
Row Goals, Part 2: Semi Joins
This post is part a series of articles about row goals. You can find the first part here:
It is relatively well-known that using TOP or a FAST n query hint can set a row goal in an execution plan (see Setting and Identifying Row Goals in Execution Plans if you need a refresher on row goals and their causes). It is rather less commonly appreciated that semi joins (and anti joins) can introduce a row goal as well, though this is somewhat less likely than is the case for TOP, FAST, and SET ROWCOUNT.
This article will help you understand when, and why, a semi join invokes the optimizer's row goal logic.
Semi joins
A semi join returns a row from one join input (A) if there is at least one matching row on the other join input (B).
The essential differences between a semi join and a regular join are:
- Semi join either returns each row from input A, or it does not. No row duplication can occur.
- Regular join duplicates rows if there are multiple matches on the join predicate.
- Semi join is defined to only return columns from input A.
- Regular join may return columns from either (or both) join inputs.
T-SQL currently lacks support for direct syntax like FROM A SEMI JOIN B ON A.x = B.y, so we need to use indirect forms like EXISTS, SOME/ANY (including the equivalent shorthand IN for equality comparisons), and set INTERSECT.
The description of a semi join above naturally hints at the application of a row goal, since we are interested in finding any matching row in B, not all such rows. Nevertheless, a logical semi join expressed in T-SQL might not lead to an execution plan using a row goal for several reasons, which we will unpack next.
Transformation and simplification
A logical semi join might be simplified away or replaced with something else during query compilation and optimization. The AdventureWorks example below shows a semi join being removed entirely, due to a trusted foreign key relationship:
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID IN
(
SELECT P.ProductID
FROM Production.Product AS P
);
The foreign key ensures that Product rows will always exist for each History row. As a result, the execution plan accesses only the TransactionHistory table:
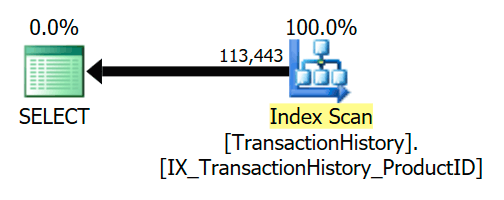
A more common example is seen when the semi join can be transformed to an inner join. For example:
SELECT P.ProductID
FROM Production.Product AS P
WHERE EXISTS
(
SELECT *
FROM Production.ProductInventory AS INV
WHERE INV.ProductID = P.ProductID
);
The execution plan shows that the optimizer introduced an aggregate (grouping on INV.ProductID) to ensure that the inner join can only return Product rows once, or not at all (as required to preserve the semi join semantics):
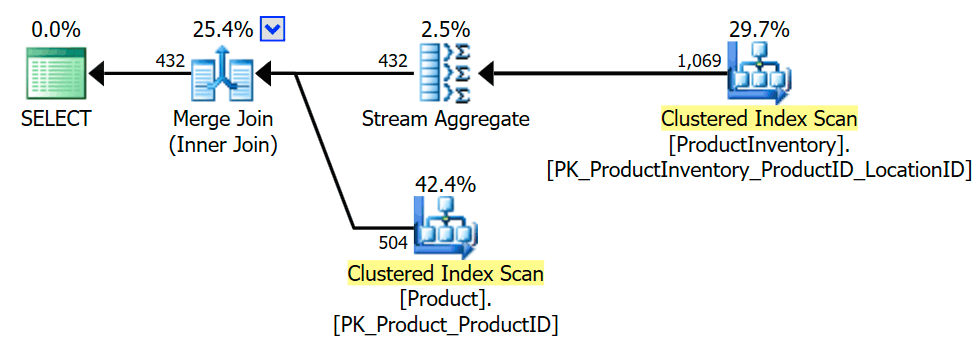
The transformation to inner join is explored early because the optimizer knows more tricks for inner equijoins than it does for semi joins, potentially leading to more optimization opportunities. Naturally, the final plan choice is still a cost-based decision among the explored alternatives.
Early Optimizations
Although T-SQL lacks direct SEMI JOIN syntax, the optimizer knows all about semi joins natively, and can manipulate them directly. The common workaround semi join syntaxes are transformed to a "real" internal semi join early in the query compilation process (well before even a trivial plan is considered).
The two main workaround syntax groups are EXISTS/INTERSECT, and ANY/SOME/IN. The EXISTS and INTERSECT cases differ only in that the latter comes with an implicit DISTINCT (grouping on all projected columns). Both EXISTS and INTERSECT are parsed as an EXISTS with correlated subquery. The ANY/SOME/IN representations are all interpreted as a SOME operation. We can explore early this optimization activity with a few undocumented trace flags, which send information about optimizer activity to the SSMS messages tab.
For example, the semi join we have been using so far can also be written using IN:
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.ProductID IN /* or = ANY/SOME */
(
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621);
The optimizer input tree is as follows:

The scalar operator ScaOp_SomeComp is the SOME comparison mentioned just above. The 2 is the code for an equality test, since IN is equivalent to = SOME. If you're interested, there are codes from 1 to 6 representing (<, =, <=, >, !=, >=) comparison operators respectively.
Returning to the EXISTS syntax that I prefer to use most often to express a semi join indirectly:
SELECT P.ProductID
FROM Production.Product AS P
WHERE EXISTS
(
SELECT *
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621);
The optimizer input tree is:

That tree is a pretty direct translation of the query text; though note that the SELECT * has already been replaced by a projection of the constant integer value 1 (see the penultimate line of text).
The next thing the optimizer does is to unnest the subquery in the relational selection (= filter) using rule RemoveSubqInSel. The optimizer always does this, since it cannot operate on subqueries directly. The result is an apply (a.k.a correlated or lateral join):

(The same subquery-removal rule produces the same output for the SOME input tree as well).
The next step is to rewrite the apply as a regular join using the ApplyHandler rule family. This is something the optimizer always tries to do, because it has more exploration rules for joins than it does for apply. Not every apply can be rewritten as a join, but the current example is straightforward and succeeds:

Note the type of the join is left semi. Indeed, this is exactly the same tree we would get immediately if T-SQL supported syntax like:
SELECT P.ProductID
FROM Production.Product AS P
LEFT SEMI JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID;
It would be nice to be able to express queries more directly like this. Anyway, the interested reader is encouraged to explore the above simplification activities with other logically-equivalent ways of writing this semi join in T-SQL.
The important takeaway at this stage is that the optimizer always removes subqueries, replacing them with an apply. It then tries to rewrite the apply as a regular join to maximize the chances of finding a good plan. Remember that all the preceding takes place before even a trivial plan is considered. During cost-based optimization, the optimizer may also consider join transformation back to an apply.
Hash and Merge Semi Join
SQL Server has three main physical implementations options available for a logical semi join. As long as an equijoin predicate is present, hash and merge join are available; both can operate in left- and right- semi join modes. Nested loops join supports only left (not right) semi join, but does not require an equijoin predicate. Let's look at the hash and merge physical options for our example query (written as a set intersect this time):
SELECT P.ProductID FROM Production.Product AS P
INTERSECT
SELECT TH.ProductID FROM Production.TransactionHistory AS TH;
The optimizer can find a plan for all four combinations of (left/right) and (hash/merge) semi join for this query:
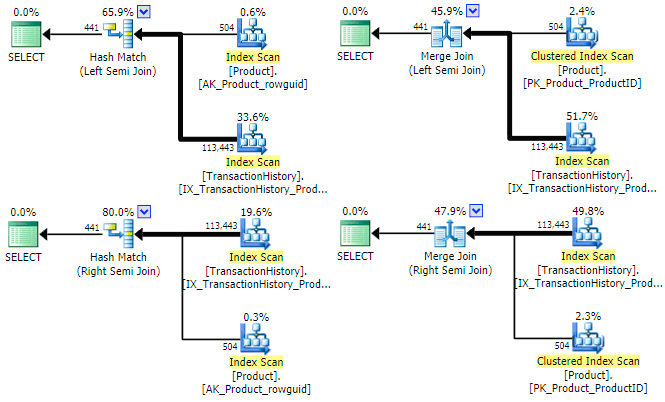
It is worth mentioning briefly why the optimizer might consider both left and right semi joins for each join type. For hash semi join, a major cost consideration is the estimated size of the hash table, which is always the left (upper) input initially. For merge semi join, the properties of each input determine whether a one-to-many or less efficient many-to-many merge with worktable will be used.
It might be apparent from the above execution plans that neither hash nor merge semi join would benefit from setting a row goal. Both join types always test the join predicate at the join itself, and aim to consume all rows from both inputs to return a full result set. That is not to say that performance optimizations do not exist for hash and merge join in general – for example, both can utilize bitmaps to reduce the number of rows reaching the join. Rather, the point is that a row goal on either input would not make a hash or merge semi join more efficient.
Nested Loops and Apply Semi Join
The remaining physical join type is nested loops, which comes in two flavours: regular (uncorrelated) nested loops and apply nested loops (sometimes also referred to as a correlated or lateral join).
Regular nested loops join is similar to hash and merge join in that the join predicate is evaluated at the join. As before, this means there is no value in setting a row goal on either input. The left (upper) input will always be fully consumed eventually, and the inner input has no way to determine which row(s) should be prioritized, since we cannot know if a row will join or not until the predicate is tested at the join.
By contrast, an apply nested loops join has one or more outer references (correlated parameters) at the join, with the join predicate pushed down the inner (lower) side of the join. This creates an opportunity for the useful application of a row goal. Recall that a semi join only requires us to check for the existence of a row on join input B that matches the current row on join input A (thinking just about nested loops join strategies now).
In other words, on each iteration of an apply, we can stop looking at input B as soon as the first match is found, using the pushed-down join predicate. This is exactly the sort of thing a row goal is good for: generating part of a plan optimized to return the first n matching rows quickly (where n = 1 here).
Of course, a row goal can be a good thing or not, depending on the circumstances. There is nothing special about the semi join row goal in that regard. Consider a situation where the inner side of the semi join is more complex than a single simple table access, perhaps a multi-table join. Setting a row goal can help the optimizer select an efficient navigational strategy for that particular subtree only, finding the first matching row to satisfy the semi join via nested loops joins and index seeks. Without the row goal, the optimizer might naturally choose hash or merge joins with sorts to minimize the expected cost of returning all possible rows. Note that there is an assumption here, namely that people typically write semi joins with the expectation that a row matching the search condition does in fact exist. This seems a fair enough assumption to me.
Regardless, the important point at this stage is: Only apply nested loops join has a row goal applied by the optimizer (remember though, a row goal for apply nested loops join is only added if the row goal is less than the estimate without it). We will look at a couple of worked examples to hopefully make all this clear next.
Nested Loops Semi Join Examples
The following script creates two heap temporary tables. The first has numbers from 1 to 20 inclusive; the other has 10 copies of each number in the first table:
DROP TABLE IF EXISTS #E1, #E2;
CREATE TABLE #E1 (c1 integer NULL);
CREATE TABLE #E2 (c1 integer NULL);
INSERT #E1 (c1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 20;
INSERT #E2 (c1)
SELECT
(SV.number % 20) + 1
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 200;
With no indexes and a relatively small number of rows, the optimizer chooses a nested loops (rather than hash or merge) implementation for the following semi join query). The undocumented trace flags allow us to see the optimizer output tree and row goal information:
SELECT E1.c1
FROM #E1 AS E1
WHERE E1.c1 IN
(SELECT E2.c1 FROM #E2 AS E2)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);
The estimated execution plan features a semi join nested loops join, with 200 rows per full scan of table #E2. The 20 iterations of the loop give a total estimate of 4,000 rows:
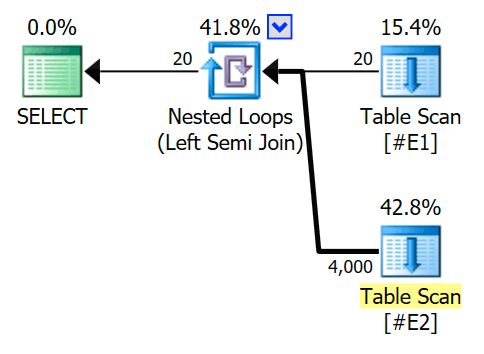
The properties of the nested loops operator show that the predicate is applied at the join meaning this is an uncorrelated nested loops join:

The trace flag output (on the SSMS messages tab) shows a nested loops semi join and no row goal (RowGoal 0):

Note that the post-execution plan for this toy query will not show 4,000 rows read from table #E2 in total. Nested loops semi join (correlated or not) will stop looking for more rows on the inner side (per iteration) as soon as the first match for the current outer row is encountered. Now, the order of rows encountered from the heap scan of #E2 on each iteration is non-deterministic (and may be different on each iteration), so in principle almost all of the rows could be tested on each iteration, in the event that the matching row is encountered as late as possible (or indeed, in the case of no matching row, not at all).
For example, if we assume a runtime implementation where rows happen to be scanned in the same order (e.g. "insertion order") each time, the total number of rows scanned in this toy example would be 20 rows on the first iteration, 1 row on the second iteration, 2 rows on the third iteration, and so on for a total of 20 + 1 + 2 + (…) + 19 = 210 rows. Indeed you are quite likely to observe this total, which says more about the limitations of simple demonstration code than it does about anything else. One cannot rely on the order of rows returned from an unordered access method any more than one can rely on the apparently-ordered output from a query without a top-level ORDER BY clause.
Apply Semi Join
We now create a nonclustered index on the larger table (to encourage the optimizer to choose an apply semi join) and run the query again:
CREATE NONCLUSTERED INDEX nc1 ON #E2 (c1);
SELECT E1.c1
FROM #E1 AS E1
WHERE E1.c1 IN
(SELECT E2.c1 FROM #E2 AS E2)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);
The execution plan now features an apply semi join, with 1 row per index seek (and 20 iterations as before):
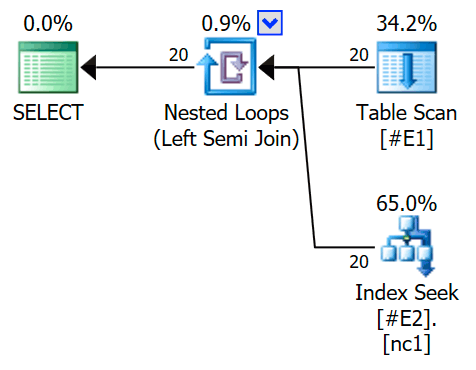
We can tell it is an apply semi join because the join properties show an outer reference rather than a join predicate:
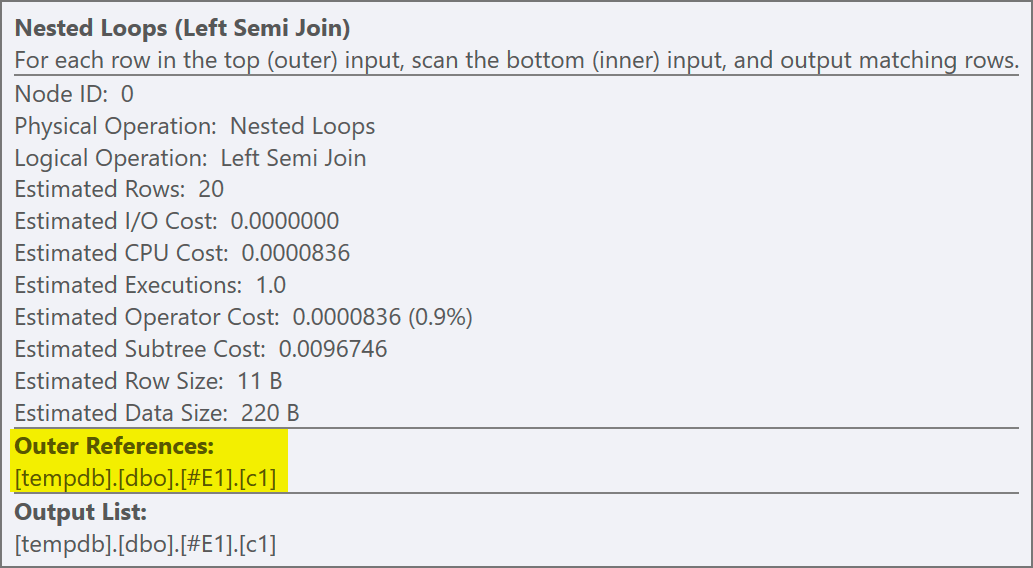
The join predicate has been pushed down the inner side of the apply, and matched to the new index:
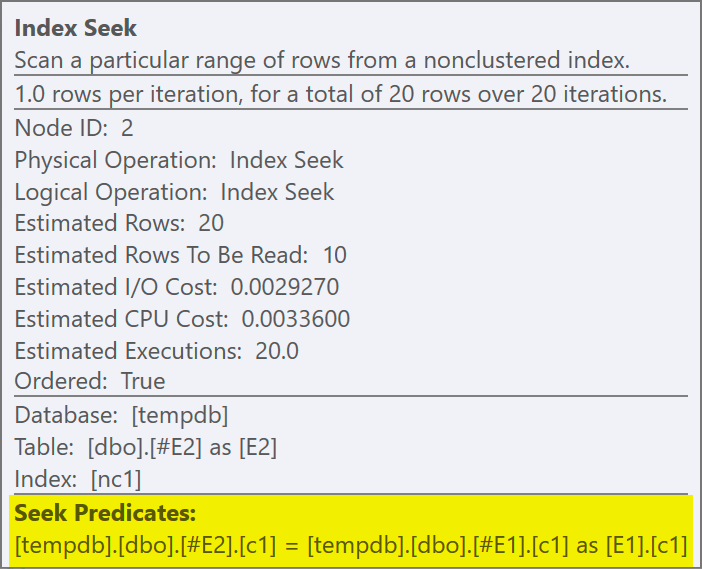
Each seek is expected to return 1 row, despite the fact that each value is duplicated 10 times in that table; this is an effect of the row goal. The row goal will be easier to identify on SQL Server builds that expose the EstimateRowsWithoutRowGoal plan attribute (SQL Server 2017 CU3 at the time of writing). In a forthcoming version of Plan Explorer, this will also be exposed on tooltips for relevant operators:

The trace flag output is:

The physical operator has changed from a loops join to an apply running in left semi join mode. Access to table #E2 has acquired a row goal of 1 (the cardinality without the row goal is shown as 10). The row goal is not a huge deal in this case because the cost of retrieving an estimated ten rows per seek is not very much more than for one row. Disabling row goals for this query (using trace flag 4138 or the DISABLE_OPTIMIZER_ROWGOAL query hint) would not change the shape of the plan.
Nevertheless, in more realistic queries, the cost reduction due to the inner-side row goal can make the difference between competing implementation options. For example, disabling the row goal might cause the optimizer to choose a hash or merge semi join instead, or any one of many other options considered for the query. If nothing else, the row goal here accurately reflects the fact that an apply semi join will stop searching the inner side as soon as the first match is found, and move on to the next outer side row.
Note that duplicates were created in table #E2 so that the apply semi join row goal (1) would be lower than the normal estimate (10, from statistics density information). If there were no duplicates, the row estimate for each seek into #E2 would also be 1 row, so a row goal of 1 would not be applied (remember the general rule about this!)
Row Goals versus Top
Given that execution plans do not indicate the presence of a row goal at all before SQL Server 2017 CU3, one might think it would have been clearer to implement this optimization using an explicit Top operator, rather than a hidden property like a row goal. The idea would be to simply place a Top (1) operator on the inner side of an apply semi/anti join instead of setting a row goal at the join itself.
Using a Top operator in this way would not have been entirely without precedent. For example, there is already a special version of Top known as a row count top seen in data modification execution plans when a non-zero SET ROWCOUNT is in effect (note that this specific usage has been deprecated since 2005 though it is still allowed in SQL Server 2017). The row count top implementation is a little clunky in that the top operator is always shown as a Top (0) in the execution plan, regardless of the actual row count limit in effect.
There is no compelling reason why the apply semi join row goal could not have been replaced with an explicit Top (1) operator. That said, there are some reasons to prefer not to do that:
- Adding an explicit Top (1) requires more optimizer coding effort and testing than adding a row goal (which is already used for other things).
- Top is not a relational operator; the optimizer has little support for reasoning about it. This could negatively impact plan quality by limiting the optimizer's ability to transform parts of a query plan e.g. by moving aggregates, unions, filters, and joins around.
- It would introduce a tight coupling between the apply implementation of the semi join and the top. Special cases and tight coupling are great ways to introduce bugs and make future changes more difficult and error-prone.
- The Top (1) would be logically redundant, and only present for its row goal side-effect.
That last point is worth expanding on with an example:
SELECT
P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT TOP (1)
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
);
The TOP (1) in the exists subquery is simplified away by the optimizer, giving a simple semi join execution plan:
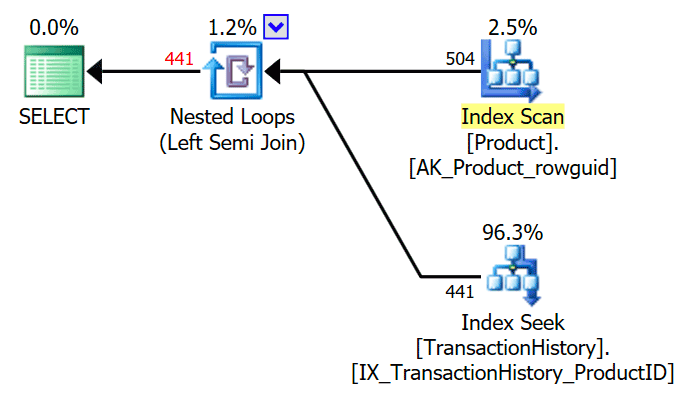
The optimizer can also remove a redundant DISTINCT or GROUP BY in the subquery. The following all produce the same plan as above:
-- Redundant DISTINCT
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT DISTINCT
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
);
-- Redundant GROUP BY
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
GROUP BY TH.ProductID
);
-- Redundant DISTINCT TOP (1)
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT DISTINCT TOP (1)
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
);
Summary and Final Thoughts
Only apply nested loops semi join can have a row goal set by the optimizer. This is the only join type that pushes the join predicate(s) down from the join, allowing testing for the existence of a match to be performed early. Uncorrelated nested loops semi join almost never* sets a row goal, and neither does a hash or merge semi join. Apply nested loops can be distinguished from uncorrelated nested loops join by the presence of outer references (instead of a predicate) on the nested loops join operator for an apply.
The chances of seeing an apply semi join in the final execution plan somewhat depend on early optimization activity. Lacking direct T-SQL syntax, we have to express semi joins in indirect terms. These are parsed into a logical tree containing a subquery, which early optimizer activity transforms to an apply, and then into an uncorrelated semi join where possible.
This simplification activity determines whether a logical semi join is presented to the cost-based optimizer as an apply or regular semi join. When presented as a logical apply semi join, the CBO is almost certain to produce a final execution plan featuring physical apply nested loops (and so setting a row goal). When presented with an uncorrelated semi join, the CBO may consider transformation to an apply (or it may not). The final choice of plan is a series of cost-based decisions as usual.
Like all row goals, the semi join row goal can be a good or a bad thing for performance. Knowing that an apply semi join sets a row goal will at least help people recognise and address the cause if a problem should occur. The solution will not always (or even usually) be disabling row goals for the query. Improvements in indexing (and/or the query) can often be made to provide an efficient way to locate the first matching row.
I will cover anti semi joins in a separate article, continuing the row goals series.
* The exception is an uncorrelated nested loops semi join with no join predicate (an uncommon sight). This does set a row goal.
6 thoughts on “Row Goals, Part 2: Semi Joins”
Comments are closed.
Hi Paul
Interesting article. I have a system on SQL 2016 where I solved issue with "query processor ran out of internal resources" by activating TF 4102 (change to SQL 2000 semi join). It looks like general performance in system has improved too by increrasing abillity to use parallel query execution.
Are you able to explain difference between SQL 2000 semi join implementation and current semi join implementation?
I recall the general issue, but it is too long ago to remember all the details. If you can link me to a self-contained repro somewhere, or an execution plan, I'd be happy to look into it.
Speaking generally, switching off exploration paths can reduce the amount of time the optimizer spends in early phases on a narrow part of the plan. In the extreme case, yes, this can result in a time out rather than moving on to the next (possibly parallel) stage.
That said, the sorts of queries that normally suffer are not good optimization candidates in the first place (simply too large, or non-relational elements being common).
I'm a little surprised 4102 would still be active in 2016.
Excellent blog post, Paul. As usual.
However, I do want to clarify one point. In the paragraphs where you do the semi join between #E1 and #E2 before adding an index, you write: "The 20 iterations of the loop give a total of 4,000 rows". You do not write that this is the ESTIMATED number of rows. The ACTUAL number of rows is far lower: 210. (This number depends on the exact order in which SQL Server decides tos tore the rows in #E2 so it may be different on other computers – however it will always be far less then 4000).
The reason for this is that the Nested Loops operator, when doing an semi Join, is smart enough to stop requesting further rows from the inner input. For one of the 20 values in the outer input, the first row is a match so only that single row is read. On another iteration, the second row is a match. And so on. 1 + 2 + 3 + (…) + 20 = 210 which is the actual number of rows on my laptop.
When you added the index, you made it "safe" for the optimizer to add a rowgoal. Because of the index, we know that the Index Seek will only return matching rows, so we'll never need more than one row and 1 is a safe rowgoal. Before adding the index, there was no "safe" value for the rowgoal, because it's impossible to predict how many "wrong" values we need to skip before we find a match. And apparently the optimizer considers no row goal and a guaranteed over-estimate as a less worse option than to use a random number as the row goal. (Which I understand, BTW – in this case there were no alternatives to the table scan, but in more realistic queries setting a "random" rowgoal might have a huge adverse effect on the performance of the inner input)
Thank you Hugo. This series was originally one (very) long article and it seems the point about nested loops semi join always terminating an iteration on the first match was lost during one of the many reorganizations. I have added that back in the appropriate place, and also made it clearer that the explanation of the Plan Explorer display (20 x 200 = 4,000) was tied to a pre-execution plan.
Your second point is only really valid in the specific context of the necessarily simple demo. In general, there might not be a seek, or the seek might have a residual, or there might be other filtering effects in the inner-side subtree.
The point here (i.e. at this place in the series) is that the optimizer always adds a row goal for an apply semi join (pushed join predicate), but never for an uncorrelated semi join (predicate at the join). This is independent of the complexity of the inner side, and without any regard for a "safety" concept (beyond the row goal being lower than the non-goal estimate). There really is no sensible way to set a goal for a certain row when the test for a match happens at the join.
This is all explored further in parts 3 and 4 of the series.
Here is a contrived example of a row goal with an inner-side scan using the demo tables above:
SELECT E1.c1 FROM #E1 AS E1 WHERE EXISTS ( SELECT 1 FROM #E2 AS E2 WHERE E2.c1 = E1.c1 GROUP BY E2.c1 * 10 HAVING COUNT_BIG(*) > 1 );Also:
SELECT E1.c1 FROM #E1 AS E1 WHERE EXISTS ( SELECT 1 FROM #E2 AS E2 WHERE E2.c1 = (SELECT E1.c1 WHERE @@SPID = @@SPID) );Accuracy and performance are different measures. SQL Server will still generate correct results regardless of the order in which it processes inner joins, for example. Some may lead to worse performance, though.