
Dealing with date and time instead of datetime
Data professionals don’t always get to use databases that have an optimal design. Sometimes the things that make you cry are things that we’ve done to ourselves, because they seemed like good ideas at the time. Sometimes they’re because of third party applications. Sometimes they simply predate you.
The one I’m thinking about in this post is when your datetime (or datetime2, or better still, datetimeoffset) column is actually two columns – one for the date, and one for the time. (If you have a separate column again for the offset, then I will give you a hug next time I see you, because you have probably had to deal with all kinds of hurt.)
I did a survey on Twitter, and found that this is a very real problem that about half of you have to deal with date and time from time to time.
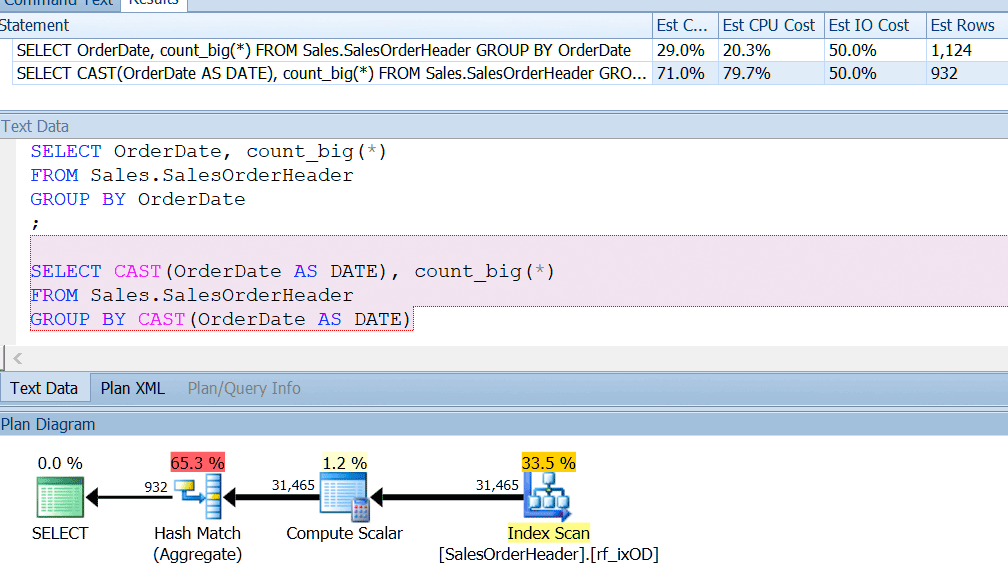
AdventureWorks almost does this – if you look in the Sales.SalesOrderHeader table, you’ll see a datetime column called OrderDate, which always has exact dates in it. I bet that if you’re a report developer at AdventureWorks, you have probably written queries that look for the number of orders on a particular day, using GROUP BY OrderDate, or something like that. Even if you knew that this was a datetime column and there was potential for it to also store a non-midnight time, you would still say GROUP BY OrderDate just for the sake of using an index properly. GROUP BY CAST(OrderDate AS DATE) just doesn’t cut it.
I have an index on the OrderDate, as you would if you were regularly querying that column, and I can see that grouping by CAST(OrderDate AS DATE) is around four times worse from a CPU perspective.
So I understand why you would be happy to query your column as if it’s a date, simply knowing that you’ll have a world of pain if the use of that column changes. Maybe you solve this by having a constraint on the table. Maybe you just put your head in the sand.
And when someone comes along and says “You know, we should store the time that orders happen too”, well, you think of all the code that assumes OrderDate is simply a date, and figure that having a separate column called OrderTime (data type of time, please) will be the most sensible option. I understand. It’s not ideal, but it works without breaking too much stuff.
At this point, I recommend you also make OrderDateTime, which would be a computed column joining the two (which you should do by adding the number of days since day 0 to CAST(OrderDate as datetime2), rather than trying to add the time to date, which is generally a whole lot messier). And then index OrderDateTime, because that would be sensible.
But quite often, you’ll find yourself with date and time as separate columns, with basically nothing you can do about it. You can’t add a computed column, because it’s a third party application and you don’t know what might break. Are you sure they never do SELECT *? One day I hope they’ll let us add columns and hide them, but for the time being, you certainly risk breaking stuff.
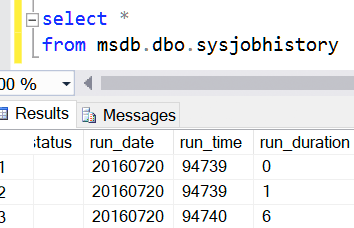
And, you know, even msdb does this. They’re both integers. And it’s because of backward compatibility, I assume. But I doubt you’re considering adding a computed column to a table in msdb.
So how do we query this? Let’s suppose we want to find the entries that were within a particular datetime range?
Let’s do some experimenting.
First, let’s create a table with 3 million rows, and index the columns we care about.
select identity(int,1,1) as ID, OrderDate,
dateadd(minute, abs(checksum(newid())) % (60 * 24), cast('00:00' as time)) as OrderTime
into dbo.Sales3M
from Sales.SalesOrderHeader
cross apply (select top 100 * from master..spt_values) v;
create index ixDateTime on dbo.Sales3M (OrderDate, OrderTime) include (ID);(I could have made that a clustered index, but I figure that a non-clustered index is more typical for your environment.)
Our data looks like this, and I want to find rows between, say, Aug 2 2011 at 8:30, and Aug 5 2011 at 21:30.


By looking through the data, I can see that I want all the rows between 48221 and 50171. That’s 50171-48221+1=1951 rows (the +1 is because it’s an inclusive range). This helps me be confident that my results are correct. You would probably have similar on your machine, but not exact, because I used random values when generating my table.
I know that I can’t just do something like this:
select *
from dbo.Sales3M
where OrderDate between '20110802' and '20110805'
and OrderTime between '8:30' and '21:30';…because this wouldn’t include something that happened overnight on the 4th. This gives me 1268 rows – clearly not right.
One option is to combine the columns:
select *
from dbo.Sales3M
where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2))
between '20110802 8:30' and '20110805 21:30';This gives the correct results. It does. It’s just that this is completely non-sargable, and gives us a Scan across all the rows in our table. On our 3 million rows it might take seconds to run this.

Our problem is that we have an ordinary case, and two special cases. We know that every row that satisfies OrderDate > ‘20110802’ AND OrderDate < ‘20110805’ is one that we want. But we also need every row that is on-or-after 8:30 on 20110802, and on-or-before 21:30 on 20110805. And that leads us to:
select *
from dbo.Sales3M
where (OrderDate > '20110802' and OrderDate < '20110805')
or (OrderDate = '20110802' and OrderTime >= '8:30')
or (OrderDate = '20110805' and OrderTime <= '21:30');OR is awful, I know. It can also lead to Scans, although not necessarily. Here I see three Index Seeks, being concatenated and then checked for uniqueness. The Query Optimizer obviously realises that it shouldn’t return the same row twice, but doesn’t realise that the three conditions are mutually exclusive. And actually, if you were doing this on a range within a single day, you’d get the wrong results.

We could use UNION ALL on this, which would mean the QO wouldn’t care whether the conditions were mutually exclusive. This gives us three Seeks that are concatenated – that’s pretty good.
select *
from dbo.Sales3M
where (OrderDate > '20110802' and OrderDate < '20110805')
union all
select *
from dbo.Sales3M
where (OrderDate = '20110802' and OrderTime >= '8:30')
union all
select *
from dbo.Sales3M
where (OrderDate = '20110805' and OrderTime <= '21:30');
But it’s still three seeks. Statistics IO tells me it’s 20 reads on my machine.

Now, when I think about sargability, I don’t just think about avoiding putting indexes columns inside expressions, I also think about what might help something seem sargable.
Take WHERE LastName LIKE 'Far%' for example. When I look at the plan for this, I see a Seek, with a Seek Predicate is looking for any name from Far up to (but not including) FaS. And then there’s a Residual Predicate checking the LIKE condition. This is not because the QO considers that LIKE is sargable. If it were, it would be able to use LIKE in the Seek Predicate. It’s because it knows that everything that is satisfied by that LIKE condition must be within that range.

Take WHERE CAST(OrderDate AS DATE) = '20110805'

Here we see a Seek Predicate that looks for OrderDate values between two values that have been worked out elsewhere in the plan, but creating a range in which the right values must exist. This isn’t >= 20110805 00:00 and < 20110806 00:00 (which is what I would’ve made it), it’s something else. The value for start of this range must be smaller than 20110805 00:00, because it’s >, not >=. All we can really say is that when someone within Microsoft implemented how the QO should respond to this kind of predicate, they gave it enough information to come up with what I call a “helper predicate.”
Now, I would love Microsoft to make more functions sargable, but that particular request was Closed long before they retired Connect.
But maybe what I mean is for them to make more helper predicates.
The problem with helper predicates is that they almost certainly read more rows than you want. But it’s still way better than looking through the whole index.
I know that all the rows I want to return will have OrderDate between 20110802 and 20110805. It’s just that there are some that I don’t want.
I could just remove them, and this would be valid:
select *
from dbo.Sales3M
where OrderDate between '20110802' and '20110805'
and not (OrderDate = '20110802' and OrderTime < '8:30')
and not (OrderDate = '20110805' and OrderTime > '21:30');
But I feel like this is a solution that requires some effort of thought to come up with. Less effort on the developer’s side is to simply provide a helper predicate to our correct-but-slow version.
select *
from dbo.Sales3M
where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2))
between '20110802 8:30' and '20110805 21:30'
and OrderDate between '20110802' and '20110805';
Both of these queries find the 2300 rows that are on the right days, and then need to check all of those rows against the other predicates. One must check the two NOT conditions, the other must do some type conversion and maths. But both are much quicker than what we had before, and do a single Seek (13 reads). Sure, I get warnings about an inefficient RangeScan, but this is my preference over doing three efficient ones.
In some ways, the biggest problem with this last example is that some well-meaning person would see that the helper predicate was redundant and might delete it. This is the case with all helper predicates. So put a comment in.
select *
from dbo.Sales3M
where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2))
between '20110802 8:30' and '20110805 21:30'
/* This next predicate is just a helper to improve performance */
and OrderDate between '20110802' and '20110805';If you have something which doesn’t fit in a nice sargable predicate, work out one that is, and then figure out what you need to exclude from it. You might just come up with a nicer solution.
5 thoughts on “Dealing with date and time instead of datetime”
Comments are closed.

Having two columns makes sense when the table is a source for an SSAS Tabular model. One datetime column is a nightmare for compressing the data, while having two columns compresses just nicely.
> The problem with helper predicates is that they almost certainly read more rows than you want. But it’s still way better than looking through the whole index.
Agreed. That's a nice tool for my developer's toolbox and one I rarely consider. In carpentry, this would be like a rough cut so you had to deal with carrying less material until you made the final cuts to get exactly what you needed. That's smart.
Thanks for reminding me there's usually more than one way to get what you want.
Brilliant!
Hello Rob:
Itzik posted a wonderful article about a new type of index for supporting interval queries and gave a T-SQL based implementation for such, while making a case for a new type of index actually being added to SQL Server specifically for supporting such.
Here is a link to the article. It's a compelling and provocative read.
http://www.itprotoday.com/software-development/interval-queries-sql-server
Respectfully,
Darryll Petrancuri
Yes – for intervals that's excellent. But you still need to combine the columns, and handle situations where you don't have those indexes.