
STRING_SPLIT() in SQL Server 2016 : Follow-Up #2
Earlier this week, I posted a follow-up to my my recent post about STRING_SPLIT() in SQL Server 2016, addressing several comments left on the post and/or sent to me directly:
After that post was mostly written, there was a late-breaking question from Doug Ellner:
Now, testing TVPs was already on my list of future projects, after a recent twitter exchange with @Nick_Craver over at Stack Overflow. He said they were excited that STRING_SPLIT() performed well, because they were unhappy with the performance of sending ~7,000 values in through a table-valued parameter.
My Tests
For these tests, I used SQL Server 2016 RC3 (13.0.1400.361) on an 8-core Windows 10 VM, with PCIe storage and 32 GB of RAM.
I created a simple table that mimicked what they were doing (selecting about 10,000 values from a 3+ million row posts table), but for my tests, it has far fewer columns and fewer indexes:
CREATE TABLE dbo.Posts_Regular
(
PostID int PRIMARY KEY,
HitCount int NOT NULL DEFAULT 0
);
INSERT dbo.Posts_Regular(PostID)
SELECT TOP (3000000) ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2;I also created an In-Memory version, because I was curious if any approach would work differently there:
CREATE TABLE dbo.Posts_InMemory
(
PostID int PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 4000000),
HitCount int NOT NULL DEFAULT 0
) WITH (MEMORY_OPTIMIZED = ON);Now, I wanted to create a C# app that would pass in 10,000 unique values, either as a comma-separated string (built using a StringBuilder) or as a TVP (passed from a DataTable). The point would be to retrieve or update a selection of rows based on a match, either to an element produced by splitting the list, or an explicit value in a TVP. So the code was written to append every 300th value to the string or DataTable (C# code is in an appendix below). I took the functions I created in the original post, altered them to handle varchar(max), and then added two functions that accepted a TVP – one of them memory-optimized. Here are the table types (the functions are in the appendix below):
CREATE TYPE dbo.PostIDs_Regular AS TABLE(PostID int PRIMARY KEY);
GO
CREATE TYPE dbo.PostIDs_InMemory AS TABLE
(
PostID int NOT NULL PRIMARY KEY NONCLUSTERED HASH
WITH (BUCKET_COUNT = 1000000)
)
WITH (MEMORY_OPTIMIZED = ON);
GOI also had to make the Numbers table bigger in order to handle strings > 8K and with > 8K elements (I made it 1MM rows). Then I created seven stored procedures: five of them taking a varchar(max) and joining with the function output in order to update the base table, and then two to accept the TVP and join directly against that. The C# code calls each of these seven procedures, with the list of 10,000 posts to select or update, 1,000 times. These procedures are also in the appendix below. So just to summarize, the methods being tested are:
- Native (
STRING_SPLIT()) - XML
- CLR
- Numbers table
- JSON (with explicit
intoutput) - Table-valued parameter
- Memory-optimized table-valued parameter
We'll test retrieving the 10,000 values, 1,000 times, using a DataReader – but not iterating over the DataReader, since that would just make the test take longer, and would be the same amount of work for the C# application regardless of how the database produced the set. We'll also test updating the 10,000 rows, 1,000 times each, using ExecuteNonQuery(). And we'll test against both the regular and memory-optimized versions of the Posts table, which we can switch very easily without having to change any of the functions or procedures, using a synonym:
CREATE SYNONYM dbo.Posts FOR dbo.Posts_Regular;
-- to test memory-optimized version:
DROP SYNONYM dbo.Posts;
CREATE SYNONYM dbo.Posts FOR dbo.Posts_InMemory;
-- to test the disk-based version again:
DROP SYNONYM dbo.Posts;
CREATE SYNONYM dbo.Posts FOR dbo.Posts_Regular;I kicked off the application, ran it several times for each combination to ensure compilation, caching, and other factors weren't being unfair to the batch executed first, and then analyzed the results from the logging table (I also spot-checked sys.dm_exec_procedure_stats to make sure none of the approaches had significant application-based overhead, and they did not).
Results – Disk-Based Tables
I struggle with data visualization sometimes – I really tried to come up with a way to represent these metrics on a single chart, but I think there were just far too many data points to make the salient ones stand out.
You can click to enlarge any of these in a new tab/window, but even if you have a small window I tried to make the winner clear through use of color (and the winner was the same in every case). And to be clear, by "Average Duration" I mean the average amount of time it took for the application to complete a loop of 1,000 operations.
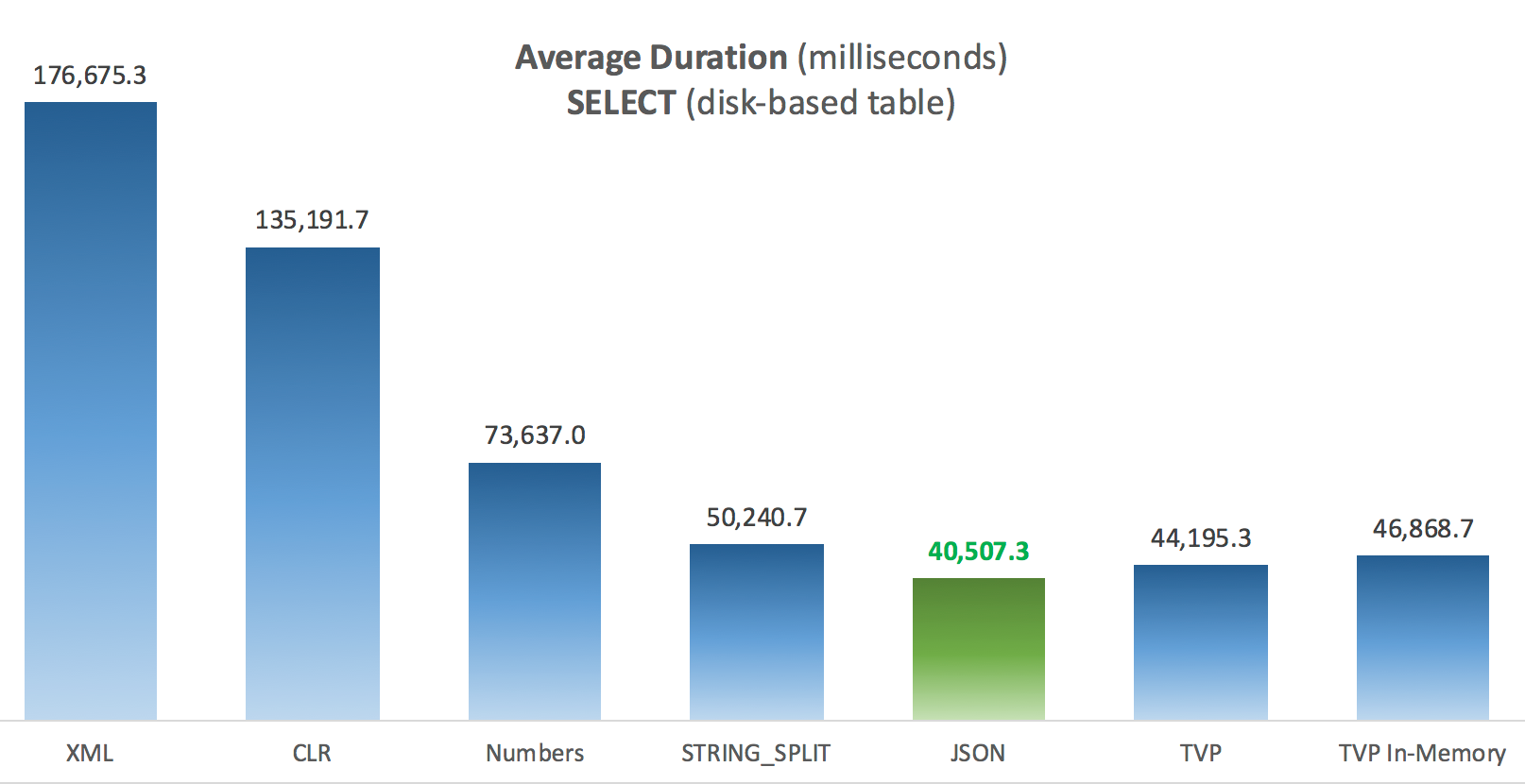 Average Duration (milliseconds) for SELECTs against disk-based Posts table
Average Duration (milliseconds) for SELECTs against disk-based Posts table
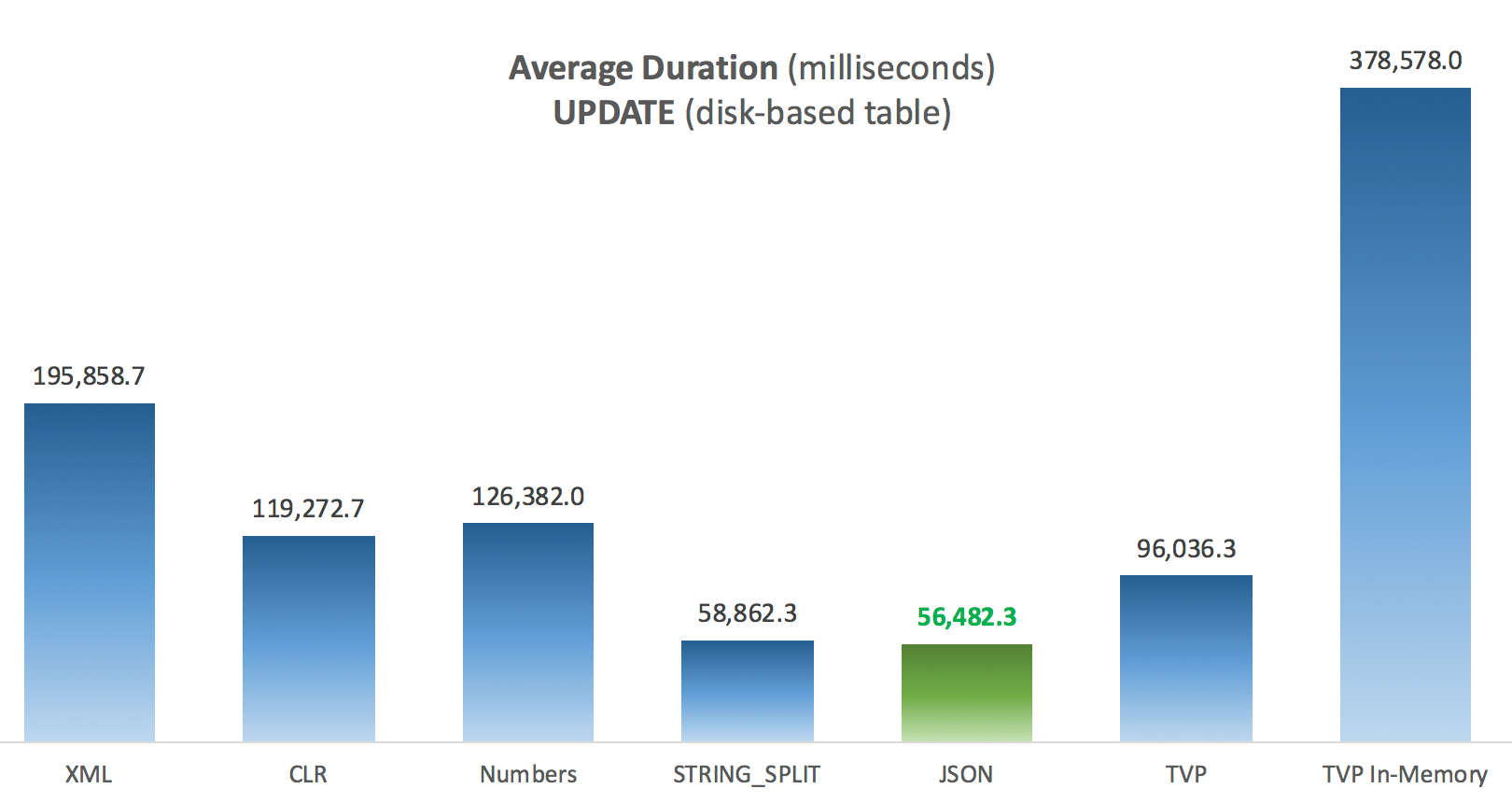 Average Duration (milliseconds) for UPDATEs against disk-based Posts table
Average Duration (milliseconds) for UPDATEs against disk-based Posts table
The most interesting thing here, for me, is how poorly the memory-optimized TVP did when assisting with an UPDATE. It turns out that parallel scans are currently blocked too aggressively when DML is involved; Microsoft has recognized this as a feature gap, and they are hoping to address it soon. Note that parallel scan is currently possible with SELECT but it is blocked for DML right now. (It will not be resolved in SQL Server 2014, as these specific parallel scan operations are not available there for any operation.) When that is fixed, or when your TVPs are smaller and/or parallelism isn't beneficial anyway, you should see that memory-optimized TVPs will perform better (the pattern just doesn't work well for this particular use case of relatively large TVPs).
For this specific case, here are the plans for the SELECT (which I could coerce to go parallel) and the UPDATE (which I could not):
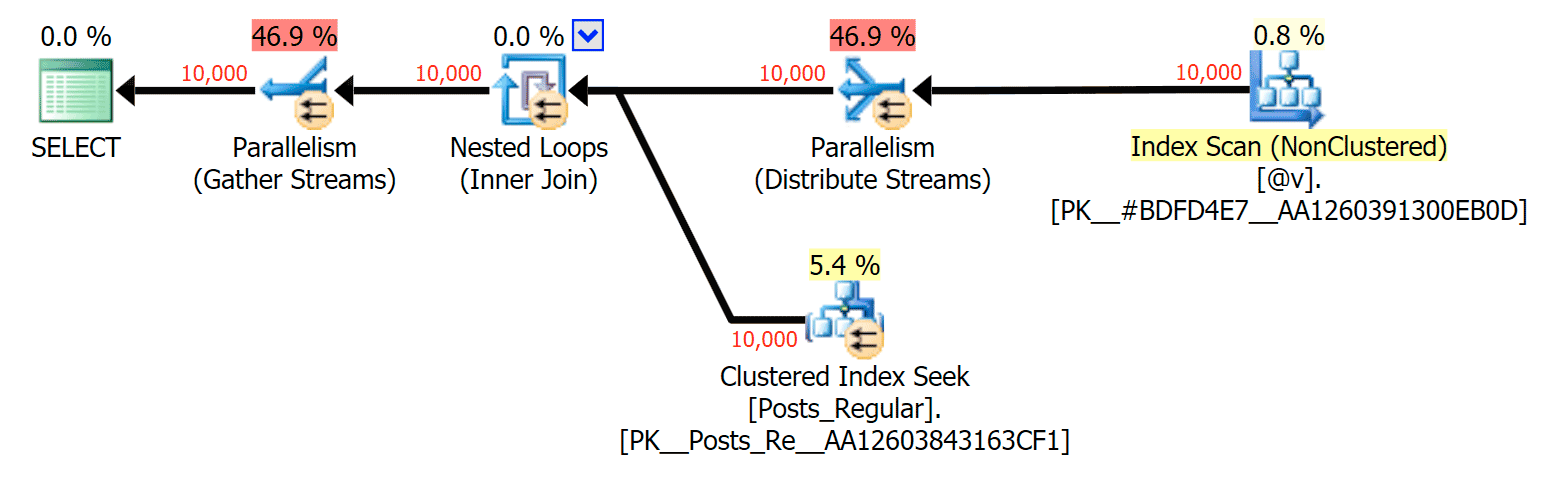 Parallelism in a SELECT plan joining a disk-based table to an in-memory TVP
Parallelism in a SELECT plan joining a disk-based table to an in-memory TVP
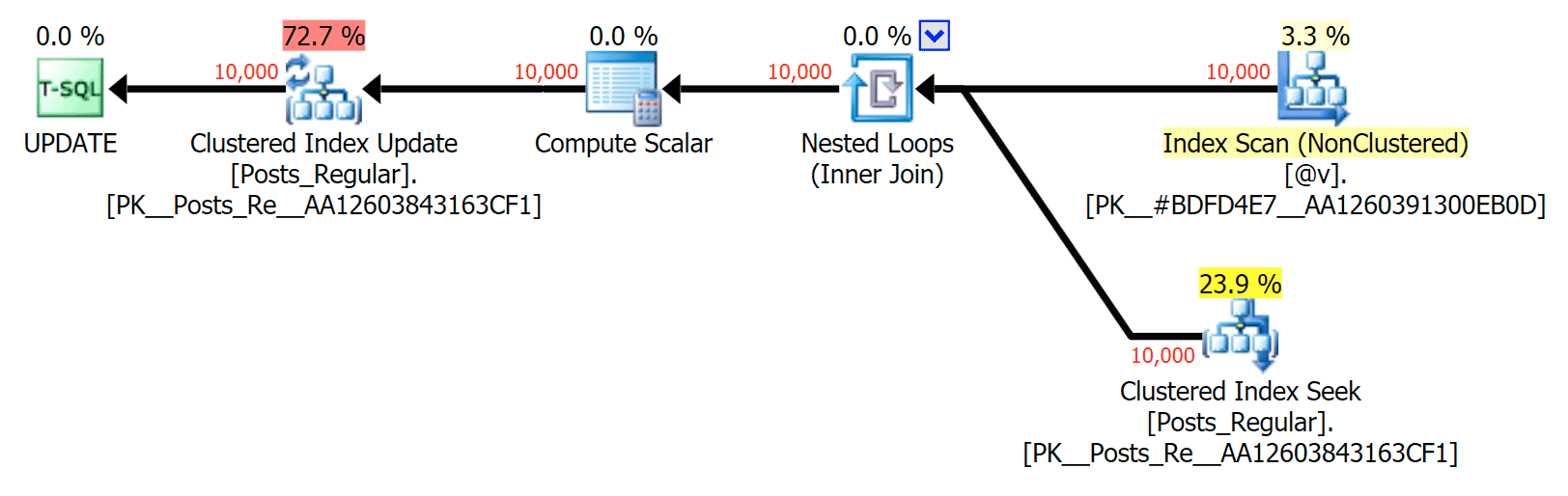 No parallelism in an UPDATE plan joining a disk-based table to an in-memory TVP
No parallelism in an UPDATE plan joining a disk-based table to an in-memory TVP
Results – Memory-Optimized Tables
A little more consistency here – the four methods on the right are relatively even, while the three on the left seem very undesirable by contrast. Also pay particular attention to absolute scale compared to the disk-based tables – for the most part, using the same methods, and even without parallelism, you end up with much quicker operations against memory-optimized tables, leading to lower overall CPU usage.
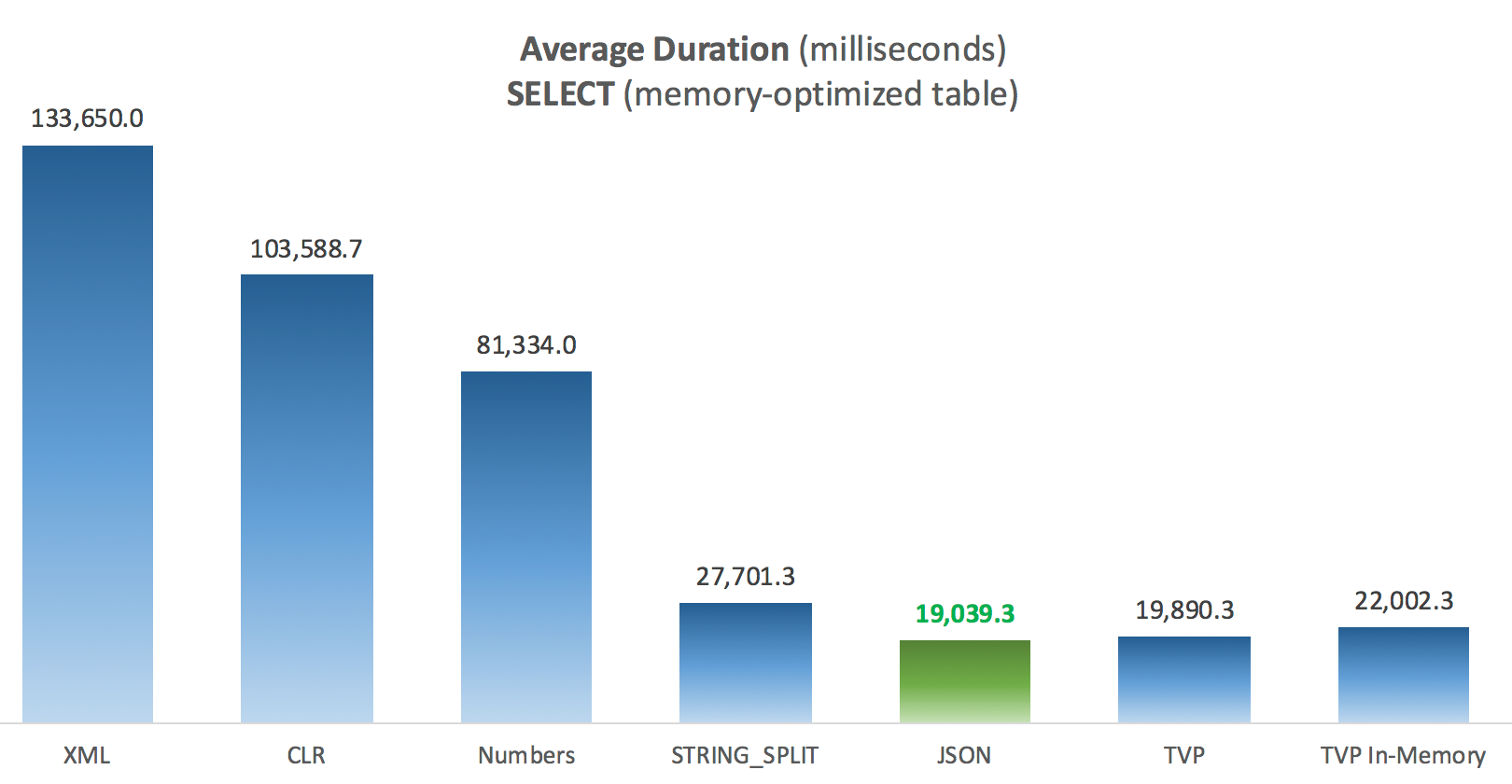 Average Duration (milliseconds) for SELECTs against memory-optimized Posts table
Average Duration (milliseconds) for SELECTs against memory-optimized Posts table
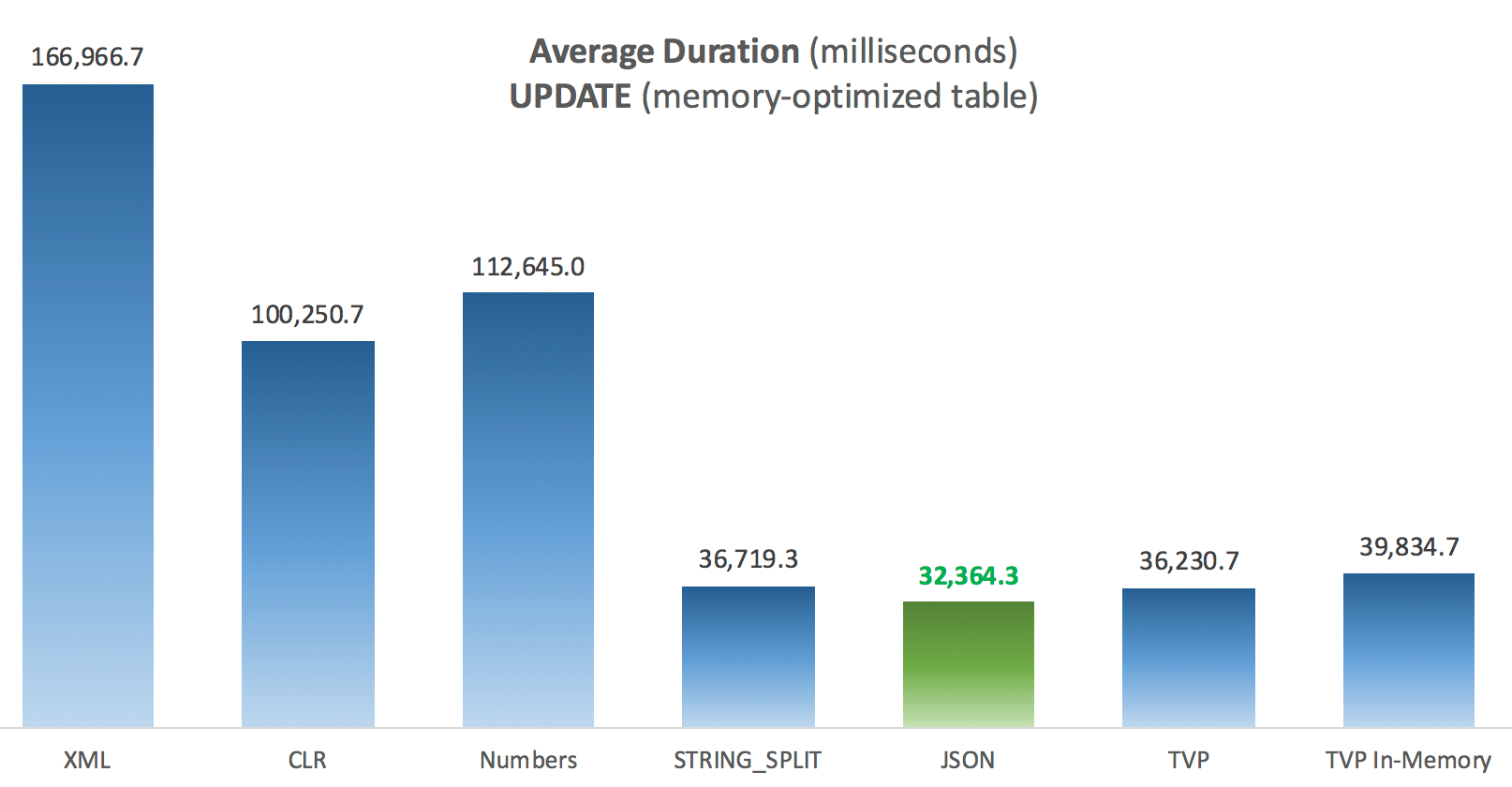 Average Duration (milliseconds) for UPDATEs against memory-optimized Posts table
Average Duration (milliseconds) for UPDATEs against memory-optimized Posts table
Conclusion
For this specific test, with a specific data size, distribution, and number of parameters, and on my particular hardware, JSON was a consistent winner (though marginally so). For some of the other tests in previous posts, though, other approaches fared better. Just an example of how what you're doing and where you're doing it can have a dramatic impact on the relative efficiency of various techniques, here are the things I've tested in this brief series, with my summary of which technique to use in that case, and which to use as a 2nd or 3rd choice (for example, if you can't implement CLR due to corporate policy or because you're using Azure SQL Database, or you can't use JSON or STRING_SPLIT() because you aren't on SQL Server 2016 yet). Note that I didn't go back and re-test the variable assignment and SELECT INTO scripts using TVPs – these tests were set up assuming you already had existing data in CSV format that would have to be broken up first anyway. Generally, if you can avoid it, don't smoosh your sets into comma-separated strings in the first place, IMHO.
| Goal | 1st choice | 2nd choice (and 3rd, where appropriate) |
|---|---|---|
| Simple variable assignment | STRING_SPLIT() | CLR if < 2016 XML if no CLR and < 2016 |
| SELECT INTO | CLR | XML if no CLR |
| SELECT INTO (no spool) | CLR | Numbers table if no CLR |
| SELECT INTO (no spool + MAXDOP 1) | STRING_SPLIT() | CLR if < 2016 Numbers table if no CLR and < 2016 |
| SELECT joining large list (disk-based) | JSON (int) | TVP if < 2016 |
| SELECT joining large list (memory-optimized) | JSON (int) | TVP if < 2016 |
| UPDATE joining large list (disk-based) | JSON (int) | TVP if < 2016 |
| UPDATE joining large list (memory-optimized) | JSON (int) | TVP if < 2016 |
For Doug's specific question: JSON, STRING_SPLIT(), and TVPs performed rather similarly across these tests on average – close enough that TVPs are the obvious choice if you're not on SQL Server 2016. If you have different use cases, these results may differ. Greatly.
Which brings us to the moral of this story: I and others may perform very specific performance tests, revolving around any feature or approach, and come to some conclusion about which approach is fastest. But there are so many variables, I will never have the confidence to say "this approach is always the fastest." In this scenario, I tried very hard to control most of the contributing factors, and while JSON won in all four cases, you can see how those different factors affected execution times (and drastically so for some approaches). So it is always worth it to construct your own tests, and I hope I have helped illustrate how I go about that sort of thing.
Appendix A : Console Application Code
Please, no nit-picking about this code; it was literally thrown together as a very simple way to run these stored procedures 1,000 times with true lists and DataTables assembled in C#, and to log the time each loop took to a table (to be sure to include any application-related overhead with handling either a large string or a collection). I could add error handling, loop differently (e.g. construct the lists inside the loop instead of reuse a single unit of work), and so on.
using System;
using System.Text;
using System.Configuration;
using System.Data;
using System.Data.SqlClient;
namespace SplitTesting
{
class Program
{
static void Main(string[] args)
{
string operation = "Update";
if (args[0].ToString() == "-Select") { operation = "Select"; }
var csv = new StringBuilder();
DataTable elements = new DataTable();
elements.Columns.Add("value", typeof(int));
for (int i = 1; i <= 10000; i++)
{
csv.Append((i*300).ToString());
if (i < 10000) { csv.Append(","); }
elements.Rows.Add(i*300);
}
string[] methods = { "Native", "CLR", "XML", "Numbers", "JSON", "TVP", "TVP_InMemory" };
using (SqlConnection con = new SqlConnection())
{
con.ConnectionString = ConfigurationManager.ConnectionStrings["primary"].ToString();
con.Open();
SqlParameter p;
foreach (string method in methods)
{
SqlCommand cmd = new SqlCommand("dbo." + operation + "Posts_" + method, con);
cmd.CommandType = CommandType.StoredProcedure;
if (method == "TVP" || method == "TVP_InMemory")
{
cmd.Parameters.Add("@PostList", SqlDbType.Structured).Value = elements;
}
else
{
cmd.Parameters.Add("@PostList", SqlDbType.VarChar, -1).Value = csv.ToString();
}
var timer = System.Diagnostics.Stopwatch.StartNew();
for (int x = 1; x <= 1000; x++)
{
if (operation == "Update") { cmd.ExecuteNonQuery(); }
else { SqlDataReader rdr = cmd.ExecuteReader(); rdr.Close(); }
}
timer.Stop();
long this_time = timer.ElapsedMilliseconds;
// log time - the logging procedure adds clock time and
// records memory/disk-based (determined via synonym)
SqlCommand log = new SqlCommand("dbo.LogBatchTime", con);
log.CommandType = CommandType.StoredProcedure;
log.Parameters.Add("@Operation", SqlDbType.VarChar, 32).Value = operation;
log.Parameters.Add("@Method", SqlDbType.VarChar, 32).Value = method;
log.Parameters.Add("@Timing", SqlDbType.Int).Value = this_time;
log.ExecuteNonQuery();
Console.WriteLine(method + " : " + this_time.ToString());
}
}
}
}
}Sample usage:
SplitTesting.exe -Update
Appendix B : Functions, Procedures, and Logging Table
Here were the functions edited to support varchar(max) (the CLR function already accepted nvarchar(max) and I was still reluctant to try to change it):
CREATE FUNCTION dbo.SplitStrings_Native( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] FROM STRING_SPLIT(@List, @Delimiter));
GO
CREATE FUNCTION dbo.SplitStrings_XML( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] = y.i.value('(./text())[1]', 'varchar(max)')
FROM (SELECT x = CONVERT(XML, '<i>' + REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')) AS a CROSS APPLY x.nodes('i') AS y(i));
GO
CREATE FUNCTION dbo.SplitStrings_Numbers( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.Numbers WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter
);
GO
CREATE FUNCTION dbo.SplitStrings_JSON( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] FROM OPENJSON(CHAR(91) + @List + CHAR(93)) WITH (value int '$'));
GOAnd the stored procedures looked like this:
CREATE PROCEDURE dbo.UpdatePosts_Native
@PostList varchar(max)
AS
BEGIN
UPDATE p SET HitCount += 1
FROM dbo.Posts AS p
INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s
ON p.PostID = s.[value];
END
GO
CREATE PROCEDURE dbo.SelectPosts_Native
@PostList varchar(max)
AS
BEGIN
SELECT p.PostID, p.HitCount
FROM dbo.Posts AS p
INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s
ON p.PostID = s.[value];
END
GO
-- repeat for the 4 other varchar(max)-based methods
CREATE PROCEDURE dbo.UpdatePosts_TVP
@PostList dbo.PostIDs_Regular READONLY -- switch _Regular to _InMemory
AS
BEGIN
SET NOCOUNT ON;
UPDATE p SET HitCount += 1
FROM dbo.Posts AS p
INNER JOIN @PostList AS s
ON p.PostID = s.PostID;
END
GO
CREATE PROCEDURE dbo.SelectPosts_TVP
@PostList dbo.PostIDs_Regular READONLY -- switch _Regular to _InMemory
AS
BEGIN
SET NOCOUNT ON;
SELECT p.PostID, p.HitCount
FROM dbo.Posts AS p
INNER JOIN @PostList AS s
ON p.PostID = s.PostID;
END
GO
-- repeat for in-memoryAnd finally, the logging table and procedure:
CREATE TABLE dbo.SplitLog
(
LogID int IDENTITY(1,1) PRIMARY KEY,
ClockTime datetime NOT NULL DEFAULT GETDATE(),
OperatingTable nvarchar(513) NOT NULL, -- Posts_InMemory or Posts_Regular
Operation varchar(32) NOT NULL DEFAULT 'Update', -- or select
Method varchar(32) NOT NULL DEFAULT 'Native', -- or TVP, JSON, etc.
Timing int NOT NULL DEFAULT 0
);
GO
CREATE PROCEDURE dbo.LogBatchTime
@Operation varchar(32),
@Method varchar(32),
@Timing int
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.SplitLog(OperatingTable, Operation, Method, Timing)
SELECT base_object_name, @Operation, @Method, @Timing
FROM sys.synonyms WHERE name = N'Posts';
END
GO
-- and the query to generate the graphs:
;WITH x AS
(
SELECT OperatingTable,Operation,Method,Timing,
Recency = ROW_NUMBER() OVER
(PARTITION BY OperatingTable,Operation,Method
ORDER BY ClockTime DESC)
FROM dbo.SplitLog
)
SELECT OperatingTable,Operation,Method,AverageDuration = AVG(1.0*Timing)
FROM x WHERE Recency <= 3
GROUP BY OperatingTable,Operation,Method;15 thoughts on “STRING_SPLIT() in SQL Server 2016 : Follow-Up #2”
Comments are closed.

Were your TVP tests using streaming TVP? Curious as that has a dramatic impact upon TVP performance. I have been quite happy with streaming TVP. In fact I get nearly the same performance as bulk insert with the additional benefit of being able to run multiple inserts at the same time.
Hi Aaron, I love your articles but this comparison looks strangely biased.
When you split strings, in every case (except JSON) you are producing collection of strings (in case of XML parsing even varchar(max) ( … see line SELECT [value] = y.i.value('(./text())[1]', 'varchar(max)') … ),
but in JSON case you are properly creating a list of integers ( … see line SELECT [value] FROM OPENJSON(CHAR(91) + @List + CHAR(93)) WITH (value int '$') ). This is why JSON is producting faster queries, since the output of that function is a collection of ints. Also CLR TVF can accept input string and delimiter but return collection of (properly typed) integers. In that case properly typed data will be a lot faster.
Hi Bosko, let me address your concerns:
(1) This is not biased at all. Splitting a list of integers is actually quite common, for any web interface smart enough to pass the surrogate values (e.g. from checkboxes/dropdowns) as opposed to the much more expensive string labels. And in fact these tests came about precisely because of the real scenario Stack Exchange was having with parsing a comma-separated list of integers – yes, integers – vs. passing a set of integers – yes, integers – to a TVP.
(2) Forcing JSON to output int is natural and expected in this case, given (1), and of course you can create any UDF or CLR function that does a similar thing – splits a string into ints and outputs ints. You just can't change built-ins like STRING_SPLIT().
(3) In fact I've done other tests in this series and on this site where JSON did NOT fare well. So please don't suggest that I'm rigging tests to get some predetermined output, I can assure you I am doing nothing of the sort.
(4) If you think I've done something unfair here and think that doing something differently will lead to a different outcome, you can always set out to prove that on your own. Show me! I'm not the only person who can blog about performance of specific use cases. :-)
Hi, I'm aware that using int in JSON is the best choice, BUT in that case you should at least give XML parser the same type "hint", and do:
SELECT [value] = y.i.value('(./text())[1]', 'int')
instead of:
SELECT [value] = y.i.value('(./text())[1]', 'varchar(max)') — why max type here (OMG)
Initially I didn't use the int designation on the JSON version either; I changed it at the request of Jovan on the SQL Server team, but it made no material difference in the performance. So, feel free to test it out and let me know if you see any difference, especially given that JSON and XML use all the same underlying code paths. Using a max type there is just out of habit and because I re-used an existing function from previous tests; no need for the disrespectful OMG.
I apologize for the OMG part. When it comes to splitting strings with integers inside with purpose to create a collection of numbers for further joins, you should also include a special version of CLR SplitString function that returns a collection of Int, BigInt and TinyInt. It's a lot faster then producing strings and doing cast to whatever int type you need for joins.
I explained why I didn't modify the CLR function to cater to a different type. If you'd like to that, please feel free, I am more than willing to look at your results, but I suspect it still won't beat the approaches I've outlined here, even if it does get slightly better than the results I obtained using the unmodified version of the function. The beauty, of course, which I'm going to keep repeating, is that you (and anyone!) can run these same tests with whatever modifications you want, instead of just saying to me "well if you did x instead of y you'd have different results." Show me.
Really nice analysis Aaron. Thank you very much for this work.
Excellent.
Just wondering if there was a reason OPENJSON was not included in this test?
oh, I see it now. Thought you were doing the JSON from c#.
I have done this test, just to see how the function behaves, trying to exclude access to the table and in this scenario, split_string() is a lot better.
With a million iterations of the same unchanging variable, split string ran in 4 seconds, vs around 24 seconds for openJson.
Must be some clever caching from the devs I guess, or that I am testing it in october2017, which could mean latest sexiest version of split string.
set statistics time off
set nocount on
declare @datetime datetime= getdate()
select @datetime
declare @varchar nvarchar(1)
declare @int int
declare @max int =0
while @max < 1000000
begin
–select @int=value from OPENJSON('[1,5,3,4]')where value=6 –23 seconds
select @varchar=value from OPENJSON('["A","5","C","D"]') where value='B' –25 Seconds
–select @varchar = value from string_split('A,B,C,D',',') where value = 'z' –4 Seconds
set @max = @max+1
END
select datediff(second,@datetime,getdate())
Hi Aaron,
Your post looks very informative. I am looking for a way to split delimited values in a memory optimized stored procedure. But nothing (String_split, cte, Charindex) is supported in memory optimized objects.
Can you explain the use case? Why can't you split outside the memory-optimized stored procedure? Use a TVP, some other way before it gets there. Also are you sure you're getting the performance benefits from the native compiled procedure that you think you are, with or without sneaking expensive string splitting into the process?
The performance testing here is a real eye-opener. Many thanks to Aaron et al.
Quite apart from the performance testing, I've been wondering about an issue not (yet) addressed in the official docs. Are the results returned by the STRING_SPLIT function returned in the order received? This is usually important when parsing CSV data but also in the examples cited above for parsing lists of number. The order matters!
Recently I wanted to use STRING_SPLIT to extract the last word from a sentence with blanks as delimiters. (ignoring punctuation for the moment). Then I had this doubt. Is there a guarantee that the function returns the result set in the order of the input. If not, is there a mitigation?
Super analysis! Thanks Aaron et al.
Quite apart from the performance angle, I've wondering of late if STRING_SPLIT guarantees the result set will be in the same order as the delimited input tokens. This is necessary for processing CSV input, e.g. where you are matching the rows from the result set with the columns in the CSV input you supply.
Recently I wanted to use STRING_SPLIT as a helper to grab the last word of a space-delimited sentence, then got worried since the docs don't seem to offer a guarantee of result set order. If the order is *not* guaranteed, what other approaches would be viable that *would* preserve the result order?