
One way to get an index seek for a leading %wildcard
A performance issue I see often is when users need to match part of a string with a query like the following:
... WHERE SomeColumn LIKE N'%SomePortion%';With a leading wildcard, this predicate is "non-SARGable" – just a fancy way of saying we can't find the relevant rows by using a seek against an index on SomeColumn.
One solution we get kind of hand-wavy about is full-text search; however, this is a complex solution, and it requires that the search pattern consists of full words, doesn't use stop words, and so on. This can help if we're looking for rows where a description contains the word "soft" (or other derivatives like "softer" or "softly"), but it doesn't help when we're looking for strings that could be contained within words (or that aren't words at all, like all product SKUs that contain "X45-B" or all license plates that contain the sequence "7RA").
What if SQL Server somehow knew about all of the possible portions of a string? My thought process is along the lines of trigram / trigraph in PostgreSQL. The basic concept is that the engine has the ability to do point-style lookups on substrings, meaning you don't have to scan the entire table and parse every full value.
The specific example they use there is the word cat. In addition to the full word, it can be broken down into portions: c, ca, and at (they leave out a and t by definition – no trailing substring can be shorter than two characters). In SQL Server, we don't need it to be that complex; we only really need half the trigram – if we think about building a data structure that contains all of the substrings of cat, we only need these values:
- cat
- at
- t
We don't need c or ca, because anyone searching for LIKE '%ca%' could easily find value 1 by using LIKE 'ca%' instead. Similarly, anyone searching for LIKE '%at%' or LIKE '%a%' could use a trailing wildcard only against these three values and find the one that matches (e.g. LIKE 'at%' will find value 2, and LIKE 'a%' will also find value 2, without having to find those substrings inside value 1, which is where the real pain would come from).
So, given that SQL Server does not have anything like this built in, how do we generate such a trigram?
A Separate Fragments Table
I'm going to stop referencing "trigram" here because this isn't truly analogous to that feature in PostgreSQL. Essentially, what we are going to do is build a separate table with all of the "fragments" of the original string. (So in the cat example, there'd be a new table with those three rows, and LIKE '%pattern%' searches would be directed against that new table as LIKE 'pattern%' predicates.)
Before I start to show how my proposed solution would work, let me be absolutely clear that this solution should not be used in every single case where LIKE '%wildcard%' searches are slow. Because of the way we're going to "explode" the source data into fragments, it is likely limited in practicality to smaller strings, such as addresses or names, as opposed to larger strings, like product descriptions or session abstracts.
A more practical example than cat is to look at the Sales.Customer table in the WideWorldImporters sample database. It has address lines (both nvarchar(60)), with the valuable address info in the column DeliveryAddressLine2 (for reasons unknown). Someone might be looking for anyone who lives on a street named Hudecova, so they will be running a search like this:
SELECT CustomerID, DeliveryAddressLine2
FROM Sales.Customers
WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
/* This returns two rows:
CustomerID DeliveryAddressLine2
---------- ----------------------
61 1695 Hudecova Avenue
181 1846 Hudecova Crescent
*/As you would expect, SQL Server needs to perform a scan to locate those two rows. Which should be simple; however, because of the complexity of the table, this trivial query yields a very messy execution plan (the scan is highlighted, and has a warning for residual I/O):
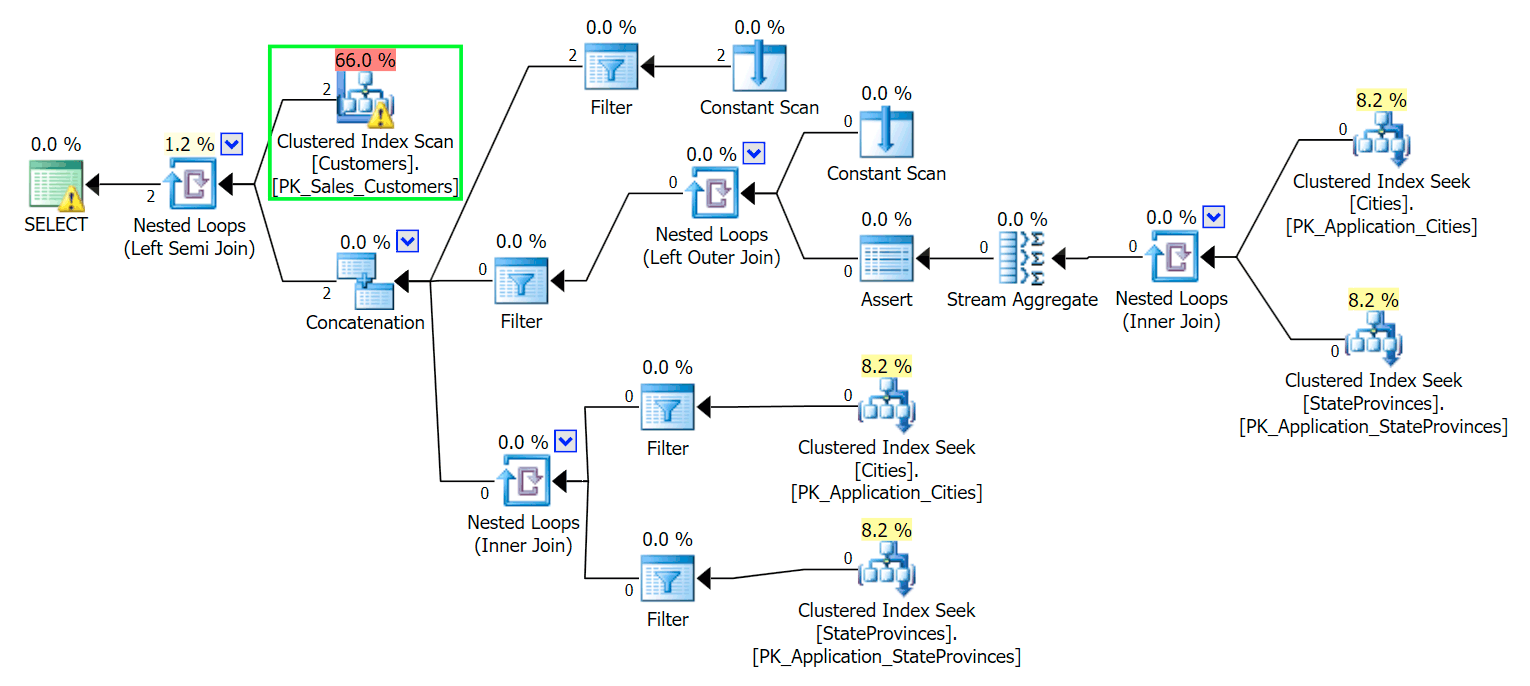
Blecch. To keep our lives a simple, and to make sure we don't chase a bunch of red herrings, let's create a new table with a subset of the columns, and to start we'll just insert those same two rows from above:
CREATE TABLE Sales.CustomersCopy
(
CustomerID int IDENTITY(1,1) CONSTRAINT PK_CustomersCopy PRIMARY KEY,
CustomerName nvarchar(100) NOT NULL,
DeliveryAddressLine1 nvarchar(60) NOT NULL,
DeliveryAddressLine2 nvarchar(60)
);
GO
INSERT Sales.CustomersCopy
(
CustomerName,
DeliveryAddressLine1,
DeliveryAddressLine2
)
SELECT
CustomerName,
DeliveryAddressLine1,
DeliveryAddressLine2
FROM Sales.Customers
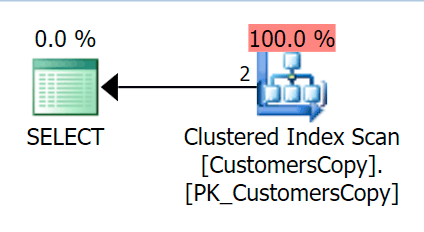
WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';Now, if we run the same query we ran against the main table, we get something a lot more reasonable to look at as a starting point. This is still going to be a scan no matter what we do – if we add an index with DeliveryAddressLine2 as the leading key column, we'll most likely get an index scan, with a key lookup depending on whether the index covers the columns in the query. As is, we get a clustered index scan:
Next, let's create a function that will "explode" these address values into fragments. We would expect 1846 Hudecova Crescent, for example, to have the following set of fragments:
- 1846 Hudecova Crescent
- 846 Hudecova Crescent
- 46 Hudecova Crescent
- 6 Hudecova Crescent
- Hudecova Crescent
- Hudecova Crescent
- udecova Crescent
- decova Crescent
- ecova Crescent
- cova Crescent
- ova Crescent
- va Crescent
- a Crescent
- Crescent
- Crescent
- rescent
- escent
- scent
- cent
- ent
- nt
- t
It is fairly trivial to write a function that will produce this output – we just need a recursive CTE that can be used to step through each character throughout the length of the input:
CREATE FUNCTION dbo.CreateStringFragments( @input nvarchar(60) )
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
WITH x(x) AS
(
SELECT 1 UNION ALL SELECT x+1 FROM x WHERE x < (LEN(@input))
)
SELECT Fragment = SUBSTRING(@input, x, LEN(@input)) FROM x
);
GO
SELECT Fragment FROM dbo.CreateStringFragments(N'1846 Hudecova Crescent');
-- same output as above bulleted listNow, let's create a table that will store all of the address fragments, and which Customer they belong to:
CREATE TABLE Sales.CustomerAddressFragments
(
CustomerID int NOT NULL,
Fragment nvarchar(60) NOT NULL,
CONSTRAINT FK_Customers FOREIGN KEY(CustomerID) REFERENCES Sales.CustomersCopy(CustomerID)
);
CREATE CLUSTERED INDEX s_cat ON Sales.CustomerAddressFragments(Fragment, CustomerID);Then we can populate it like this:
INSERT Sales.CustomerAddressFragments(CustomerID, Fragment)
SELECT c.CustomerID, f.Fragment
FROM Sales.CustomersCopy AS c
CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f;For our two values, this inserts 42 rows (one address has 20 characters, and the other has 22). Now our query becomes:
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
INNER JOIN Sales.CustomerAddressFragments AS f
ON f.CustomerID = c.CustomerID
AND f.Fragment LIKE N'Hudecova%';Here is a much nicer plan - two clustered index *seeks* and a nested loops join:
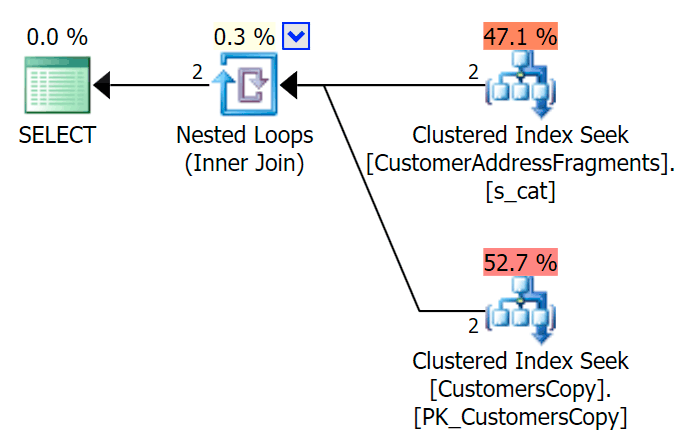
We can also do this another way, using EXISTS:
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
WHERE EXISTS
(
SELECT 1 FROM Sales.CustomerAddressFragments
WHERE CustomerID = c.CustomerID
AND Fragment LIKE N'Hudecova%'
);Here is that plan, which looks on the surface to be more expensive - it chooses to scan the CustomersCopy table. We'll see shortly why this is the better query approach:
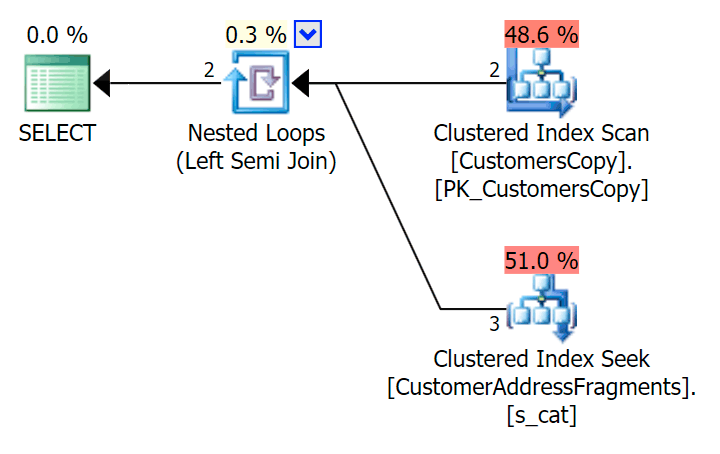
Now, on this massive data set of 42 rows, the differences seen in duration and I/O are so minuscule they're irrelevant (and in fact, at this small size, the scan against the base table looks cheaper in terms of I/O than the other two plans that use the fragment table):

What if we were to populate these tables with a lot more data? My copy of Sales.Customers has 663 rows, so if we cross join that against itself, we'd get somewhere near 440,000 rows. So let's just mash up 400K and generate a much larger table:
TRUNCATE TABLE Sales.CustomerAddressFragments;
DELETE Sales.CustomersCopy;
DBCC FREEPROCCACHE WITH NO_INFOMSGS;
INSERT Sales.CustomersCopy WITH (TABLOCKX) (CustomerName, DeliveryAddressLine1, DeliveryAddressLine2)
SELECT TOP (400000) c1.CustomerName, c1.DeliveryAddressLine1, c2.DeliveryAddressLine2
FROM Sales.Customers c1 CROSS JOIN Sales.Customers c2
ORDER BY NEWID(); -- fun for distribution
-- this will take a bit longer - on my system, ~4 minutes
-- probably because I didn't bother to pre-expand files
INSERT Sales.CustomerAddressFragments WITH (TABLOCKX) (CustomerID, Fragment)
SELECT c.CustomerID, f.Fragment
FROM Sales.CustomersCopy AS c
CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f;
-- repeated for compressed version of the table
-- 7.25 million rows, 278MB (79MB compressed; saving those tests for another day)
Now to compare performance and execution plans given a variety of possible search parameters, I tested the above three queries with these predicates:
| Query | Predicates | ||||
|---|---|---|---|---|---|
| WHERE DeliveryLineAddress2 LIKE ... | N'%Hudecova%' | N'%cova%' | N'%ova%' | N'%va%' | |
| JOIN ... WHERE Fragment LIKE ... | N'Hudecova%' | N'cova%' | N'ova%' | N'va%' | |
| WHERE EXISTS (... WHERE Fragment LIKE ...) | |||||
As we remove letters from the search pattern, I would expect to see more rows output, and perhaps different strategies chosen by the optimizer. Let's see how it went for each pattern:
Hudecova%
For this pattern, the scan was still the same for the LIKE condition; however, with more data, the cost is much higher. The seeks into the fragments table really pay off at this row count (1,206), even with really low estimates. The EXISTS plan adds a distinct sort, which you would expect to add to the cost, though in this case it ends up doing fewer reads:

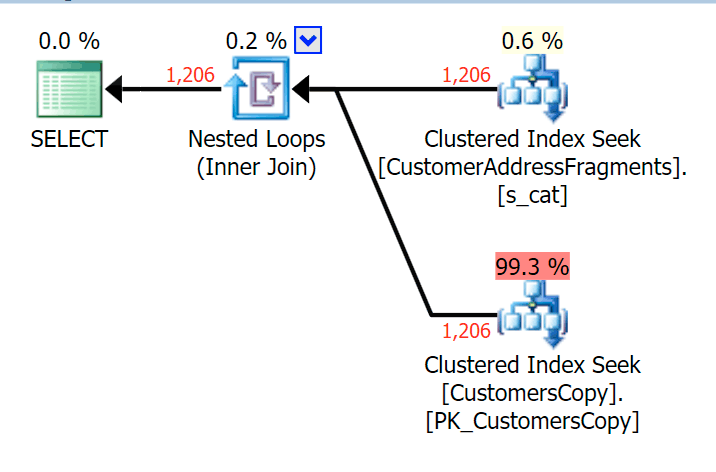 Plan for the JOIN to the fragments table
Plan for the JOIN to the fragments table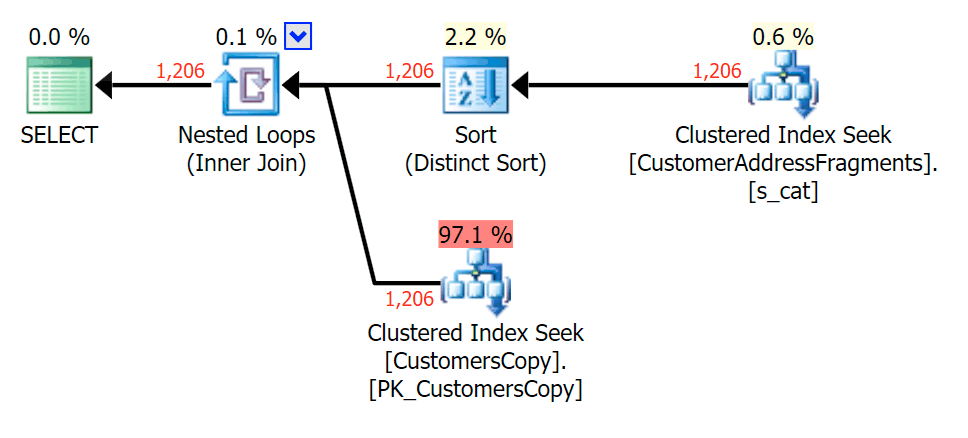 Plan for the EXISTS against the fragments table
Plan for the EXISTS against the fragments tablecova%
As we strip some letters off our predicate, we see the reads actually a bit higher than with the original clustered index scan, and now we over-estimate the rows. Even still, our duration remains significantly lower with both fragment queries; the difference this time is more subtle - both have sorts (only EXISTS is distinct):

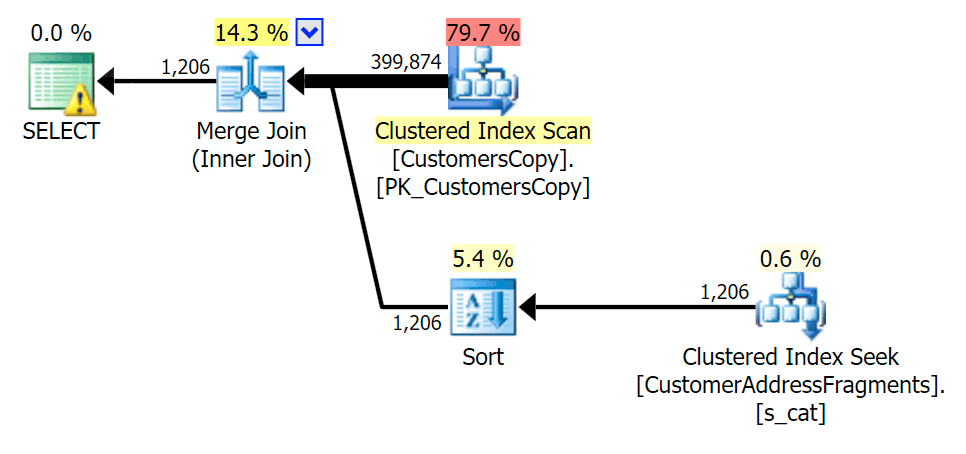 Plan for the JOIN to the fragments table
Plan for the JOIN to the fragments table Plan for the EXISTS against the fragments table
Plan for the EXISTS against the fragments tableova%
Stripping an additional letter didn't change much; though it is worth noting how much the estimated and actual rows jump here - meaning that this may be a common substring pattern. The original LIKE query is still quite a bit slower than the fragment queries.

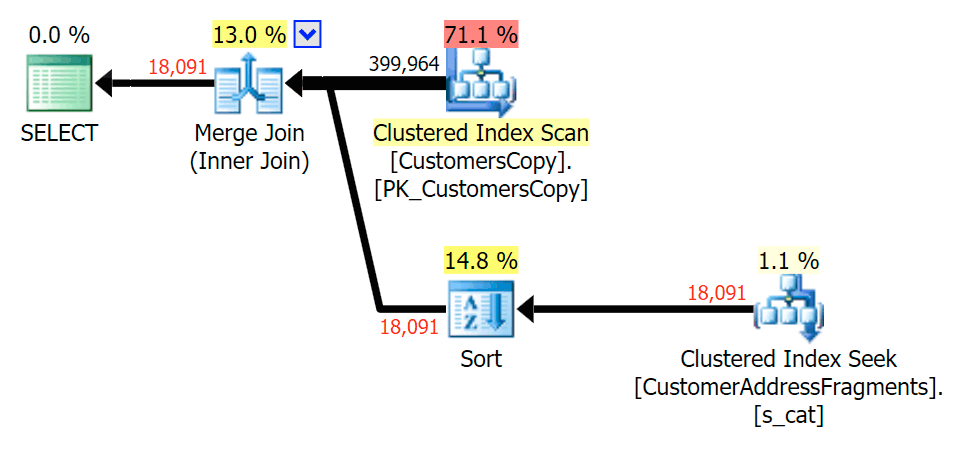 Plan for the JOIN to the fragments table
Plan for the JOIN to the fragments table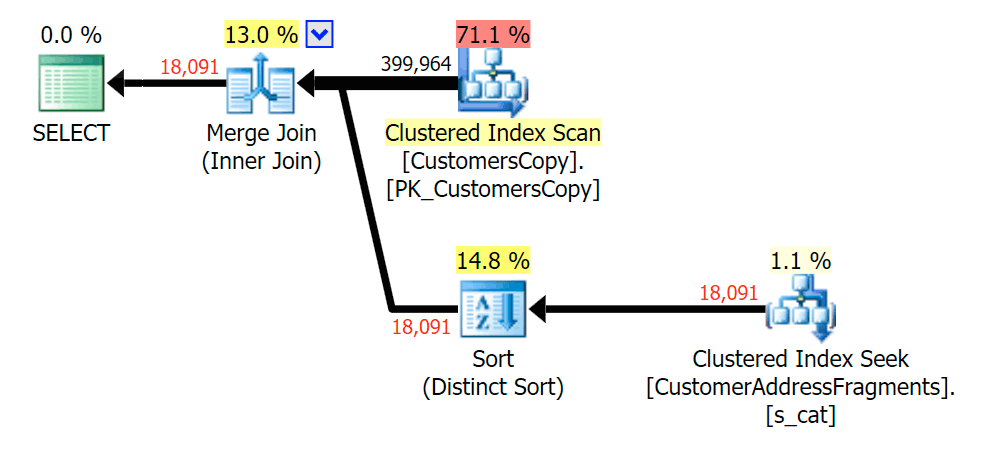 Plan for the EXISTS against the fragments table
Plan for the EXISTS against the fragments tableva%
Down to two letters, this does introduce our first discrepancy. Notice that the JOIN produces more rows than the original query or the EXISTS. Why would that be?

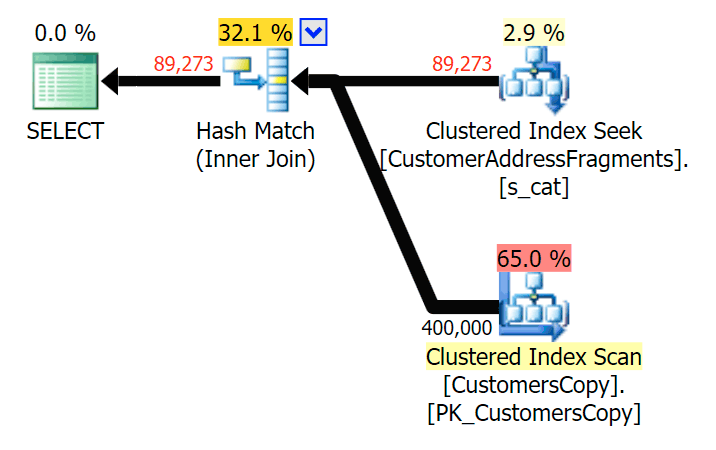 Plan for the JOIN to the fragments table
Plan for the JOIN to the fragments table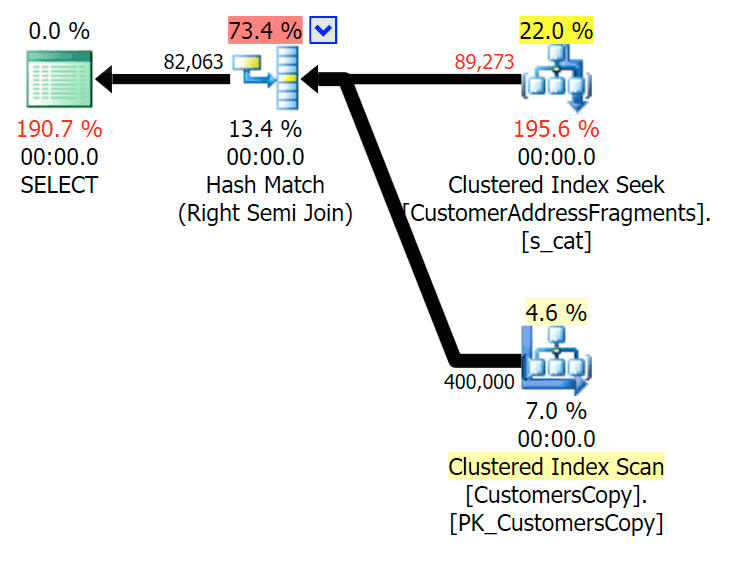 Plan for the EXISTS against the fragments table
Plan for the EXISTS against the fragments table899 Valentova Road will have two rows in the fragments table that start with va (case sensitivity aside). So you'll match on both Fragment = N'Valentova Road' and Fragment = N'va Road'. I'll save you the searching and provide a single example of many:
SELECT TOP (2) c.CustomerID, c.DeliveryAddressLine2, f.Fragment
FROM Sales.CustomersCopy AS c
INNER JOIN Sales.CustomerAddressFragments AS f
ON c.CustomerID = f.CustomerID
WHERE f.Fragment LIKE N'va%'
AND c.DeliveryAddressLine2 = N'899 Valentova Road'
AND f.CustomerID = 351;
/*
CustomerID DeliveryAddressLine2 Fragment
---------- -------------------- --------------
351 899 Valentova Road va Road
351 899 Valentova Road Valentova Road
*/This readily explains why the JOIN produces more rows; if you want to match the output of the original LIKE query, you should use EXISTS. The fact that the correct results can usually also be obtained in a less resource-intensive way is just a bonus. (I'd be nervous to see people choose the JOIN if that were the repeatedly more efficient option - you should always favor correct results over worrying about performance.)
Summary
It's clear that in this specific case - with an address column of nvarchar(60) and a max length of 26 characters - breaking up each address into fragments can bring some relief to otherwise expensive "leading wildcard" searches. The better payoff seems to happen when the search pattern is larger and, as a result, more unique. I've also demonstrated why EXISTS is better in scenarios where multiple matches are possible - with a JOIN, you will get redundant output unless you add some "greatest n per group" logic.
Caveats
I will be the first to admit that this solution is imperfect, incomplete, and not thoroughly fleshed out:
- You'll need to keep the fragments table synchronized with the base table using triggers - simplest would be for inserts and updates, delete all rows for those customers and re-insert them, and for deletes obviously remove the rows from the fragments table.
- As mentioned, this solution worked better for this specific data size, and may not do so well for other string lengths. It would warrant further testing to ensure it is appropriate for your column size, average value length, and typical search parameter length.
- Since we will have a lot of copies of fragments like "Crescent" and "Street" (never mind all the same or similar street names and house numbers), could further normalize it by storing each unique fragment in a fragments table, and then yet another table that acts as a many-to-many junction table. That would be a lot more cumbersome to set up, and I'm not quite sure there would be much to gain.
- I didn't fully investigate page compression yet, it seems that - at least in theory - this could provide some benefit. I also have a feeling a columnstore implementation may be beneficial in some cases, too.
Anyway, all that said, I just wanted to share it as a developing idea, and solicit any feedback on its practicality for specific use cases. I can dig into more specifics for a future post if you can let me know what aspects of this solution interest you.
32 thoughts on “One way to get an index seek for a leading %wildcard”
Comments are closed.

Aaron, what about using a tally table for this same effect? Although I kinda like the idea of the recursive cte, a tally table approach may be better performance wise?
Well, I don't think it really matters, it took 4 minutes to populate 7 million rows and that's the part you only do once – and that had a lot more to do with the writing and logging of the data, not the generation of the fragments. After configuration, the only time you're going to be performing that operation is when adding or changing a new string value.
Feel free to test it if you like, but I don't suspect a numbers table will perform noticeably better for this type of operation (the way it would for, say, a very large range of dates, or a string much, much larger than 60 characters – and actually the largest string in this address table was only 26 characters). And as I mentioned in the post, the practicality of this solution is likely to diminish quite rapidly as the sdtrings get larger, and again that has very little to do with how you're generating the individual fragments.
Kinda like so Aaron:
SELECT e.* FROM [dbo].[Employee] e
CROSS APPLY (
SELECT SUBSTRING(e.LastName, t.[Number], LEN(@like)) AS part
FROM [#tally] t
) t
WHERE t.[part] = @like
Oh you mean for the query itself – yeah I'm still pretty sure that will perform worse, possibly even slower than the original scan using LIKE.
Please note the recursive CTE in the post above is *just* to explode the fragments, and isn't used *in the actual query.* The actual query to find matches can perform a seek without having to do any kind of parsing or CTEs or anything.
By all means, feel free to test it, but at scale I don't think using a numbers table to parse the original string to find a substring match is going to be very efficient.
Aaron,
This has nothing to do with the point of the article, but do you really like:
SELECT Fragment = SUBSTRING(@input, x, LEN(@input))
more than:
SELECT SUBSTRING(@input, x, LEN(@input)) AS Fragment
Never mind.
I just found https://sqlblog.org/blogs/aaron_bertrand/archive/2012/01/23/bad-habits-to-kick-using-as-instead-of-for-column-aliases.aspx
where you say you think the alias = expression syntax is more readable (I can see that, but you can line up the names and aliases on the right, too).
You mean you would go out of your way to format your select list like this?
SELECT ID, (MAX(COALESCE(CHARINDEX('a', Column1),0) AS Column2, ISNULL(Column3, Column4) AS Column5, Column6, DATEADD(DAY, 1, GETDATE()) AS Column7, (some expression that wraps multiple lines and ends up on the second line) AS Column8 FROM dbo.[table];All so you could use
ASinstead of=? Do you find that more or less readable? This is totally subjective of course, but I'm not sure I can envision a scenario where some variation of aligning column aliases on the right could make the alias list more readable than one where they align on the left. So, yeah, I definitely continue to prefer alias = column/expression (even though it is not ANSI standard), because in this case readability is far more important to me than the risk of SQL Server ever not allowing this syntax.Hi Aaron,
Thanks for the reply.
Well, I wouldn't right-justify the expressions. Just tab to the AS xxx (and wrap multi-line expressions short of the "AS" position, if possible).
I've adopted the "AS" syntax (because it's ANSI standard, and because I thought it was what MS preferred, and thus, safer for the future), but I'm definitely not religious about it.
I still don't agree that using "AS" is a "bad habit", but I can see the advantages of your style choice.
I'm also not persuaded by people who say the "=" syntax confuses people about it possibly being an assignment or a Boolean expression. People who are confused in that way shouldn't be in my code. :-)
But even if you don't right-justify the expressions, it doesn't change how far over to the right your eyes have to go to find the aliases. Easily 99 out of 100 times when I'm parsing a SELECT list it's to examine a specific column or alias, not an expression, so I simply see no benefit to putting the expression first. Or making it inconsistent where the aliases will line up on the screen (with aliases first, they can always be 2 or 4 characters from the margin, with the expressions involved in any specific statement no longer being a relevant variable).
As for the "bad habit" – my series is a collection of bad habits and best practices, but that prefix ate up too much real estate in the title. This is certainly one of my more controversial opinions but I stand by it 100%.
Super, thanks for sharing idea! I was puzling about like "%abc%" searches for a while!
You are quite right Aaron. I got so caught up in the pleasure of writing the query that I did not take a hard look at how it would work until after I had written it. :)
I've found some developers, and especially developers without a ton of SQL experience, tend to get confused by the alias-equals-sign-expression syntax you prefer, mostly around what is an actual assignment vs. what is an alias assignment. I find these folks tend to be much more self supporting with the column-AS-alias syntax (meaning questions are reduced to more meaningful problems). And — since it's ANSI SQL — that's become our stock recommendation. Though we still have one or two that insist on doing it the old way (and one still insists on using the ANSI-89 join-predicate-in-the-where-clause style as well.
As always, YMMV.
So do they also get confused with
SELECT @variable = value;? And when you say'string constant' AS aliasisn't that more like actual assignment than alias assignment? Like you say, YMMV, but citing confusion over something that can be taught quite easily as the only barrier doesn't seem all that strong to me. The ANSI argument is much better (but in this specific case I still rank readability much, much higher). Anyway this is absolutely veering off track from the point of the article.I concur with Aaron on "alias = column/expression" being generally preferred. Also, this approach lends itself to consistent placement of the commas at the beginning of the line between elements, making them easily distinguishable from the commas that are part of the expressions.
I've found practices like these especially helpful when trying to debug code in the middle of the night.
Aaron,
Sorry I brought this up and derailed the comments.
I do think these style choices are interesting, and I like to learn about what works best for others. And, often, it's amusing to see how strident people can get about their preferences.
But, again, I didn't mean to distract from the actual article, which is interesting and I've been tempted to try similar things when users insist on searching for non-leading substrings in large tables.
In Gil's defense:
There are several good and free SQL formatting tools that can be added to SSMS to line things up with a key-combo or mouse clicks, so there really doesn't need to be any great effort to line things up. Arguments can be made for both, and style standards should just be decided upon and enforced.
Of course. But note my argument isn't about lining anything up at all, it's about having to go to some arbitrary place over on the right to find the alias I'm interested in. In other words, my issue is that I have to parse expressions and constants in order to arrive at
AS whatever, and that parsing will be of varying and arbitrary widths depending on the statements. The fact that tools can make it easier to form such a block of code with consistent lining might ease someone's pain as they're writing it the first time, but it doesn't really ease anyone's pain that has to read it later. And since most code is "write once, read a lot"…Anyway, I'm not trying to impose my standard on anyone, just explaining my preference and priorities.
Thanks! Always good to have different views to keep in my arsenal of experiences to draw from…
So… Elasticsearch? :)
They may share a couple of logical concepts but, no, this is not an attempt at any sort of Elasticsearch implementation.
Of course — I just meant that maybe when you reach this point it's time to use an existing tool.
Although it's very interesting how much can be achieved with SQL Server alone.
Maybe, but that sounds like an awful lot of investment in architecture, platform change, and data migration to solve wildcard searches that might not even be a significant portion of the workload.
Agreed, it of course depends on the use case. And naturally I'm not talking about a full migration, just adding an additional tool for this purpose, while leaving everything else in SQL.
If a system is doing a lot of such text searches, and it's a critical business function, it can be a great addition.
Thanks! Always good to have different views to keep in my arsenal of experiences to draw from…
How about, instead of exploding it out like that, just create a computed column using the reverse function and index that? Then search for the value in reverse with a wildcard. I haven't tried it, but it seems promising.
Andy, REVERSE() works for LIKE '%foo' but not for LIKE '%foo%'.
See the same comment from Yavor here:
https://sqlperformance.com/2017/02/sql-performance/follow-up-1-leading-wildcard-seeks
Thank you for sharing, great idea and post!
Maybe part of the confusion is "leading %wildcard" in the title of the article.
Perhaps it should have been "surrounding %wildcards%" or something like that.
Maybe, but as the article explains, the trailing wildcard (on its own or as part of a surround) isn't the problem, only the leading wildcard is the problem. The solution solves the *leading* wildcard issue, whether there is a trailing wildcard or not.
Fun problem! Got me wondering about other ways to solve it.
Maybe something like this would work to trade off some storage requirements for a loss in performance?
Char CustId Position
1 61 1
6 61 2
9 61 3
5 61 4
' ' 61 5
H 61 6
U 61 7
D 61 8
E 61 9
C 61 10
O 61 11
V 61 12
A 61 13
' ' 61 14
A 61 15
V 61 16
E 61 17
N 61 18
U 61 19
E 61 20
1 181 1
8 181 2
4 181 3
6 181 4
' ' 181 5
H 181 6
U 181 7
D 181 8
E 181 9
C 181 10
O 181 11
V 181 12
A 181 13
' ' 181 14
C 181 15
R 181 16
E 181 17
S 181 18
C 181 19
E 181 20
N 181 21
T 181 22
Then have an SP that accepts the search string as a arg.
The SP contains a recursive CTE that seeds with where Char = first Char and recursively joins additional rows using all three fields: Next Char from arg, ID from prior cte row, and Position+1 from prior cte row.
The CTE would probably need one more field to maintain the current position within the original search string argument.
Thanks for the article!
What are the issues when full text CONTAINS statements are used with parameters like these against varchar (225) varchar (400) columns like this:
@DerivedTable01_BORROWER_FULL_NAMES114='"DIXON,r*"',@DerivedTable01_OWNER_FULL_NAMES135='"DIXON,r*"'
CONTAINS(AccountOwnershipDocSummary02.BORROWER_FULL_NAMES, '"Leslie*" AND "M*" AND "Opat*"') OR ( CONTAINS(AccountOwnershipDocSummary02.OWNER_FULL_NAMES, '"Leslie*" AND "M*" AND "Opat*"'
Hmm, not sure Randall, admittedly I have very little experience with full-text search. Maybe another reader can chime in…