
Pattern Matching : More Fun When I Was a Kid
 Growing up, I loved games that tested memory and pattern matching skills. Several of my friends had Simon, while I had a knock-off called Einstein. Others had an Atari Touch Me, which even back then I knew was a questionable naming decision. These days, pattern matching means something much different to me, and can be an expensive part of everyday database queries.
Growing up, I loved games that tested memory and pattern matching skills. Several of my friends had Simon, while I had a knock-off called Einstein. Others had an Atari Touch Me, which even back then I knew was a questionable naming decision. These days, pattern matching means something much different to me, and can be an expensive part of everyday database queries.
I recently came across a couple of comments on Stack Overflow where a user was stating, as if as fact, that CHARINDEX performs better than LEFT or LIKE. In one case, the person cited an article by David Lozinski, "SQL: LIKE vs SUBSTRING vs LEFT/RIGHT vs CHARINDEX." Yes, the article shows that, in the contrived example, CHARINDEX performed best. However, since I am always skeptical about blanket statements like that, and couldn't think of a logical reason why one string function would always perform better than another, with all else being equal, I ran his tests. Sure enough, I had repeatably different results on my machine (click to enlarge):
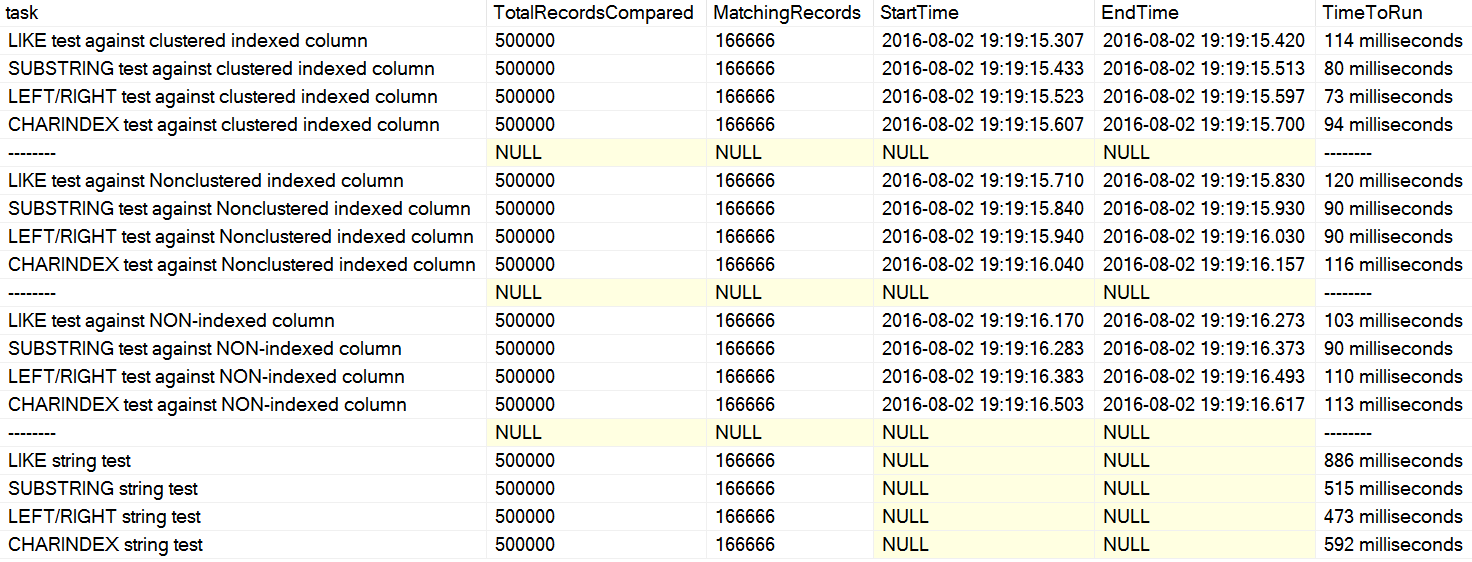 On my machine, CHARINDEX was slower than LEFT/RIGHT/SUBSTRING.
On my machine, CHARINDEX was slower than LEFT/RIGHT/SUBSTRING.
David's tests were basically comparing these query structures – looking for a string pattern either at the beginning or end of a column value – in terms of raw duration:
WHERE Column LIKE @pattern + '%'
OR Column LIKE '%' + @pattern;
WHERE SUBSTRING(Column, 1, LEN(@pattern)) = @pattern
OR SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)) = @pattern;
WHERE LEFT(Column, LEN(@pattern)) = @pattern
OR RIGHT(Column, LEN(@pattern)) = @pattern;
WHERE CHARINDEX(@pattern, SUBSTRING(Column, 1, LEN(@pattern)), 0) > 0
OR CHARINDEX(@pattern, SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)), 0) > 0;
Just looking at these clauses, you can see why CHARINDEX might be less efficient – it makes multiple additional functional calls the other approaches don't have to perform. Why this approach performed best on David's machine, I'm not sure; maybe he ran the code exactly as posted, and didn't really drop buffers between tests, such that the latter tests benefited from cached data.
In theory, CHARINDEX could have been expressed more simply, e.g.:
WHERE CHARINDEX(@pattern, Column) = 1
OR CHARINDEX(@pattern, Column) = LEN(Column) - LEN(@pattern) + 1;
(But this actually performed even worse in my casual tests.)
And why these are even OR conditions, I'm not sure. Realistically, most of the time you're doing one of two types of pattern searches: starts with or contains (it is far less common to be looking for ends with). And in most of those cases, the user tends to state up front whether they want starts with or contains, at least in every application I've been involved with in my career.
It makes sense to separate those out as separate types of queries, instead of using an OR conditional, since starts with can make use of an index (if one exists that is suitable enough for a seek, or is skinnier than the clustered index), while ends with cannot (and OR conditions tend to throw wrenches at the optimizer in general). If I can trust LIKE to use an index when it can, and to perform as good as or better than the other solutions above in most or all cases, then I can make this logic very easy. A stored procedure can take two parameters – the pattern being searched for, and the type of search to perform (generally there are four types of string matching – starts with, ends with, contains, or exact match).
CREATE PROCEDURE dbo.Search
@pattern nvarchar(100),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
-- latter two are supported but won't be tested here
AS
BEGIN
SET NOCOUNT ON;
SELECT ...
WHERE Column LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
This handles each potential case without using dynamic SQL; the OPTION (RECOMPILE) is there because you wouldn't want a plan optimized for "ends with" (which almost certainly will need to scan) to be reused for a "starts with" query, or vice-versa; it will also ensure that estimates are correct ("starts with S" probably has much different cardinality from "starts with QX"). Even if you have a scenario where users choose one type of search 99% of the time, you could use dynamic SQL here instead of recompile, but in that case you would still be vulnerable to parameter sniffing. In many conditional logic queries, recompile and/or full-on dynamic SQL are often the most sensible approach (see my post about "the Kitchen Sink").
The Tests
Since I have recently started looking at the new WideWorldImporters sample database, I decided to run my own tests there. It was hard finding a decent-sized table without a ColumnStore index or a temporal history table, but Sales.Invoices, which has 70,510 rows, has a simple nvarchar(20) column called CustomerPurchaseOrderNumber that I decided to use for the tests. (Why it's nvarchar(20) when every single value is a 5-digit number, I have no idea, but pattern matching doesn't really care if the bytes underneath represent numbers or strings.)
| Sales.Invoices CustomerPurchaseOrderNumber |
||
|---|---|---|
| Pattern | # of Rows | % of Table |
| Starts with "1" | 70,505 | 99.993% |
| Starts with "2" | 5 | 0.007% |
| Ends with "5" | 6,897 | 9.782% |
| Ends with "30" | 749 | 1.062% |
I poked around at the values in the table to come up with multiple search criteria that would produce vastly different numbers of rows, hopefully to reveal any tipping point behavior with a given approach. At right are the search queries I landed on.
I wanted to prove to myself that the above procedure was undeniably better overall for all possible searches than any of the queries that use OR conditionals, regardless of whether they use LIKE, LEFT/RIGHT, SUBSTRING, or CHARINDEX. I took David's basic query structures and put them in stored procedures (with the caveat that I can't really test "contains" without his input, and that I had to make his OR logic a little more flexible to get the same number of rows), along with a version of my logic. I also planned to test the procedures with and without an index I would create on the search column, and under both a warm and a cold cache.
The procedures:
CREATE PROCEDURE dbo.David_LIKE
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CustomerPurchaseOrderNumber LIKE @pattern + N'%')
OR (@option = 'EndsWith'
AND CustomerPurchaseOrderNumber LIKE N'%' + @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0)
OR (@option = 'EndsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Aaron_Conditional
@pattern nvarchar(10),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
I also made versions of David's procedures true to his original intent, assuming the requirement really is to find any rows where the search pattern is at the beginning *or* the end of the string. I did this simply so I could compare the performance of the different approaches, exactly as he wrote them, to see if on this data set my results would match my tests of his original script on my system. In this case there was no reason to introduce a version of my own, since it would simply match his LIKE % + @pattern OR LIKE @pattern + % variation.
CREATE PROCEDURE dbo.David_LIKE_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE @pattern + N'%'
OR CustomerPurchaseOrderNumber LIKE N'%' + @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern
OR SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OR RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0
OR CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0
OPTION (RECOMPILE);
END
GO
With the procedures in place, I could generate the testing code – which is often as much fun as the original problem. First, a logging table:
DROP TABLE IF EXISTS dbo.LoggingTable;
GO
SET NOCOUNT ON;
CREATE TABLE dbo.LoggingTable
(
LogID int IDENTITY(1,1),
prc sysname,
opt varchar(10),
pattern nvarchar(10),
frame varchar(11),
duration int,
LogTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME()
);
Then the code that would perform select operations using the various procedures and arguments:
SET NOCOUNT ON;
;WITH prc(name) AS
(
SELECT name FROM sys.procedures
WHERE LEFT(name,5) IN (N'David', N'Aaron')
),
args(opt,pattern) AS
(
SELECT 'StartsWith', N'1'
UNION ALL SELECT 'StartsWith', N'2'
UNION ALL SELECT 'EndsWith', N'5'
UNION ALL SELECT 'EndsWith', N'30'
),
frame(w) AS
(
SELECT 'BeforeIndex'
UNION ALL SELECT 'AfterIndex'
),
y AS
(
-- comment out lines 2-4 here if we want warm cache
SELECT cmd = 'GO
DBCC FREEPROCCACHE() WITH NO_INFOMSGS;
DBCC DROPCLEANBUFFERS() WITH NO_INFOMSGS;
GO
DECLARE @d datetime2, @delta int;
SET @d = SYSUTCDATETIME();
EXEC dbo.' + prc.name + ' @pattern = N'''
+ args.pattern + '''' + CASE
WHEN prc.name LIKE N'%_Original' THEN ''
ELSE ',@option = ''' + args.opt + '''' END + ';
SET @delta = DATEDIFF(MICROSECOND, @d, SYSUTCDATETIME());
INSERT dbo.LoggingTable(prc,opt,pattern,frame,duration)
SELECT N''' + prc.name + ''',''' + args.opt + ''',N'''
+ args.pattern + ''',''' + frame.w + ''',@delta;
',
*, rn = ROW_NUMBER() OVER
(PARTITION BY frame.w ORDER BY frame.w DESC,
LEN(prc.name), args.opt DESC, args.pattern)
FROM prc CROSS JOIN args CROSS JOIN frame
)
SELECT cmd = cmd + CASE WHEN rn = 36 THEN
CASE WHEN w = 'BeforeIndex'
THEN 'CREATE INDEX testing ON '+
'Sales.Invoices(CustomerPurchaseOrderNumber);
' ELSE 'DROP INDEX Sales.Invoices.testing;' END
ELSE '' END--, name, opt, pattern, w, rn
FROM y
ORDER BY w DESC, rn;
Results
I ran these tests on a virtual machine, running Windows 10 (1511/10586.545), SQL Server 2016 (13.0.2149), with 4 CPUs and 32 GB of RAM. I ran each set of tests 11 times; for the warm cache tests, I threw out the first set of results because some of those were truly cold cache tests.
I struggled with how to graph the results to show patterns, mostly because there simply were no patterns. Nearly every method was the best in one scenario and the worst in another. In the following tables, I highlighted the best- and worst-performing procedure for each column, and you can see that the results are far from conclusive:
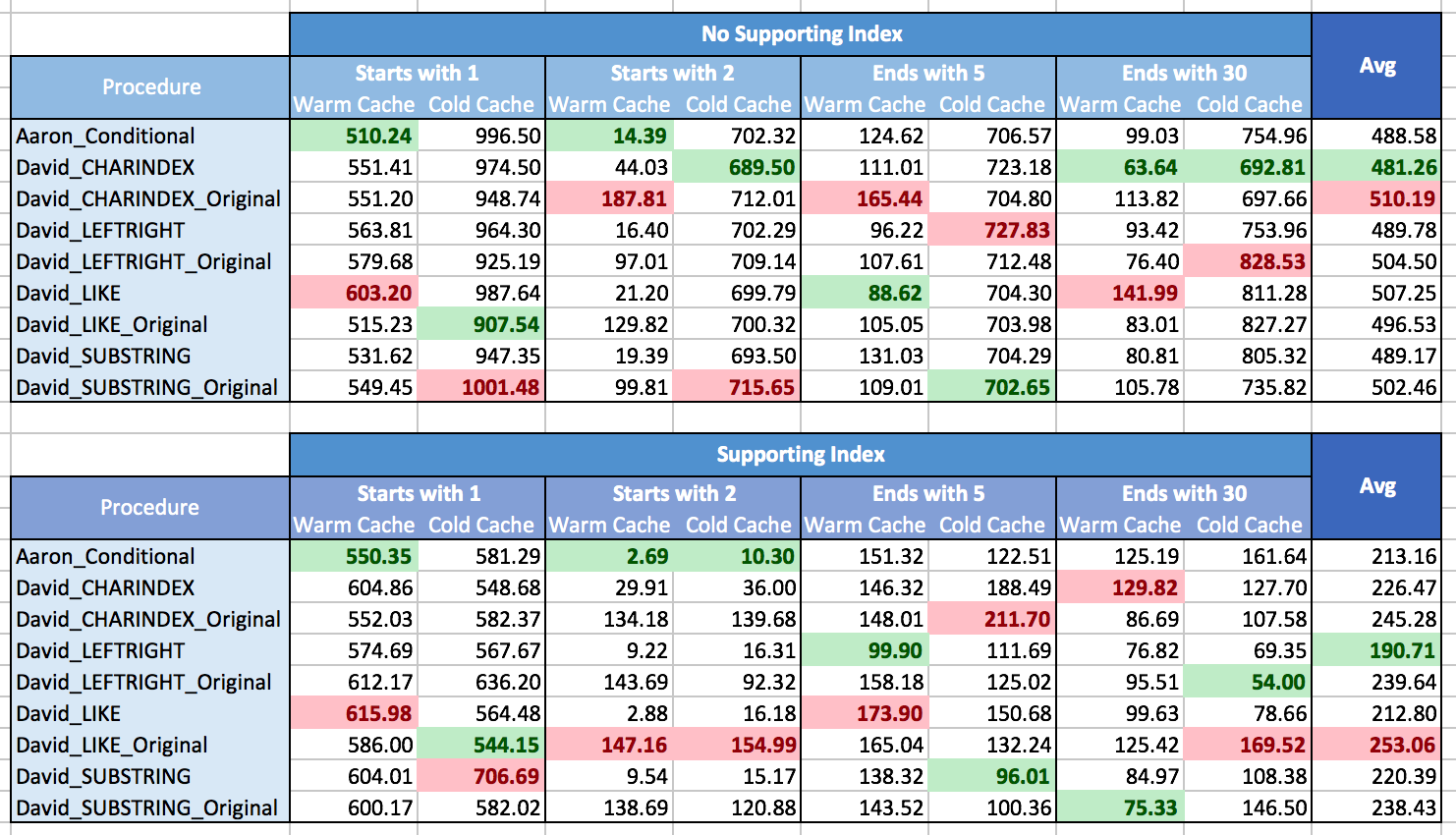 In these tests, sometimes CHARINDEX won, and sometimes it didn't.
In these tests, sometimes CHARINDEX won, and sometimes it didn't.
What I've learned is that, on the whole, if you are going to be facing many different situations (different types of pattern matching, with a supporting index or not, data can't always be in memory), there really is no clear winner, and the range of performance on average is pretty small (in fact, since a warm cache didn't always help, I would suspect the results were affected more by the cost of rendering the results than retrieving them). For individual scenarios, don't rely on my tests; run some benchmarks yourself given your hardware, configuration, data, and usage patterns.
Caveats
Some things I didn't consider for these tests:
- Clustered vs. non-clustered. Since it is unlikely that your clustered index will be on a column where you are performing pattern matching searches against the beginning or the end of the string, and since a seek will be largely the same in both cases (and the differences between scans will largely be function of index width vs. table width), I only tested performance using a non-clustered index. If you have any specific scenarios where this difference alone makes a profound difference on pattern matching, please let me know.
- MAX types. If you are searching for strings within
varchar(max)/nvarchar(max), those can't be indexed, so unless you use computed columns to represent portions of the value, a scan will be required – whether you are looking for starts with, ends with, or contains. Whether the performance overhead correlates with the size of the string, or additional overhead is introduced simply due to the type, I didn't test.
- Full-text search. I've played with this feature here and tehre, and I can spell it, but if my understanding is correct, this could only be helpful if you are searching for whole non-stop words, and not concerned about where in the string they were found. It would not be useful if you were storing paragraphs of text and wanted to find all the ones that start with "Y," contain the word "the," or end with a question mark.
Summary
The only blanket statement I can make walking away from this test is that there are no blanket statements about what is the most efficient way to perform string pattern matching. While I am biased toward my conditional approach for flexibility and maintainability, it wasn't the performance winner in all scenarios. For me, unless I am hitting a performance bottleneck and I am pursuing all avenues, I will continue using my approach for consistency. As I suggested above, if you have a very narrow scenario and are very sensitive to small differences in duration, you'll want to run your own tests to determine which method is consistently the best performer for you.
10 thoughts on “Pattern Matching : More Fun When I Was a Kid”
Comments are closed.

Thank you, Aaron, for a very interesting article.
I wonder if it might be appropriate to also consider the number of reads for the respective methods.
For example, these two simple queries return the same count of 14257 rows yet the LIKE form performs 49617 reads while the CHARINDEX form performs 49657 reads. Both queries use a non-clustered index scan with warm-cached results.
So LIKE appears to be slightly more efficient, at least in this very superficial test.
set statistics io on
select count(0) as LikeCount
from customer.customers
where firstname like '%eit%'
select count(0) as CharindexCount
from customer.customers
where charindex( 'eit', firstname ) > 0
LikeCount
———–
14257
(1 row(s) affected)
Table 'Customers'. Scan count 3, logical reads 49602
CharindexCount
————–
14257
(1 row(s) affected)
Table 'Customers'. Scan count 3, logical reads 49662
Reads are often an interesting metric, but most end users care more about duration (therefore most of the rest of us care more about duration, as well). When reads pique my interest, the deviation is a lot higher than the case you cite (a difference of about 0.12%), and should have a clear impact on duration (I bet in your case it does not).
Logical reads are not a resource. They are subsumed by the CPU resource metric. It's rarely helpful to specifically optimize logical reads.
What collation were you using for this, Aaron? Because http://sqlblog.com/blogs/rob_farley/archive/2016/03/08/how-to-make-text-searching-go-faster.aspx
I used the default for US English installations. Sure, binary collations are great for certain string operations, and it is a good point. But I didn't treat them here because not many people are willing to use them for searchable data due to downsides, such as the inability to perform case-insensitive searches, or because they already have a system set up (and changing collations can be painful).
My point here wasn't to show anyone the fastest way to search – it was to focus on the inability to know for certain whether LIKE or CHARINDEX would be faster for different scenarios, and I think collation is irrelevant here (they will be equally unpredictable in a binary collation, though I will confess I haven't explicitly confirmed that).
Even if you have a non-binary collation on a column, you can still use a binary collation for searching, which means it doesn't need to convert the string into the sortorder value first. This can be quite handy, of course… It's not indexed by the binary collation, but it can move through the data much quicker. So `select charindex('d','ABCDE' collate latin1_general_bin)` should be quicker than `select charindex('d','ABCDE')` (and give different results).
That's a fascinating proposition, Rob. Have you ever tested it?
This is great stuff, Aaron. One thing I recall from early versions of SQL Server, which might no longer be true, is that many pattern matching operations with a trailing wildcard (e.g. WHERE @pattern LIKE '1%') can use an existing index, whereas those with a leading wildcard (e.g. WHERE @pattern LIKE '%1') cannot. If that behavior still holds true in SQL Server 2016, it seems like we could visualize those results (since they have consistent index-use behaviors) with separate graphs for the columns named "Starts With" and those named "Ends With". Thoughts? I'd be interested to see if some sort of trend is more visible under that division of data?
If you are only searching for the pattern at the start and at the end of the string you can create another column with the reverse character order.
You can create one index for each column and search by the pattern and reverse pattern respectively
Yes, that is true. Again, I wasn't trying to show the most efficient way to perform a search. I was just trying to illustrate that CHARINDEX doesn't have a reliably consistent performance advantage over other string parsing methods like LEFT and LIKE.