
It’s not you, it’s me (I/O troubleshooting)
Guest Author : Monica Rathbun (@SQLEspresso)
Sometimes hardware performance issues, like Disk I/O latency, boil down to non-optimized workload rather than underperforming hardware. Many Database Admins, me included, want to immediately blame the storage for the slowness. Before you go and spend a ton of money on new hardware, you should always examine your workload for unnecessary I/O.
Things to Examine
| Item | I/O Impact | Possible Solutions |
|---|---|---|
| Unused Indexes | Extra Writes | Remove / Disable Index |
| Missing Indexes | Extra Reads | Add Index / Covering Indexes |
| Implicit Conversions | Extra Reads & Writes | Covert or Cast Field at source before evaluating value |
| Functions | Extra Reads & Writes | Removed them, convert the data before evaluation |
| ETL | Extra Reads & Writes | Use SSIS, Replication, Change Data Capture, Availability Groups |
| Order & Group Bys | Extra Reads & Writes | Remove them where possible |
Unused Indexes
We all know the power of an index. Having the proper indexes can make light years of a difference in query speed. However, how many of us continually maintain our indexes above and beyond index rebuild and reorgs? It’s important to regularly run an index script to evaluate which indexes are actually being used. I personally use Glenn Berry’s diagnostic queries to do this.
You’ll be surprised to find that some of your indexes haven’t been read at all. These indexes are a strain on resources, especially on a highly transactional table. When looking at the results, pay attention to those indexes that have a high number of writes combined with a low number of reads. In this example, you can see I am wasting writes. The non-clustered index has been written to 11 million times, but only read twice.

I start by disabling the indexes that fall into this category, and then drop them after I have confirmed no issues have arisen. Doing this exercise routinely can greatly reduce unnecessary I/O writes to your system, but keep in mind usage statistics on your indexes are only as good as the last reboot, so make sure you have been collecting data for a full business cycle before writing off an index as "useless."
Missing Indexes
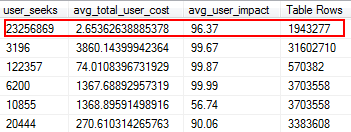
Missing Indexes are one of the easiest things to fix; after all, when you run an execution plan, it will tell you if any indexes were not found but that would have been useful. But wait, I hope you’re not just arbitrarily adding indexes based on this suggestion. Doing this can create duplicate indexes, and indexes that may have minimal use, and therefore waste I/O. Again, back to Glenn’s scripts, he gives us a great tool to evaluate the usefulness of an index by providing user seeks, user impact, and number of rows. Pay attention to those with high reads along with low cost and impact. This is a great place to start, and will help you reduce read I/O.
Implicit Conversions
Implicit conversions often happen when a query is comparing two or more columns with different data types. In the below example, the system is having to perform extra I/O in order to compare a varchar(max) column to an nvarchar(4000) column, which leads to an implicit conversion, and ultimately a scan instead of a seek. By fixing the tables to have matching data types, or simply converting this value before evaluation, you can greatly reduce I/O and improve cardinality (the estimated rows the optimizer should expect).
dbo.table1 t1 JOIN dbo.table2 t2
ON t1.ObjectName = t2.TableName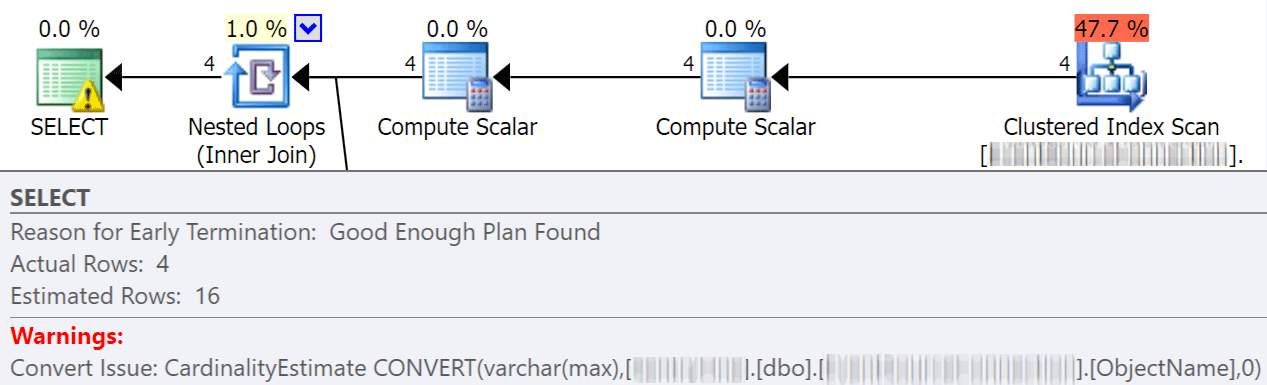
Jonathan Kehayias goes into a lot more detail in this great post: " How expensive are column-side Implicit Conversions?"
Functions
One of the most avoidable, easy-to-fix things I’ve run across that saves on I/O expense is removing functions from where clauses. A perfect example is a date comparison, as shown below.
CONVERT(Date,FromDate) >= CONVERT(Date, dbo.f_realdate(MyField))
AND
(CONVERT(Date,ToDate) <= CONVERT(Date, dbo.f_realdate(MyField))Whether it is on a JOIN statement or in a WHERE clause this causes each column to be converted before it is evaluated. By simply converting these columns before evaluation into a temp table you can eliminate a ton of unnecessary I/O.
Or, even better, don't perform any conversions at all (for this specific case, Aaron Bertrand talks here about avoiding functions in the where clause, and note that this can still be bad even though convert to date is sargable).
ETL
Take the time to examine how your data is being loaded. Are you truncating and reloading tables? Can you implement Replication, a read only AG Replica, or log shipping instead? Are all the tables being written to actually being read? How are you loading the data? Is it through stored procedures or SSIS? Examining things like this can reduce I/O dramatically.
In my environment, I found that we were truncating 48 tables daily with over 120 million rows each morning. On top of that we were loading 9.6 million rows hourly. You can imagine how much unnecessary I/O that created. In my case, implementing transactional replication was my solution of choice. Once implemented we had far fewer user complaints of slowdowns during our load times, which had initially been attributed to the slow storage.
Order By & Group By
 Ask yourself, does that data have to be returned in order? Do we really need to group in the procedure, or can we handle that in a report or application? Order By and Group By operations can cause reads to spill over to disk, which causes additional disk I/O. If these actions are warranted, ensure you have supporting indexes and fresh statistics on the columns being sorted or grouped. This will help the optimizer during plan creation. Since we sometimes use Order By and Group By in temp tables. make sure you have Auto Create Statistics On for TEMPDB as well as your user databases. The more up to date the statistics are, the better cardinality the optimizer can get, resulting in better plans, less spill over, and less I/O.
Ask yourself, does that data have to be returned in order? Do we really need to group in the procedure, or can we handle that in a report or application? Order By and Group By operations can cause reads to spill over to disk, which causes additional disk I/O. If these actions are warranted, ensure you have supporting indexes and fresh statistics on the columns being sorted or grouped. This will help the optimizer during plan creation. Since we sometimes use Order By and Group By in temp tables. make sure you have Auto Create Statistics On for TEMPDB as well as your user databases. The more up to date the statistics are, the better cardinality the optimizer can get, resulting in better plans, less spill over, and less I/O.
Now Group By definitely has its place when it comes to aggregating data instead of returning a ton of rows. But the key here is to reduce I/O, the addition of the aggregation adds to the I/O.
Summary
These are just the tip-of-the-iceberg kinds of things to do, but a great place to start to reduce I/O. Before you go blaming hardware on your latency issues take a look at what you can do to minimize disk pressure.
About the Author
 Monica Rathbun is currently a Consultant at Denny Cherry & Associates Consulting, and a Microsoft Data Platform MVP. She has been a Lone DBA for 15 years, working with all aspects of SQL Server and Oracle. She travels speaking at SQLSaturdays helping other Lone DBAs with techniques on how one can do the jobs of many. Monica is the Leader of the Hampton Roads SQL Server User Group and is a Mid-Atlantic Pass Regional Mentor. You can always find Monica on Twitter (@SQLEspresso) handing out helpful tips and tricks to her followers. When she’s not busy with work, you will find her playing taxi driver for her two daughters back and forth to dance classes.
Monica Rathbun is currently a Consultant at Denny Cherry & Associates Consulting, and a Microsoft Data Platform MVP. She has been a Lone DBA for 15 years, working with all aspects of SQL Server and Oracle. She travels speaking at SQLSaturdays helping other Lone DBAs with techniques on how one can do the jobs of many. Monica is the Leader of the Hampton Roads SQL Server User Group and is a Mid-Atlantic Pass Regional Mentor. You can always find Monica on Twitter (@SQLEspresso) handing out helpful tips and tricks to her followers. When she’s not busy with work, you will find her playing taxi driver for her two daughters back and forth to dance classes.6 thoughts on “It’s not you, it’s me (I/O troubleshooting)”
Comments are closed.

Thank you
These are all good points — but rather than start shooting in all directions, I think it's better to start with collecting data on I/O usage by queries (ideally with a monitoring tool, or at least with home-brew scripts). Then it's possible to attack the actual pain points, and correlate them to the disk latency counters.
Just one note on sys.dm_db_index_usage_stats and unused indexed. In versions of SQL between 2008 and 2016 the statistics for indexes are reset by an index rebuild.
Toby made the point I was going to make. I have seen people (me included) disable or delete an index because of low usage stats only the find out later it was due to a recent index rebuild. That resets the counters also. I typically join the index usage DMV to an index maintenance log table so I can see the index maintenance history alongside the usage stats.
Also check out Brent Ozars' BlitzIndex utility script.
Thank you for this summary. There are also indexes maintained and even used, but number of writes is greater than number of reads. And this is also related to I/O performance. I have found a good article about different cases at Simple Talk: https://www.simple-talk.com/sql/performance/tune-your-indexing-strategy-with-sql-server-dmvs/