
Performance Myths : Truncate Can't Be Rolled Back

Guest Author : Derik Hammer (@SQLHammer)
The differences between TRUNCATE TABLE and DELETE are often misunderstood. I seek to disprove the myth that TRUNCATE TABLE cannot be rolled back:
Reading the manual
The Books Online article on TRUNCATE TABLE is fairly descriptive:
The fact that TRUNCATE TABLE uses fewer transaction log resources implies that it does write to the transaction log to some degree. Let's find out how much and investigate its ability to be rolled back.
Prove it
In an earlier post, Paul Randal goes through this in meticulous detail, but I thought it would be useful to provide very simple repros to disprove both elements of this myth.
Can TRUNCATE TABLE be rolled back?
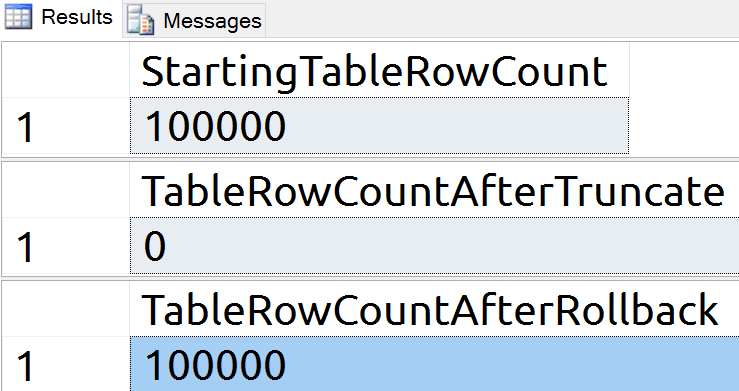
Proving that TRUNCATE TABLE can be rolled back is easy enough. I will simply put TRUNCATE TABLE in a transaction and roll it back.
USE demo;
BEGIN TRANSACTION;
SELECT COUNT(*) [StartingTableRowCount] FROM [dbo].[Test];
TRUNCATE TABLE [dbo].[Test];
SELECT COUNT(*) [TableRowCountAfterTruncate] FROM [dbo].[Test];
ROLLBACK TRANSACTION;
SELECT COUNT(*) [TableRowCountAfterRollback] FROM [dbo].[Test];There are 100,000 rows in the table and it returns to 100,000 rows after rollback:
Does TRUNCATE TABLE write to the log?
By executing a CHECKPOINT, we get a clean starting point. Then we can check the log records before and after the TRUNCATE TABLE.
USE demo;
CHECKPOINT;
SELECT COUNT(*) [StartingLogRowCount]
FROM sys.fn_dblog (NULL, NULL);
TRUNCATE TABLE [dbo].[Test];
SELECT COUNT(*) [LogRowCountAfterTruncate]
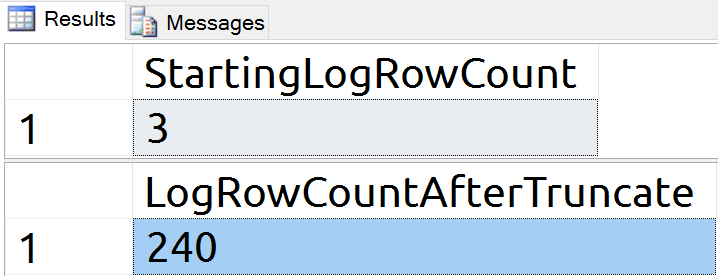
FROM sys.fn_dblog (NULL, NULL);Our TRUNCATE TABLE command generated 237 log records (at least initially). This is what enables us to perform a rollback, and how SQL Server registers the change to begin with.
What about DELETEs?
If both DELETE and TRUNCATE TABLE write to the log and can be rolled back, what makes them different?
As mentioned in the BOL reference above, TRUNCATE TABLE takes fewer system and transaction log resources. We already observed that 237 log records were written for the TRUNCATE TABLE command. Now, let us look at the DELETE.
USE demo;
CHECKPOINT;
SELECT COUNT(*) [StartingLogRowCount]
FROM sys.fn_dblog (NULL, NULL);
DELETE FROM [dbo].[Test];
SELECT COUNT(*) [LogRowCountAfterDelete]
FROM sys.fn_dblog (NULL, NULL);
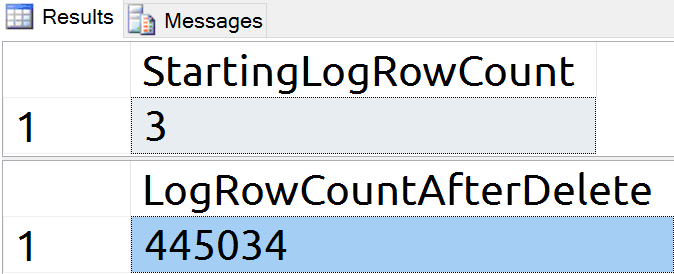
With over 440,000 log records written for the DELETE, the TRUNCATE command is clearly much more efficient.
Wrap-up
TRUNCATE TABLE is a logged command and can be rolled back, with a huge performance advantage over an equivalent DELETE. DELETE becomes important when you want to delete fewer rows than exist in the table (since TRUNCATE TABLE does not accept a WHERE clause). For some ideas about making DELETEs more efficient, see Aaron Bertrand's post, "Break large delete operations into chunks."
About the Author
 Derik is a data professional and freshly-minted Microsoft Data Platform MVP focusing on SQL Server. His passion focuses around high availability, disaster recovery, continuous integration, and automated maintenance. His experience has spanned long-term database administration, consulting, and entrepreneurial ventures working in the financial and healthcare industries. He is currently a Senior Database Administrator in charge of the Database Operations team at Subway Franchise World Headquarters. When he is not on the clock, or blogging at SQLHammer.com, Derik devotes his time to the #sqlfamily as the chapter leader for the FairfieldPASS SQL Server user group in Stamford, CT.
Derik is a data professional and freshly-minted Microsoft Data Platform MVP focusing on SQL Server. His passion focuses around high availability, disaster recovery, continuous integration, and automated maintenance. His experience has spanned long-term database administration, consulting, and entrepreneurial ventures working in the financial and healthcare industries. He is currently a Senior Database Administrator in charge of the Database Operations team at Subway Franchise World Headquarters. When he is not on the clock, or blogging at SQLHammer.com, Derik devotes his time to the #sqlfamily as the chapter leader for the FairfieldPASS SQL Server user group in Stamford, CT.11 thoughts on “Performance Myths : Truncate Can't Be Rolled Back”
Comments are closed.

I think this myth came about because in Oracle a TRUNCATE could not (at least the last I used Oracle) and did not rollback in Oracle.
Good article, but it is good to remember that TRUNCATE TABLE can not execute on a table with FK.
Follows the error message:
Msg 4712, Level 16, State 1, Line 55
Cannot truncate table 'tb_teste1' because it is being referenced by a FOREIGN KEY constraint.
Scott – you are correct. In Oracle, a TRUNCATE statement doesn't generate any transactional information. TRUNCATE resets the high water mark on the table to 0 indicating that there is no data. This is incredibly fast, but also generates no undo information, rendering ROLLBACK ineffective. SQL Server obviously takes a different approach.
what about drop table / create table ?
Should then be a lot faster on large tables.
I doubt, that a table drop would be faster (since it could rolled back too). Furthermore it causes a lot more trouble to recreate a table with all columns (do not forget computed), DEFAULT and CHECK and FOREIGN KEY constraints, identity columns (should they start again from 1, could this interact with some history- or log entries), extended properties (as MS_Description on the table, columns, indexes, constraints …), indexes (don't forget indexes that where put in from a local dba, if you are a software vendor and don't forgot those uncommon XML, JSON or geographic index).
And of course someone could have configured differing COLLATIONS on a column. Or could have set some table options (as this one to place even short VARCHAR(max) data in extra pages).
Conclusion: the overhead to recreate a table (and do not make errors) could be too much, even if it would be one millisecond faster (I doubt, since the SQL Server does not really drop local #temptables, that are used in stored procedures. SQL Server "renames" them instead, so that they could be reused when the procedure is called again; does not work, if there are other DDL-statements except the CREATE TABLE regarding the #temptable in the procedure).
Truncate requires elevated privileges as it also resets any seed columns. ALTER is required on the table or the schema
but to get records back delete and truncate must have save same data in log then why truncate logged less records than delete ?
I don't know exactly if this is the real behavior, but when I had to write a rollbackable TRUNCATE I would only log, that tbl1 had the pages 100-564 and 768 to 923 plus pages 650-658 for its index. Then I would put an exclusive lock on those pages (to prevent them from beeing overwritten), unassign them (so the table seems to be empty since there are no more pages in it or its indexes).
When committing the TRUNCATE the page locks would be released and the next page split / page assignement could use them to put their stuff in it.
To verify this (I don't have time at the moment), you could run create a table as copy of another (including content), let you show, which pages are used by this table, start a transaction, run a TRUNCATE and fill the table again. After that it should not have reused the same pages (but assigned some new ones).
No, truncate just deallocares the pages and logs these deallocations.
If you rollback inside the transaction the page allocation are re instated
can you restore/rollback
after the transaction is complete?
– after a COMMIT you could not ROLLBACK
– of course you could make a database restore to a point in time before the commit, when you have a backup