



T-SQL Tuesday #78 is being hosted by Wendy Pastrick, and the challenge this month is simply to "learn something new and blog about it." Her blurb leans toward new features in SQL Server 2016, but since I've blogged and presented about many of those, I thought I would explore something else first-hand that I've always been genuinely curious about.
I've seen multiple people state that a heap can be better than a clustered index for certain scenarios. I cannot disagree with that. One of the interesting reasons I've seen stated, though, is that a RID Lookup is faster than a Key Lookup. I'm a big fan of clustered indexes and not a huge fan of heaps, so I felt this needed some testing.
So, let's test it!
I thought it would be good to create a database with two tables, identical except that one had a clustered primary key, and the other had a non-clustered primary key. I would time loading some rows into the table, updating a bunch of rows in a loop, and selecting from an index (forcing either a Key or RID Lookup).
System Specs
This question often comes up, so to clarify the important details about this system, I'm on an 8-core VM with 32 GB of RAM, backed by PCIe storage. SQL Server version is 2014 SP1 CU6, with no special configuration changes or trace flags running:
Apr 13 2016 12:41:07
Copyright (c) Microsoft Corporation
Developer Edition (64-bit) on Windows NT 6.3 <X64> (Build 10586: ) (Hypervisor)
The Database
I created a database with plenty of free space in both the data and log file in order to prevent any autogrow events from interfering with the tests. I also set the database to simple recovery to minimize the impact on the transaction log.
CREATE DATABASE HeapVsCIX ON
(
name = N'HeapVsCIX_data',
filename = N'C:\...\HeapCIX.mdf',
size = 100MB, filegrowth = 10MB
)
LOG ON
(
name = N'HeapVsCIX_log',
filename = 'C:\...\HeapCIX.ldf',
size = 100MB, filegrowth = 10MB
);
GO
ALTER DATABASE HeapVsCIX SET RECOVERY SIMPLE;
The Tables
As I said, two tables, with the only difference being whether the primary key is clustered.
CREATE TABLE dbo.ObjectHeap
(
ObjectID int PRIMARY KEY NONCLUSTERED,
Name sysname,
SchemaID int,
ModuleDefinition nvarchar(max)
);
CREATE INDEX oh_name ON dbo.ObjectHeap(Name) INCLUDE(SchemaID);
CREATE TABLE dbo.ObjectCIX
(
ObjectID INT PRIMARY KEY CLUSTERED,
Name sysname,
SchemaID int,
ModuleDefinition nvarchar(max)
);
CREATE INDEX oc_name ON dbo.ObjectCIX(Name) INCLUDE(SchemaID);
A Table For Capturing Runtime
I could monitor CPU and all of that, but really the curiosity is almost always around runtime. So I created a logging table to capture the runtime of each test:
CREATE TABLE dbo.Timings
(
Test varchar(32) NOT NULL,
StartTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME(),
EndTime datetime2
);
The Insert Test
So, how long does it take to insert 2,000 rows, 100 times? I'm grabbing some pretty basic data from sys.all_objects, and pulling the definition along for any procedures, functions, etc.:
INSERT dbo.Timings(Test) VALUES('Inserting Heap');
GO
TRUNCATE TABLE dbo.ObjectHeap;
INSERT dbo.ObjectHeap(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
-- CIX:
INSERT dbo.Timings(Test) VALUES('Inserting CIX');
GO
TRUNCATE TABLE dbo.ObjectCIX;
INSERT dbo.ObjectCIX(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
The Update Test
For the update test, I just wanted to test the speed of writing to a clustered index vs. a heap in a very row-by-row fashion. So I dumped 200 random rows into a #temp table, then built a cursor around it (the #temp table merely ensures that the same 200 rows are updated in both versions of the table, which is probably overkill).
CREATE TABLE #IdsToUpdate(ObjectID int PRIMARY KEY CLUSTERED);
INSERT #IdsToUpdate(ObjectID)
SELECT TOP (200) ObjectID
FROM dbo.ObjectCIX ORDER BY NEWID();
GO
INSERT dbo.Timings(Test) VALUES('Updating Heap');
GO
-- update speed - update 200 rows 1,000 times
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectHeap SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Updating CIX');
GO
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectCIX SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
The Select Test
So, above you saw that I created an index with Name as the key column in each table; in order to evaluate the cost of performing lookups for a significant amount of rows, I wrote a query that assigns the output to a variable (eliminating network I/O and client rendering time), but forces the use of the index:
INSERT dbo.Timings(Test) VALUES('Forcing RID Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectHeap WITH (INDEX(oh_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Forcing Key Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectCIX WITH (INDEX(oc_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
For this one I wanted to show some interesting aspects of the plans before collating the test results. Running them individually head-to-head provides these comparative metrics:
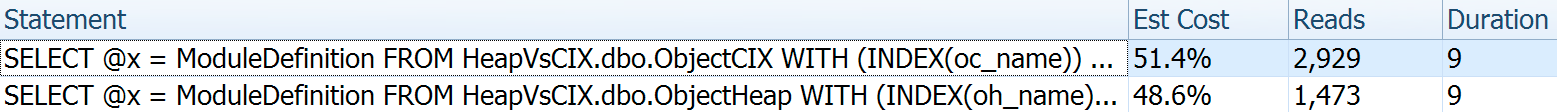
Duration is inconsequential for a single statement, but look at those reads. If you're on slow storage, that's a big difference you won't see in a smaller scale and/or on your local development SSD.
And then the plans showing the two different lookups, using SQL Sentry Plan Explorer:
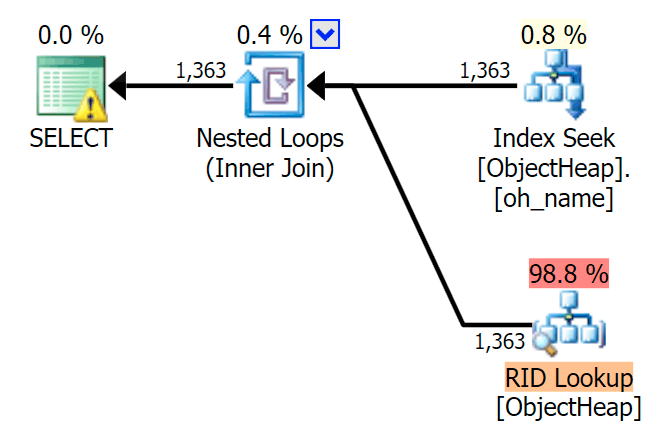
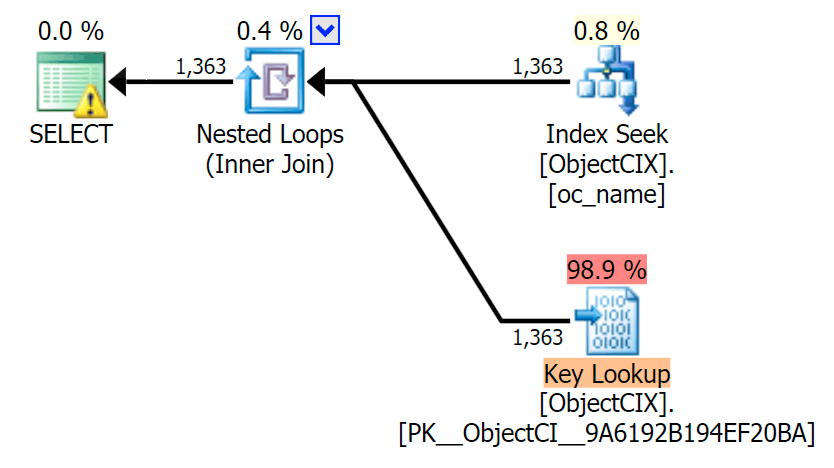
The plans look almost identical, and you might not notice the difference in reads in SSMS unless you were capturing Statistics I/O. Even the estimated I/O costs for the two lookups were similar – 1.69 for the Key Lookup, and 1.59 for the RID lookup. (The warning icon in both plans is for a missing covering index.)
It is interesting to note that if we don't force a lookup and allow SQL Server to decide what to do, it chooses a standard scan in both cases – no missing index warning, and look at how much closer the reads are:
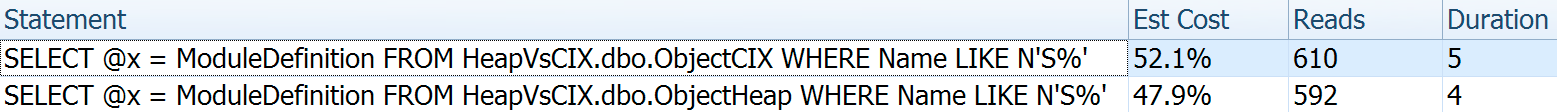
The optimizer knows that a scan will be much cheaper than seek + lookups in this case. I chose a LOB column for variable assignment merely for effect, but the results were similar using a non-LOB column as well.
The Test Results
With the Timings table in place, I was able to easily run the tests multiple times (I ran a dozen tests) and then come with averages for the tests with the following query:
SELECT Test, Avg_Duration = AVG(1.0*DATEDIFF(MILLISECOND, StartTime, EndTime))
FROM dbo.Timings GROUP BY Test;
A simple bar chart shows how they compare:
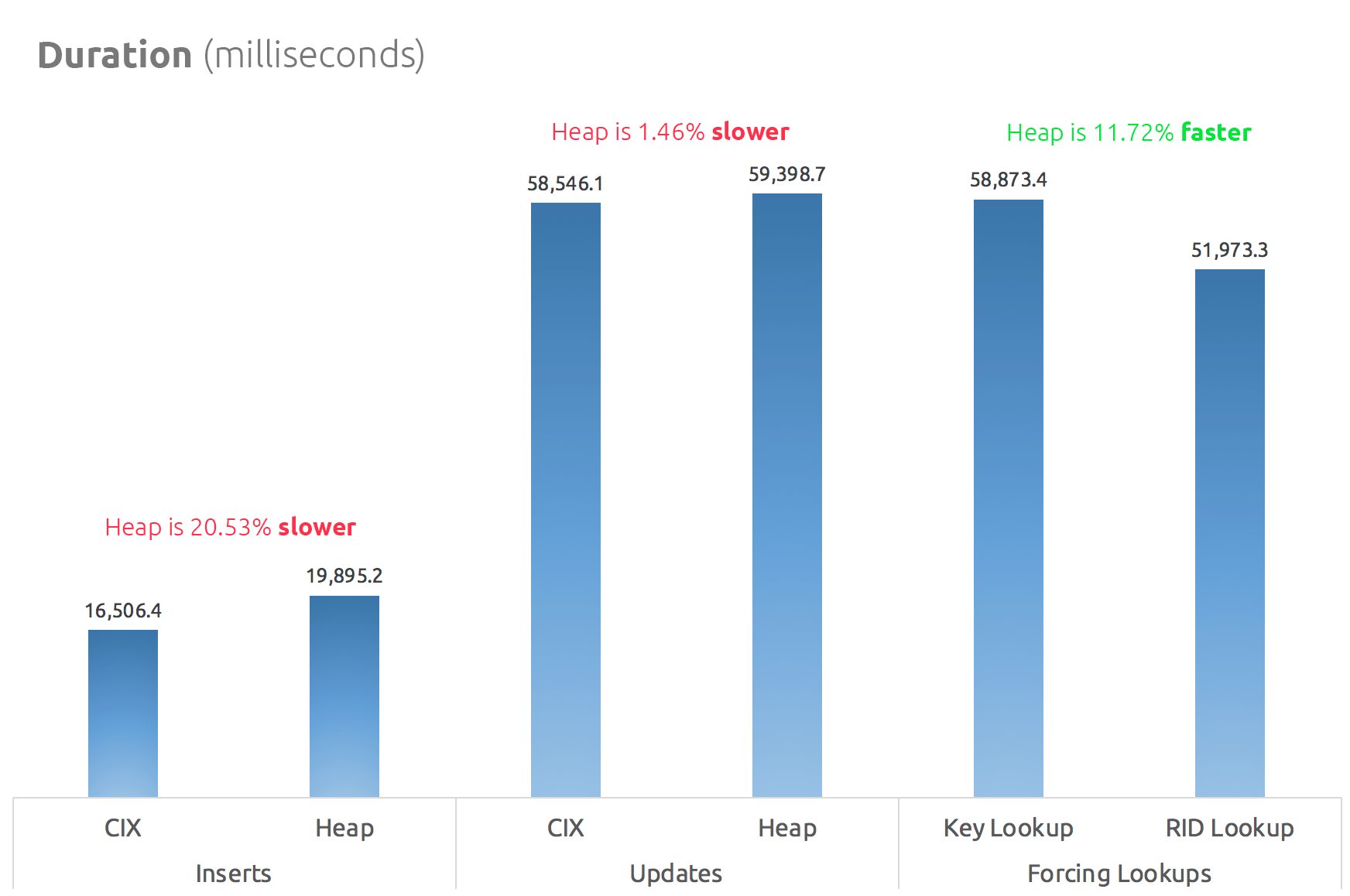
Conclusion
So, the rumors are true: in this case at least, a RID Lookup is significantly faster than a Key Lookup. Going directly to file:page:slot is obviously more efficient in terms of I/O than following the b-tree (and if you aren't on modern storage, the delta could be much more noticeable).
Whether you want to take advantage of that, and bring along all of the other heap aspects, will depend on your workload – the heap is slightly more expensive for write operations. But this is not definitive – this could vary greatly depending on table structure, indexes, and access patterns.
I tested very simple things here, and if you're on the fence about this, I highly recommend testing your actual workload on your own hardware and comparing for yourself (and don't forget to test the same workload where covering indexes are present; you will probably get much better overall performance if you can simply eliminate lookups altogether). Be sure to measure all of the metrics that are important to you; just because I focus on duration doesn't mean it's the one you need to care about most. :-)



What if you have a heap that has many forwarded entries?
Chris
You're right. I re-created the tables with a larger name column (nvarchar(450)), and continued increasing the content of that column to stuff the key length. This created a high level of fragmentation on both tables and forwarded records on the heap. Now, the RID Lookups were about 12% slower than the Key Lookups. So, the RID Lookup only performs better when the data is relatively static.
Writes can be slower in your heap test because 3 allocation units must be touched in the heap case where the CI only needs 2. That's incomparable. You need to ensure that writes take a similar path. For example, don't create an index on ID at all for the heap case. It should not be needed to accelerate queries.
So although the schema might be a little less realistic doing that at least we can compare the raw performance of heaps vs. CI better.
Did you ever consider running such tests on an Azure SQL preconfigured image? That would allow others to precisely replicate performance numbers and experiment.
I was attempting to compare realistic tables the way users would create them (with or without a clustered index, depending on whether they believed advice that heaps are better). They are not thinking about extra allocation units when creating tables because they are just creating their tables for purposes other than raw performance tests (and yes they will index ID to support point lookups).
Also, I provide schema and data population methods exactly so that anyone could do what you're suggesting – throw it up on their own hardware, Azure SQL DB, or a VM image, baseline my exact tests, then experiment on their own. I'm not trying to provide all the answers or to be perfect. :-)
I just can believe I wrote a blog post (published on the same date) speaking about exactly the same… key vs RID lookups…
How did you find things with larger tables? What if you do your updates and select on tables with 2M rows instead of 200 rows?
Kind of off the main premise; but, what, if any, is the benefit/purpose of the INCLUDE on the CIX? If I understand correctly, by the time the CIX is traversed to the leaf page all the data is available thus it should have access to all the columns making the INCLUDEd column unnecessary.
Hi Chris, not sure I follow. Where do you see an INCLUDE column defined on a clustered index?
OOPS! My Bad. I read it wrong. the CIX is on ObjectID. An additional index is on Name with the INCLUDE.
CREATE TABLE dbo.ObjectCIX
(
ObjectID INT PRIMARY KEY CLUSTERED,
Name sysname,
SchemaID int,
ModuleDefinition nvarchar(max)
);
CREATE INDEX oc_name ON dbo.ObjectCIX(Name) INCLUDE(SchemaID);
not surprising that a RID lookup is going to be faster for larger tables. when a non-clustered index seek goes for the RID, it is able to go directly to the record (assuming no forwarded records issues). in contrast, as clustered (and nonclustered) indices get more rows, the number of levels in the b-tree increases. when the key lookup reaches for a specific clustering key, it has to maneuver through more and more levels, adding to the overhead required to find the row in the clustered index.