
Automatic Index Management in Azure SQL Database
In February I wrote a blog post about Automatic Plan Correction in SQL Server, and in this post I want to talk about Automatic Index Management, the second component of the Automatic Tuning feature. Automatic Index Management is only available in Azure SQL Database, and it’s not currently on the roadmap to be available in the next release of SQL Server on-premises. This option is enabled independently from Automatic Plan Correction, and as the name implies, it will manage indexes in your database. Specifically, it can create indexes that are missing, and it can remove indexes that are not used, and those that are duplicates. Let’s take a look at how this occurs.
Under the Covers
Automatic Index Management relies on data to make its decision. For potential index creation, it uses information the missing index DMV and tracks it over time and combines that data with an internal model to determine the benefit of the index. It also uses Query Store to determine if the index provides benefit, so it must be enabled for the database, just as with Automatic Plan Correction. With regard to dropping indexes, data from the index usage DMV (sys.dm_db_index_usage_stats) as well as index metadata (e.g. number of columns, column data types) is used.
Enabling Automatic Index Management
As mentioned, Query Store must be enabled for the database. This can be done in SSMS, with T-SQL, and with REST API for Azure SQL Database. Note that Query Store is enabled by default for databases in Azure, and has been since 2016 Q4.
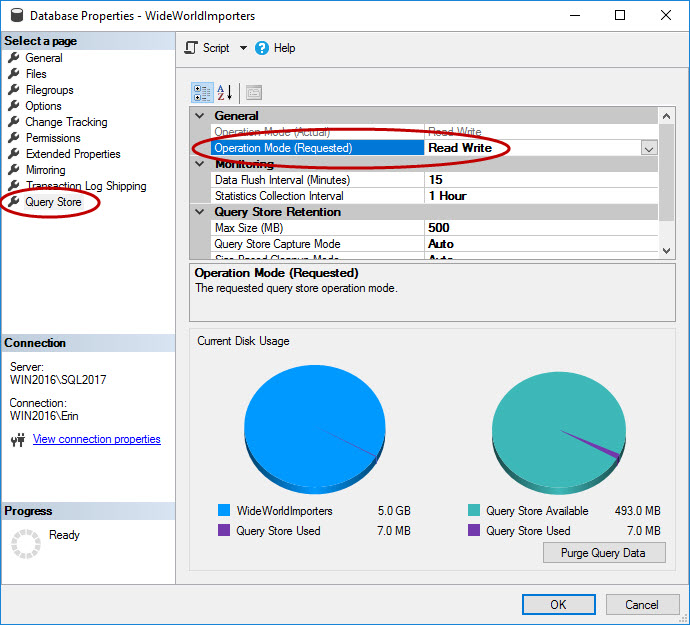
USE [master];
GO
ALTER DATABASE [WideWorldImporters]
SET QUERY_STORE = ON;
GO
ALTER DATABASE [WideWorldImporters]
SET QUERY_STORE (OPERATION_MODE = READ_WRITE);
GOOnce Query Store is enabled, you can use the Azure Portal, T-SQL, or EST API to enable Automatic Index Management in Azure SQL Database (C# and PowerShell are in the works).
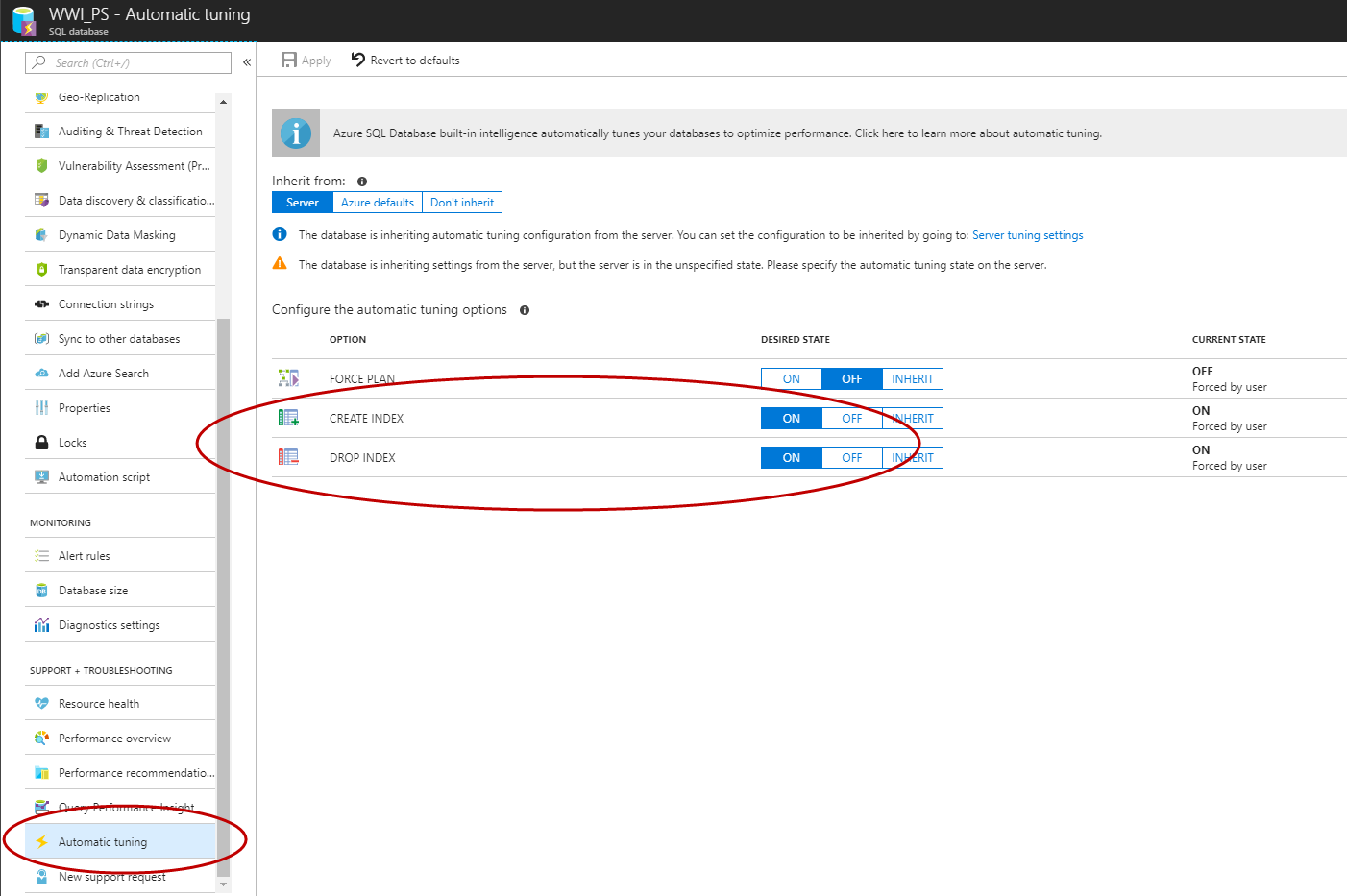
ALTER DATABASE [WWI_PS] SET AUTOMATIC_TUNING (CREATE_INDEX = ON, DROP_INDEX = ON);
GOAutomatic Index Management will be enabled by default for new databases in Azure (https://azure.microsoft.com/en-us/blog/automatic-tuning-will-be-a-new-default/) in the near future. Starting in January of 2018, Microsoft started the roll-out to enable Automatic Tuning for Azure SQL Databases that did not already have it enabled, with notifications sent to administrators so the option can be disabled if desired. This process takes several months, so if you haven’t gotten a notification yet, don’t panic!
How It Works
For index creation there is, presently, a rolling window of seven (7) days* across which the data is tracked, and at a minimum the model needs nine (9) hours* of data to recommend an index, along with 12 hours* of data in Query Store that will be used as a baseline. If it’s determined that an index will provide significant benefit, then SQL Server will create the index.
*These values can change in the future, as the model develops.
Note: at present the model does merge recommendations. That is, if multiple indexes are recommended for a table, but one index can be created to cover all options, it can create that one index currently. However, the model is not currently intelligent enough to merge a recommended index with one that already exists.
Once an index is created, SQL Server verifies that it provides benefit using Query Store (thus is must be enabled for the database). It monitors the performance of any query that uses the new index and compares the CPU of the query before the index was added, and when using the index. If there is a regression in query performance as a result of the index, then it will revert (drop) the index. SQL Server monitors query performance for up to three (3) days, or until 100% of the relevant workload has been analyzed. After that time period, if the index does not show any signs of regression, then it will not review performance for it again.
Understand that if Automatic Index Management create an index, and then two months later your workload changes and it would benefit from that same index automatically created previously but with one additional column, then SQL Server will, at present, create a new index. Currently there is no logic to alter an existing auto-created index, but that functionality is on the roadmap for the feature.
With regard to dropping indexes, if an index has no seeks or scans for 90 days, but does have a maintenance cost (meaning there are inserts, updates, or deletes) then it will be dropped. Duplicate indexes will also be removed, assuming they are an exact duplicate (and the schema is used to determine if indexes are exactly the same). If there are duplicate indexes in terms of key columns and included columns (if relevant) but one or more of them has a filter, then they are not truly duplicate and no indexes will be dropped.
For reference, there are two times as many DROP INDEX recommendations in Azure SQL Database as there are CREATE INDEX recommendations.
When you enable the DROP INDEX option SQL Server will drop user-created indexes. When you enable the CREATE INDEX option, SQL Server has the ability to create indexes automatically and can also drop those indexes (but will not drop user-created indexes). Finally, indexes are created and dropped during times of non-peak workload, as determined by DTU. If the workload is above 80% DTU, then SQL Server will wait to create or drop the index until the system load decreases.
Am I really going to let SQL Server have control?
Maybe. My recommendation on this feature, initially, requires a “trust but verify” approach.
As with Automatic Plan Correction, Automatic Index Management has been developed with a substantial amount of data captured from almost two million Azure SQL Databases. The Automatic Index Management feature has been available in Azure SQL Database since Q1 of 2016, as part of Index Advisor.
The algorithms used by the feature have evolved and continue to evolve over time, as more databases use it and more data is captured and analyzed. However, there are some limitations currently.
- Index recommendations are not evaluated against existing indexes, thus index consolidation between new and existing indexes is not currently available.
- If an index would provide benefits for a SELECT, the overhead of modifications due to INSERTs, UPDATEs, and DELETEs is not known prior to creation. SQL Server does monitor this overhead during the verification process, after the index is implemented.
There are benefits to Automatic Index Management that are worth stating:
- For anyone who has to manage a SQL Server database, but isn’t a DBA, index recommendations can be extremely helpful.
- Index recommendations are captured in the sys.dm_db_tuning_recommendations DMV even if the CREATE and DROP index options are not enabled. Therefore, if you’re unsure about the changes SQL Server might make, you can review what’s captured in the DMV and then make a decision to manually implement the recommendation.
Note: If you manually implement the recommendation, SQL Server does not perform any validation. If you implement the recommendation via the Portal (using the Apply button) or REST API, then it will be executed as if it were an automatic action, and validation will be performed (and the index could be automatically reverted if there’s a regression).
- The feature continues to improve. As I’ve said before, Microsoft isn’t trying to code DBAs or developers out of job, it’s trying to address the low-hanging fruit so you have more time for the tasks and projects that can’t be intelligently automated.
Summary
If you’re not ready to hand over the reins on index management, I get it. But if you have an Azure SQL Database at a minimum you should be checking the sys.dm_db_tuning_recommendations DMV regularly to see what SQL Server is recommending, and compare that to data you or your third-party monitoring tool might be capturing about index usage. After all, when was the last time you did a complete and thorough review of your indexes to understand what’s missing, what’s really being used, and what’s simply generating overhead in the database?
5 thoughts on “Automatic Index Management in Azure SQL Database”
Comments are closed.

Thanks for that
Its also not compressed – this is in SQL Azure – very important note!
Hi,
Thanks for great post. Need clarifications regarding below statement,
"Index recommendations are not evaluated against existing indexes, thus index consolidation between new and existing indexes is not currently available.
If an index would provide benefits for a SELECT, the overhead of modifications due to INSERTs, UPDATEs, and DELETEs is not known prior to creation. SQL Server does monitor this overhead during the verification process, after the index is implemented."
I have searched but can't able to find any mention regarding algorithm excluding Insert, update & delete queries on Microsoft article. Could you help me find them or is it mentioned in Microsoft white paper? Thanks.
We are considering turning them but ours is OLTP database, so overhead for insert, update & delete is considered seriously.
Hi Vishnu-
That information came from an email exchange I had with Microsoft's PM for the feature – it doesn't exist in the documentation.
Also, understand that it's not that the feature "excludes" insert, update, and delete queries, it's just not able to understand the impact of modifications for a potential index. After index creation, it does monitor that impact, but it can't predict it ahead of time.
Hope that helps, let me know if you have additional questions,
Erin
Thank you.
Please it will be grateful to know
Will it be expanded to other areas with time like implicit conversion
Does it consider index operation stats too while recommending any action pls
Manish-
I don't expect the Automatic Index Management feature to address implicit conversions – perhaps they could create a separate automatic tuning feature to address those. With regard to index operational statistics – I assume you mean looking at reads and writes for an index to see if it is used? If so, then yes, those are considered (that's how it determines if an index is being read from at all).
Hope that helps,
Erin