
The Importance of Baselines
As a consultant working with SQL Server, many times I’m asked to look at a server that seems like it’s having performance issues. While performing triage on the server, I ask certain questions, such as: what is your normal CPU utilization, what are your average disk latencies, what is your normal memory utilization, and so on. The answer is usually, “we don’t know” or “we aren’t capturing that information regularly.” Not having a recent baseline makes it very difficult to know what abnormal behavior looks like. If you don’t know what normal behavior is, how do you know for sure if things are better or worse? I often use the expressions, “if you aren’t monitoring it, you can’t measure it,” and, “if you aren’t measuring it, you can’t manage it.”
From a monitoring perspective, at a minimum, organizations should be monitoring for failed jobs such as backups, index maintenance, DBCC CHECKDB, and any other jobs of importance. It is easy to set up failure notifications for these; however you also need a process in place to make sure the jobs are running as expected. I’ve seen jobs that get hung and never complete. A failure notification wouldn’t trigger an alarm since the job never succeeds or fails.
From a performance baseline, there are several key metrics that should be captured. I’ve created a process that I use with clients that captures key metrics on a regular basis and stores those values in a user database. My process is simple: a dedicated database with stored procedures that are using common scripts that insert the result sets into tables. I have SQL Agent jobs to run the stored procedures at regular intervals and a cleanup script to purge data older than X days. The metrics I always capture include:
Page Life Expectancy: PLE is probably one of the best ways to gauge if your system is under internal memory pressure. Most systems have PLE values that fluctuate during normal workloads. I like to trend these values to know what the minimum, average, and maximum values are. I like to try to understand what caused PLE to drop during certain times of the day to see if those processes can be tuned. Many times, someone is doing a table scan and flushing the buffer pool. Being able to properly index those queries can help. Just make sure you’re monitoring the right PLE counter – see here.
CPU Utilization: Having a baseline for CPU utilization lets you know if your system is suddenly under CPU pressure. Often when a user complains of performance issues, they’ll observe that CPU looks high. For example, if CPU is hovering around 80% they might find that concerning, however if CPU was also 80% during the same time the previous weeks when no issues were being reported, the likelihood that CPU is the issue is very low. Trending CPU isn’t only for capturing when CPU spikes and stays at a consistently high value. I have numerous stories of when I was brought into a severity one conference bridge because there was an issue with an application. Being the DBA, I wore the hat of “Default Blame Acceptor.” When the application team said there was an issue with the database, it was on me to prove that it wasn’t, the database server was guilty until proven innocent. I vividly recall an incident where the application team was confident that the database server was having issues because users could not connect. They had read on the internet that SQL Server could be suffering from thread pool starvation if it was refusing connections. I jumped on the server and start looking at resources, and what processes were currently running. Within a few minutes I reported back that the server in question was very bored. Based upon our baseline metrics, CPU was typically 60% and it was idle around 20%, page life expectancy was noticeably higher than normal, and there was no locking or blocking happening, I/O looked great, no errors in any logs, and the session counts were about 1/3 of their normal count. I then made the comment, “It appears users are not even reaching the database server.” That got the network folks' attention and they realized that a change they made to the load balancer wasn’t working properly and they determined that over 50% of connections were being routed incorrectly and not making it to the database server. Had I not known what the baseline was, it would have taken us a lot longer to reach the resolution.
Disk I/O: Capturing disk metrics is very important. The DMV sys.dm_io_virtual_file_stats is cumulative since the last server restart. Capturing your I/O latencies over a time interval will give you a baseline of what is normal during that time. Relying on the cumulative value can give you skewed data from after business hour activities or long periods where the system was idle. Paul discussed that here.
Database file sizes: Having an inventory of your databases that includes file size, used size, free space, and more can help you forecast database growth. Often I am asked to forecast how much storage would be needed for a database server over the coming year. Without knowing the weekly or monthly growth trend, I have no way of intelligently coming up with a figure. Once I start tracking these values I can properly trend this. In addition to trending, I could also find when there was unexpected database growth. When I see unexpected growth and investigate, I usually find that someone either duplicated a table to do some testing (yes, in production!) or did some other one-off process. Tracking this type of data, and being able to respond when anomalies occur, helps show that you are proactive and watching over your systems.
Wait statistics: Monitoring wait statistics can help you start figuring out the cause of certain performance issues. Many new DBAs get concerned when they first start researching wait statistics and fail to realize that waits always occur, and that is just the way that SQL Server’s scheduling system works. There are also a lot of waits that can be considered benign, or mostly harmless. Paul Randal excludes these mostly harmless waits in his popular wait statistics script. Paul has also built a vast library of the various wait types and latch classes with descriptions and other information about troubleshooting the waits and latches.
I’ve documented my data collection process, and you can find the code on my blog. Depending on the situation and types of issues a client may be having, I may also want to capture additional metrics. Glenn Berry blogged about a process he put together that captures Average Task Count, Average Runnable Task Count, Average Pending I/O Count, SQL Server process CPU utilization, and Average Page Life Expectancy across all NUMA nodes. A quick internet search will turn up several other data collection processes that people have shared, even the SQL Server Tiger Team has a process that utilizes T-SQL and PowerShell.
Using a custom database and building your own data collection package is a valid solution for capturing a baseline, but most of us are not in the business of building full-on SQL Server monitoring solutions. There is much more that would be helpful to capture, things like long running queries, top queries and stored procedures based on memory, I/O, and CPU, deadlocks, index fragmentation, transactions per second, and much more. For that, I always recommend that clients purchase a third-party monitoring tool. These vendors specialize in staying up to speed on the latest trends and features of SQL Server so that you can focus your time on making sure SQL Server is as stable and fast as possible.
Solutions like SQL Sentry (for SQL Server) and DB Sentry (for Azure SQL Database) capture all these metrics for you, and allow you to easily create different baselines. You can have a normal baseline, month end, quarter end, and more. You can then apply the baseline and see visually how things are different. More importantly, you can configure any number of alerts for various conditions and be notified when metrics exceed your thresholds.
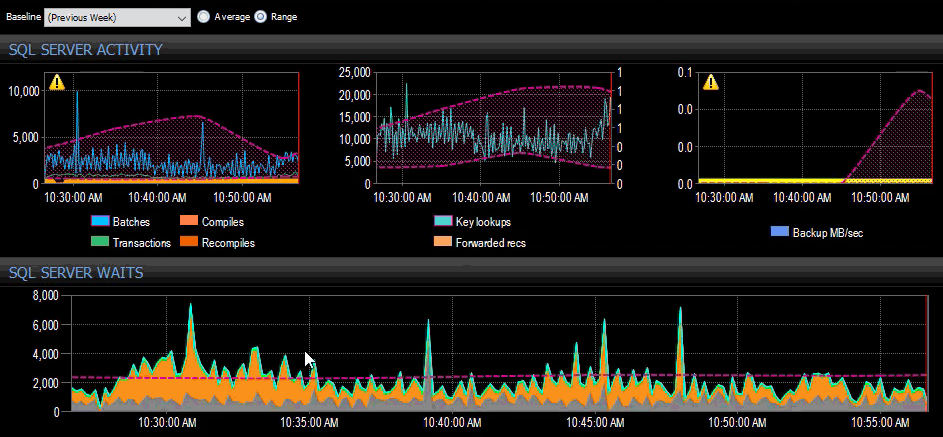 Last week's baseline applied to several SQL Server metrics on the SQL Sentry dashboard.
Last week's baseline applied to several SQL Server metrics on the SQL Sentry dashboard.
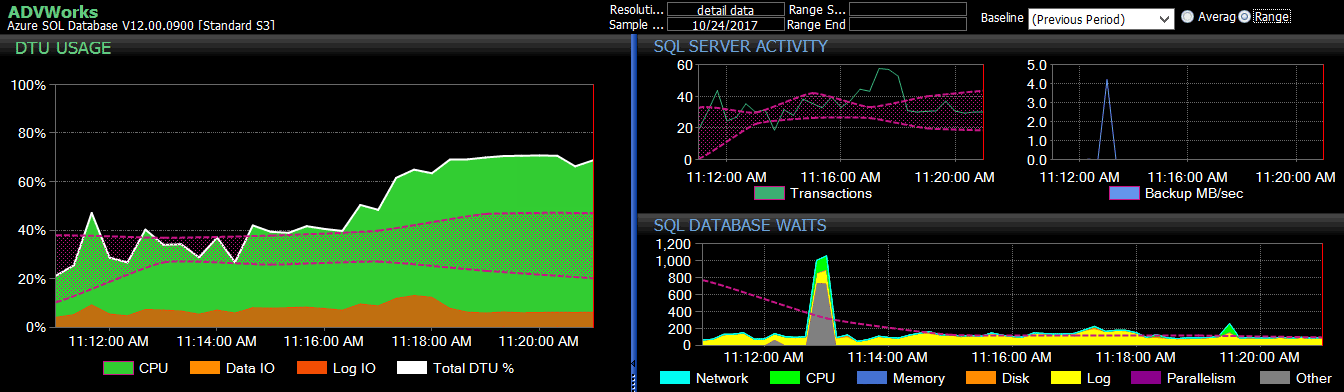 The previous period's baseline applied to several Azure SQL Database metrics on the DB Sentry dashboard.
The previous period's baseline applied to several Azure SQL Database metrics on the DB Sentry dashboard.
For more information on baselines in SentryOne, see these posts over on their team blog, or this 2 Minute Tuesday video. Interested in downloading a trial? They've got you covered there, too.
2 thoughts on “The Importance of Baselines”
Comments are closed.

Can a user have multiple baselines for various times?
In SentryOne? Yes, you can create as many baselines as you like, you can even customize the metrics for any baseline. Greg Gonzalez talks about several of the initial concepts here:
SQL Sentry v8: Baselines from Every Angle