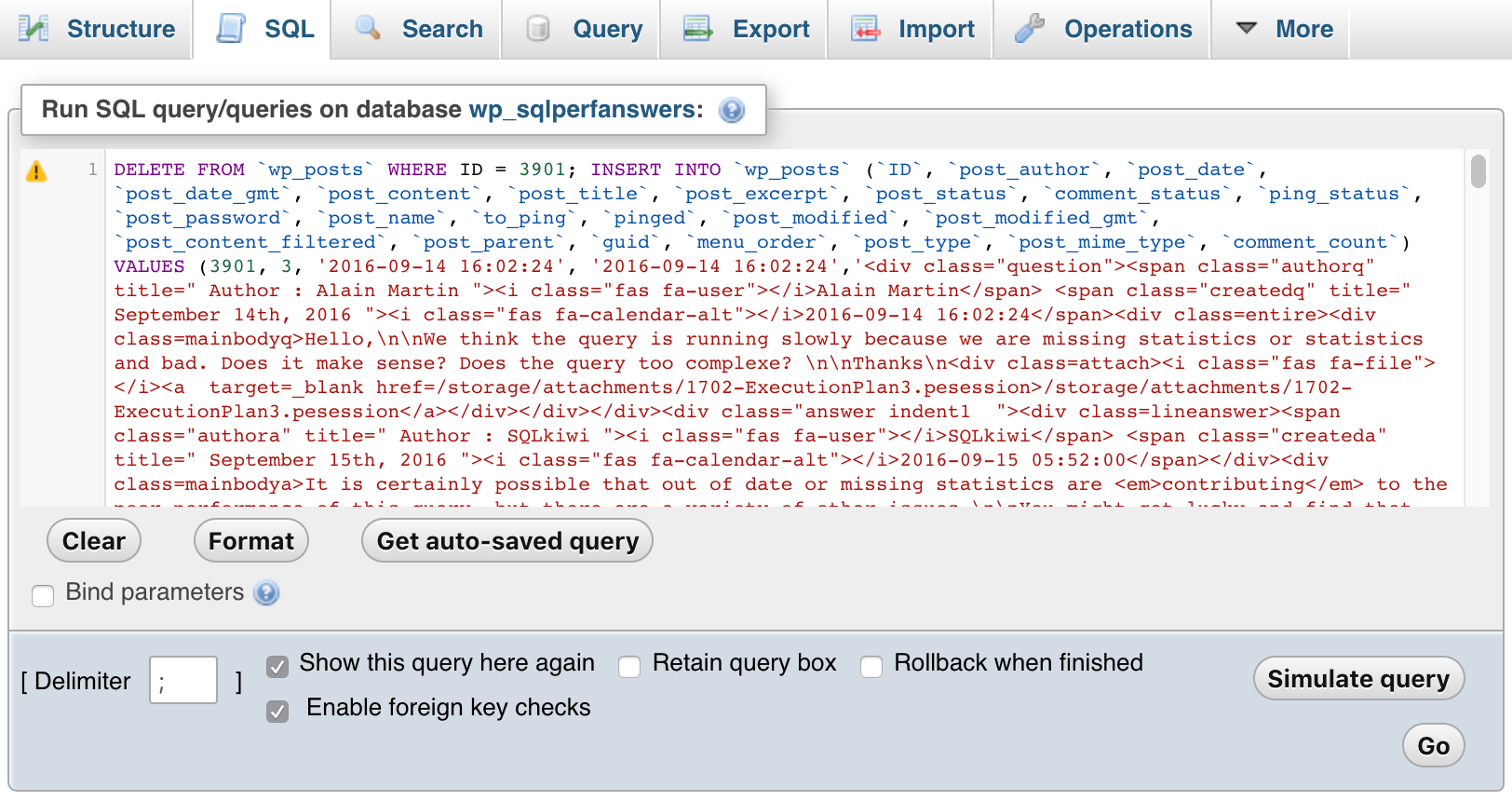 phpMyAdmin (click to enlarge)
phpMyAdmin (click to enlarge)Of course I had to add some CSS within WordPress to help differentiate between questions, comments, and answers, and to also indent comments to show replies to both questions and answers, nest comments replying to comments, and so on. Here is what an excerpt looks like when you drill through to a month's questions:
 Question tile (click to enlarge)
Question tile (click to enlarge)And then an example post, showing embedded images, multiple attachments, nested comments, and an answer:
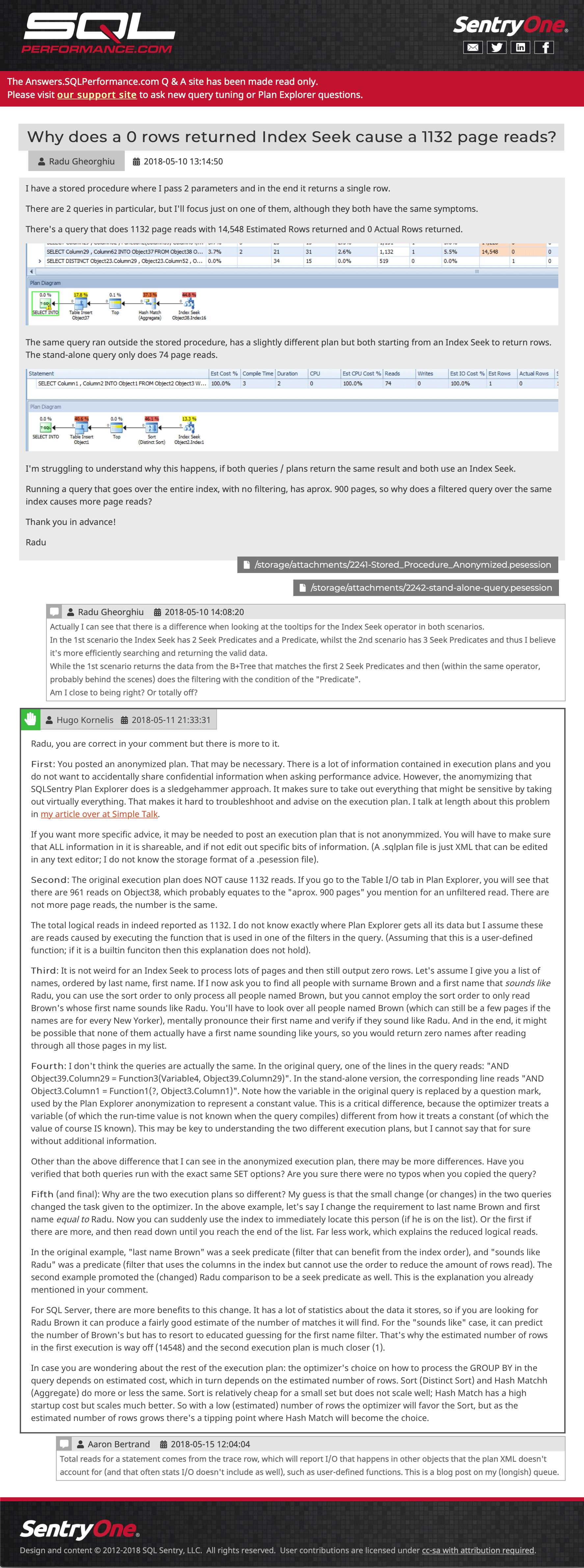 Sample Question and Answer (click to go there)
Sample Question and Answer (click to go there)I am still trying to recover a few posts that were submitted to the site after the last backup was taken, but I welcome you to browse around. Please let us know if you spot anything missing or out of place, or even just to tell us that the content is still useful to you. We do hope to re-introduce plan upload functionality from within Plan Explorer, but it will require some API work on the new support site, so I don't have an ETA for you today.
