
Using DBCC CLONEDATABASE and Query Store for Testing
Last summer, after SP2 for SQL Server 2014 was released, I wrote about using DBCC CLONEDATABASE for more than simply investigating a query performance issue. A recent comment on the post by a reader got me thinking that I should expand on what I had in mind on how to use the cloned database for testing. Peter wrote:
Well Peter, here you go. I hope this helps!
Setup
DBCC CLONEDATABASE was made available in SQL Server 2016 SP1, so that’s what we will use for testing as it’s the current release, and because I can use Query Store to capture my data. To make life easier, I’m creating a database for testing, rather than restoring a sample from Microsoft.
USE [master];
GO
DROP DATABASE IF EXISTS [CustomerDB], [CustomerDB_CLONE];
GO
/* Change file locations as appropriate */
CREATE DATABASE [CustomerDB]
ON PRIMARY
(
NAME = N'CustomerDB', FILENAME = N'C:\Databases\CustomerDB.mdf' ,
SIZE = 512MB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB
)
LOG ON
(
NAME = N'CustomerDB_log', FILENAME = N'C:\Databases\CustomerDB_log.ldf' ,
SIZE = 512MB , MAXSIZE = UNLIMITED , FILEGROWTH = 65536KB
);
GO
ALTER DATABASE [CustomerDB] SET RECOVERY SIMPLE;Now, create a table and add some data:
USE [CustomerDB];
GO
CREATE TABLE [dbo].[Customers]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID])
);
GO
/*
This adds 1,000,000 rows to the table; feel free to add less
*/
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (1000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (20000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name + c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn;
GO
CREATE NONCLUSTERED INDEX [PhoneBook_Customers]
ON [dbo].[Customers]([LastName],[FirstName])
INCLUDE ([EMail]);Now, we'll enable Query Store:
USE [master];
GO
ALTER DATABASE [CustomerDB] SET QUERY_STORE = ON;
ALTER DATABASE [CustomerDB] SET QUERY_STORE (
OPERATION_MODE = READ_WRITE,
CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30),
DATA_FLUSH_INTERVAL_SECONDS = 60,
INTERVAL_LENGTH_MINUTES = 5,
MAX_STORAGE_SIZE_MB = 256,
QUERY_CAPTURE_MODE = ALL,
SIZE_BASED_CLEANUP_MODE = AUTO,
MAX_PLANS_PER_QUERY = 200);
Once we have the database created and populated, and we’ve configured Query Store, we’ll create a stored procedure for testing:
USE [CustomerDB];
GO
DROP PROCEDURE IF EXISTS [dbo].[usp_GetCustomerInfo];
GO
CREATE OR ALTER PROCEDURE [dbo].[usp_GetCustomerInfo] (@LastName [nvarchar](64))
AS
SELECT
[CustomerID],
[FirstName],
[LastName],
[Email],
CASE WHEN [Active] = 1 THEN 'Active'
ELSE 'Inactive' END [Status]
FROM [dbo].[Customers]
WHERE [LastName] = @LastName;
Take note: I used the cool new CREATE OR ALTER PROCEDURE syntax which is available in SP1.
We will run our stored procedure a couple times to get some data in Query Store. I’ve added WITH RECOMPILE because I know that these two input values will generate different plans, and I want to make sure to capture them both.
EXEC [dbo].[usp_GetCustomerInfo] 'name' WITH RECOMPILE;
GO
EXEC [dbo].[usp_GetCustomerInfo] 'query_cost' WITH RECOMPILE;If we look in Query Store, we see the one query from our stored procedure, and two different plans (each with its own plan_id). If this were a production environment, we’d have significantly more data in terms of runtime statistics (duration, IO, CPU information) and more executions. Even though our demo has less data, the theory is the same.
SELECT
[qsq].[query_id],
[qsp].[plan_id],
[qsq].[object_id],
[rs].[count_executions],
DATEADD(MINUTE, -(DATEDIFF(MINUTE, GETDATE(), GETUTCDATE())),
[qsp].[last_execution_time]) AS [LocalLastExecutionTime],
[qst].[query_sql_text],
ConvertedPlan = TRY_CONVERT(XML, [qsp].[query_plan])
FROM [sys].[query_store_query] [qsq]
JOIN [sys].[query_store_query_text] [qst]
ON [qsq].[query_text_id] = [qst].[query_text_id]
JOIN [sys].[query_store_plan] [qsp]
ON [qsq].[query_id] = [qsp].[query_id]
JOIN [sys].[query_store_runtime_stats] [rs]
ON [qsp].[plan_id] = [rs].[plan_id]
WHERE [qsq].[object_id] = OBJECT_ID(N'usp_GetCustomerInfo'); Query Store data from stored procedure query Query Store data after stored procedure execution (query_id = 1) with two different plans (plan_id = 1, plan_id = 2)
Query Store data from stored procedure query Query Store data after stored procedure execution (query_id = 1) with two different plans (plan_id = 1, plan_id = 2)
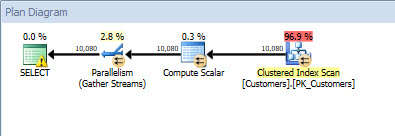 Query plan for plan_id = 1 (input value = 'name')
Query plan for plan_id = 1 (input value = 'name')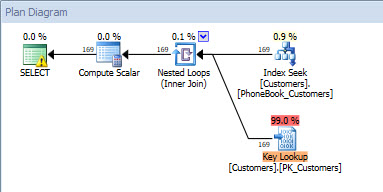 Query plan for plan_id = 2 (input value = 'query_cost')
Query plan for plan_id = 2 (input value = 'query_cost')Once we have the information we need in Query Store, we can clone the database (Query Store data will be included in the clone by default):
DBCC CLONEDATABASE (N'CustomerDB', N'CustomerDB_CLONE');As I mentioned in my previous CLONEDATABASE post, the cloned database is designed to be used for product support to test query performance issues. As such, it’s read-only after it is cloned. We’re going to go beyond what DBCC CLONEDATABASE is currently designed to do, so again, I just want to remind you of this note from the Microsoft documentation:
In order to make any changes for testing, I need to take the database out of a read-only mode. And I’m ok with that because I do not plan to use this for production purposes. If this cloned database is in a production environment, I recommend you back it up and restore it on a dev or test server and do your testing there. I do not recommend testing in production, nor do I recommend testing against the production instance (even with a different database).
/*
Make it read write
(back it up and restore it somewhere else so you're not working in production)
*/
ALTER DATABASE [CustomerDB_CLONE] SET READ_WRITE WITH NO_WAIT;Now that I’m in a read-write state, I can make changes, do some testing, and capture metrics. I’ll start with verifying that I get the same plan I did before (reminder, you won’t see any output here because there’s no data in the cloned database):
/*
verify we get the same plan
*/
USE [CustomerDB_CLONE];
GO
EXEC [dbo].[usp_GetCustomerInfo] 'name';
GO
EXEC [dbo].[usp_GetCustomerInfo] 'query_cost' WITH RECOMPILE;In checking Query Store, you’ll see the same plan_id value as before. There are multiple rows for the query_id/plan_id combination because of the different intervals of time across which the data was captured (determined by the INTERVAL_LENGTH_MINUTES setting, which we set to 5).
SELECT
[qsq].[query_id],
[qsp].[plan_id],
[qsq].[object_id],
[rs].[count_executions],
DATEADD(MINUTE, -(DATEDIFF(MINUTE, GETDATE(), GETUTCDATE())),
[qsp].[last_execution_time]) AS [LocalLastExecutionTime],
[rsi].[runtime_stats_interval_id],
[rsi].[start_time],
[rsi].[end_time],
[qst].[query_sql_text],
ConvertedPlan = TRY_CONVERT(XML, [qsp].[query_plan])
FROM [sys].[query_store_query] [qsq]
JOIN [sys].[query_store_query_text] [qst]
ON [qsq].[query_text_id] = [qst].[query_text_id]
JOIN [sys].[query_store_plan] [qsp]
ON [qsq].[query_id] = [qsp].[query_id]
JOIN [sys].[query_store_runtime_stats] [rs]
ON [qsp].[plan_id] = [rs].[plan_id]
JOIN [sys].[query_store_runtime_stats_interval] [rsi]
ON [rs].[runtime_stats_interval_id] = [rsi].[runtime_stats_interval_id]
WHERE [qsq].[object_id] = OBJECT_ID(N'usp_GetCustomerInfo');
GO Query Store data after executing the stored procedure against the cloned database
Query Store data after executing the stored procedure against the cloned database
Testing Code Changes
For our first test, let’s look at how we could test a change to our code – specifically, we'll modify our stored procedure to remove the [Active] column from the SELECT list.
/*
Change procedure using CREATE OR ALTER
(remove [Active] from query)
*/
CREATE OR ALTER PROCEDURE [dbo].[usp_GetCustomerInfo] (@LastName [nvarchar](64))
AS
SELECT
[CustomerID],
[FirstName],
[LastName],
[Email]
FROM [dbo].[Customers]
WHERE [LastName] = @LastName;
Re-run the stored procedure:
EXEC [dbo].[usp_GetCustomerInfo] 'name' WITH RECOMPILE;
GO
EXEC [dbo].[usp_GetCustomerInfo] 'query_cost' WITH RECOMPILE;If you happened to display the actual execution plan, you'll notice that both queries now use the same plan, as the query is covered by the nonclustered index we created originally.
![Execution plan after changing stored procedure to remove [Active]](https://sqlperformance.com/wp-content/uploads/2017/02/planuseindex.jpg) Execution plan after changing stored procedure to remove [Active]
Execution plan after changing stored procedure to remove [Active]
We can verify with Query Store, our new plan has a plan_id of 41:
SELECT
[qsq].[query_id],
[qsp].[plan_id],
[qsq].[object_id],
[rs].[count_executions],
DATEADD(MINUTE, -(DATEDIFF(MINUTE, GETDATE(), GETUTCDATE())),
[qsp].[last_execution_time]) AS [LocalLastExecutionTime],
[rsi].[runtime_stats_interval_id],
[rsi].[start_time],
[rsi].[end_time],
[qst].[query_sql_text],
ConvertedPlan = TRY_CONVERT(XML, [qsp].[query_plan])
FROM [sys].[query_store_query] [qsq]
JOIN [sys].[query_store_query_text] [qst]
ON [qsq].[query_text_id] = [qst].[query_text_id]
JOIN [sys].[query_store_plan] [qsp]
ON [qsq].[query_id] = [qsp].[query_id]
JOIN [sys].[query_store_runtime_stats] [rs]
ON [qsp].[plan_id] = [rs].[plan_id]
JOIN [sys].[query_store_runtime_stats_interval] [rsi]
ON [rs].[runtime_stats_interval_id] = [rsi].[runtime_stats_interval_id]
WHERE [qsq].[object_id] = OBJECT_ID(N'usp_GetCustomerInfo'); Query Store data after changing the stored procedure
Query Store data after changing the stored procedure
You'll also notice here that there is a new query_id (40). Query Store performs textual matching, and we changed the text of the query, thus a new query_id is generated. Also note that the object_id stayed the same, because use used the CREATE OR ALTER syntax. Let's make another change, but use DROP and then CREATE OR ALTER.
/*
Change procedure using DROP and then CREATE OR ALTER
(concatenate [FirstName] and [LastName])
*/
DROP PROCEDURE IF EXISTS [dbo].[usp_GetCustomerInfo];
GO
CREATE OR ALTER PROCEDURE [dbo].[usp_GetCustomerInfo] (@LastName [nvarchar](64))
AS
SELECT
[CustomerID],
RTRIM([FirstName]) + ' ' + RTRIM([LastName]),
[Email]
FROM [dbo].[Customers]
WHERE [LastName] = @LastName;Now, we re-run the procedure:
EXEC [dbo].[usp_GetCustomerInfo] 'name';
GO
EXEC [dbo].[usp_GetCustomerInfo] 'query_cost' WITH RECOMPILE;Now the output from Query Store gets more interesting, and note that my Query Store predicate has changed to WHERE [qsq].[object_id] <> 0.
SELECT
[qsq].[query_id],
[qsp].[plan_id],
[qsq].[object_id],
[rs].[count_executions],
DATEADD(MINUTE, -(DATEDIFF(MINUTE, GETDATE(), GETUTCDATE())),
[qsp].[last_execution_time]) AS [LocalLastExecutionTime],
[rsi].[runtime_stats_interval_id],
[rsi].[start_time],
[rsi].[end_time],
[qst].[query_sql_text],
ConvertedPlan = TRY_CONVERT(XML, [qsp].[query_plan])
FROM [sys].[query_store_query] [qsq]
JOIN [sys].[query_store_query_text] [qst]
ON [qsq].[query_text_id] = [qst].[query_text_id]
JOIN [sys].[query_store_plan] [qsp]
ON [qsq].[query_id] = [qsp].[query_id]
JOIN [sys].[query_store_runtime_stats] [rs]
ON [qsp].[plan_id] = [rs].[plan_id]
JOIN [sys].[query_store_runtime_stats_interval] [rsi]
ON [rs].[runtime_stats_interval_id] = [rsi].[runtime_stats_interval_id]
WHERE [qsq].[object_id] <> 0; Query Store data after changing the stored procedure using DROP and then CREATE OR ALTER
Query Store data after changing the stored procedure using DROP and then CREATE OR ALTER
The object_id has changed to 661577395, and I have a new query_id (42) because the query text changed, and a new plan_id (43). While this plan is a still an index seek of my nonclustered index, it's still a different plan in Query Store. Understand that the recommended method for changing objects when you’re using Query Store is to use ALTER rather than a DROP and CREATE pattern. This is true in production, and for testing such as this, as you want to keep the object_id the same to make finding changes easier.
Testing Index Changes
For Part II of our testing, rather than changing the query, we want to see if we can improve performance by changing the index. So we will change the stored procedure back to the original query, then modify the index.
CREATE OR ALTER PROCEDURE [dbo].[usp_GetCustomerInfo] (@LastName [nvarchar](64))
AS
SELECT
[CustomerID],
[FirstName],
[LastName],
[Email],
CASE
WHEN [Active] = 1 THEN 'Active'
ELSE 'Inactive'
END [Status]
FROM [dbo].[Customers]
WHERE [LastName] = @LastName;
GO
/*
Modify existing index to add [Active] to cover the query
*/
CREATE NONCLUSTERED INDEX [PhoneBook_Customers]
ON [dbo].[Customers]([LastName],[FirstName])
INCLUDE ([EMail], [Active])
WITH (DROP_EXISTING=ON);Because I dropped the original stored procedure, the original plan is no longer in cache. If I had made this index change first, as part of testing, remember that the query would not automatically use the new index unless I forced a recompilation. I could use sp_recompile on the object, or I could continue to use the WITH RECOMPILE option on the procedure to see I got the same plan with the two different values (remember I had two different plans initially). I don't need WITH RECOMPILE as the plan is not in cache, but I'm leaving it on for consistency's sake.
EXEC [dbo].[usp_GetCustomerInfo] 'name' WITH RECOMPILE;
GO
EXEC [dbo].[usp_GetCustomerInfo] 'query_cost' WITH RECOMPILE;Within Query Store I see another new query_id (because the object_id is different than it was originally!) and a new plan_id:
 Query Store data after adding new index
Query Store data after adding new index
If I check the plan, I can see that the modified index is being used.
![Query plan after [Active] added to the index (plan_id = 50)](https://sqlperformance.com/wp-content/uploads/2017/02/9new-plan.jpg) Query plan after [Active] added to the index (plan_id = 50)
Query plan after [Active] added to the index (plan_id = 50)
And now that I have a different plan, I could take it a step further and try to simulate a production workload to verify that with different input parameters, this stored procedure generates the same plan and uses the new index. There's a caveat here, though. You might have noticed the warning on the Index Seek operator – this occurs because there are no statistics on the [LastName] column. When we created the index with [Active] as an included column, the table was read to update statistics. There is no data in the table, hence the lack of statistics. This is definitely something to keep in mind with index testing. When statistics are missing, the optimizer will use heuristics which may or may not convince the optimizer to use the plan you're expecting.
Summary
I’m a big fan of DBCC CLONEDATABASE. I’m an even bigger fan of Query Store. When you put the two of them together, you have great capability for quick testing of index and code changes. With this method, you’re primarily looking at execution plans to validate improvements. Because there is no data in a cloned database, you cannot capture resource use and runtime stats to either prove or disprove a perceived benefit in an execution plan. You still need to restore the database and test against a full set of data – and Query Store can still be a huge help in capturing quantitative data. However, for those cases where the plan validation is sufficient, or for those of you who don’t do any testing currently, DBCC CLONEDATABASE provides that easy button you’ve been looking for. Query Store makes the process even easier.
A few items of note:
I don’t recommend using WITH RECOMPILE when calling stored procedures (or declaring them that way – see Paul White's post). I used this option for this demo because I created a parameter-sensitive stored procedure, and I wanted to make sure the different values generated different plans and didn’t use a plan from cache.
Running these tests in SQL Server 2014 SP2 with DBCC CLONEDATABASE is quite possible, but there’s obviously a different approach for capturing queries and metrics, as well as looking at performance. If you’d like to see this same testing methodology, without Query Store, leave a comment and let me know!
6 thoughts on “Using DBCC CLONEDATABASE and Query Store for Testing”
Comments are closed.

excellent and detailed step by step post.
thanks for share, it's very helpfull
If I had made this index change first, as part of testing, remember that the query would not automatically use the new index unless I forced a recompilation.
Please clarify is it not true that schema changed so recompile will occur itself…
Please also how to capture on 2014 servers. Please
In the code above the SP had been ALTERed, which would have forced a recompile automatically. If that had not been done, and I had just added a new index, then I would need to either force a recompile on the SP before testing, use the RECOMPILE option when running the SP, or remove existing plans in cache before testing the index.
Query Store is not available in SQL Server 2014, so it cannot be used to capture metrics, you would have to capture them using an alternate methodology.