
Performance Surprises and Assumptions : DATEADD
Back in 2013, I wrote about a bug in the optimizer where the 2nd and 3rd arguments to DATEDIFF() can be swapped – which can lead to incorrect row count estimates and, in turn, poor execution plan selection:
This past weekend, I learned about a similar situation, and made the immediate assumption that it was the same problem. After all, the symptoms seemed nearly identical:
- There was a date/time function in the
WHEREclause.- This time it was
DATEADD()instead ofDATEDIFF().
- This time it was
- There was an obviously incorrect row count estimate of 1, compared to an actual row count of over 3 million.
- This was actually an estimate of 0, but SQL Server always rounds up such estimates to 1.
- A poor plan selection was made (in this case, a loop join was chosen) due to the low estimate.
The offending pattern looked like this:
WHERE [datetime2(7) column] >= DATEADD(DAY, -365, SYSUTCDATETIME());
The user tried several variations, but nothing changed; they eventually managed to work around the problem by changing the predicate to:
WHERE DATEDIFF(DAY, [column], SYSUTCDATETIME()) <= 365;
This got a better estimate (the typical 30% inequality guess); so not quite right. And while it eliminated the loop join, there are two major problems with this predicate:
- It is not the same query, since it is now looking for 365 day boundaries to have passed, as opposed to being greater than a specific point in time 365 days ago. Statistically significant? Maybe not. But sill, technically, not the same.
- Applying the function against the column makes the entire expression non-sargable - leading to a full scan. When the table only contains a little over a year of data, this is not a big deal, but as the table gets larger, or the predicate becomes narrower, this will become a problem.
Again, I jumped to the conclusion that the DATEADD() operation was the problem, and recommended an approach that didn't rely on DATEADD() - building a datetime from all of the parts of the current time, allowing me to subtract a year without using DATEADD():
WHERE [column] >= DATETIMEFROMPARTS(
DATEPART(YEAR, SYSUTCDATETIME())-1,
DATEPART(MONTH, SYSUTCDATETIME()),
DATEPART(DAY, SYSUTCDATETIME()),
DATEPART(HOUR, SYSUTCDATETIME()),
DATEPART(MINUTE, SYSUTCDATETIME()),
DATEPART(SECOND, SYSUTCDATETIME()), 0);
In addition to being bulky, this had some problems of its own, namely that a bunch of logic would have to be added to properly account for leap years. First, so that it doesn't fail if it happens to run on February 29th, and second, to include exactly 365 days in all cases (instead of 366 during the year following a leap day). Easy fixes, of course, but they make the logic much uglier - especially because the query needed to exist inside a view, where intermediate variables and multiple steps are not possible.
In the meantime, the OP filed a Connect item, dismayed by the 1-row estimate:
Then Paul White (@SQL_Kiwi) came along and, like many times before, shed some additional light onto the problem. He shared a related Connect item filed by Erland Sommarskog back in 2011:
Essentially, the problem is that a poor estimate can be made not simply when SYSDATETIME() (or SYSUTCDATETIME()) appears, as Erland originally reported, but when any datetime2 expression is involved in the predicate (and perhaps only when DATEADD() is also used). And it can go both ways - if we swap >= for <=, the estimate becomes the whole table, so it seems that the optimizer is looking at the SYSDATETIME() value as a constant, and completely ignoring any operations like DATEADD() that are performed against it.
Paul shared that the workaround is simply to use a datetime equivalent when calculating the date, before converting it to the proper data type. In this case, we can swap out SYSUTCDATETIME() and change it to GETUTCDATE():
WHERE [column] >= CONVERT(datetime2(7), DATEADD(DAY, -365, GETUTCDATE()));
Yes, this results in a tiny loss of precision, but so could a dust particle slowing down your finger on its way to pressing the

The reads are similar because the table contains data almost exclusively from the past year, so even a seek becomes a range scan of most of the table. The row counts are not identical because (a) the second query cuts off at midnight and (b) the third query includes an extra day of data due to the leap day earlier this year. In any case, this still demonstrates how we can get closer to proper estimates by eliminating DATEADD(), but the proper fix is to remove the direct combination of DATEADD() and datetime2.
To further illustrate how the estimates are getting it wrong, you can see that if we pass different arguments and directions to the original query and Paul's re-write, the number of estimated rows for the former is always based on the current time - they don't change with the number of days passed in (whereas Paul's is relatively accurate every time):
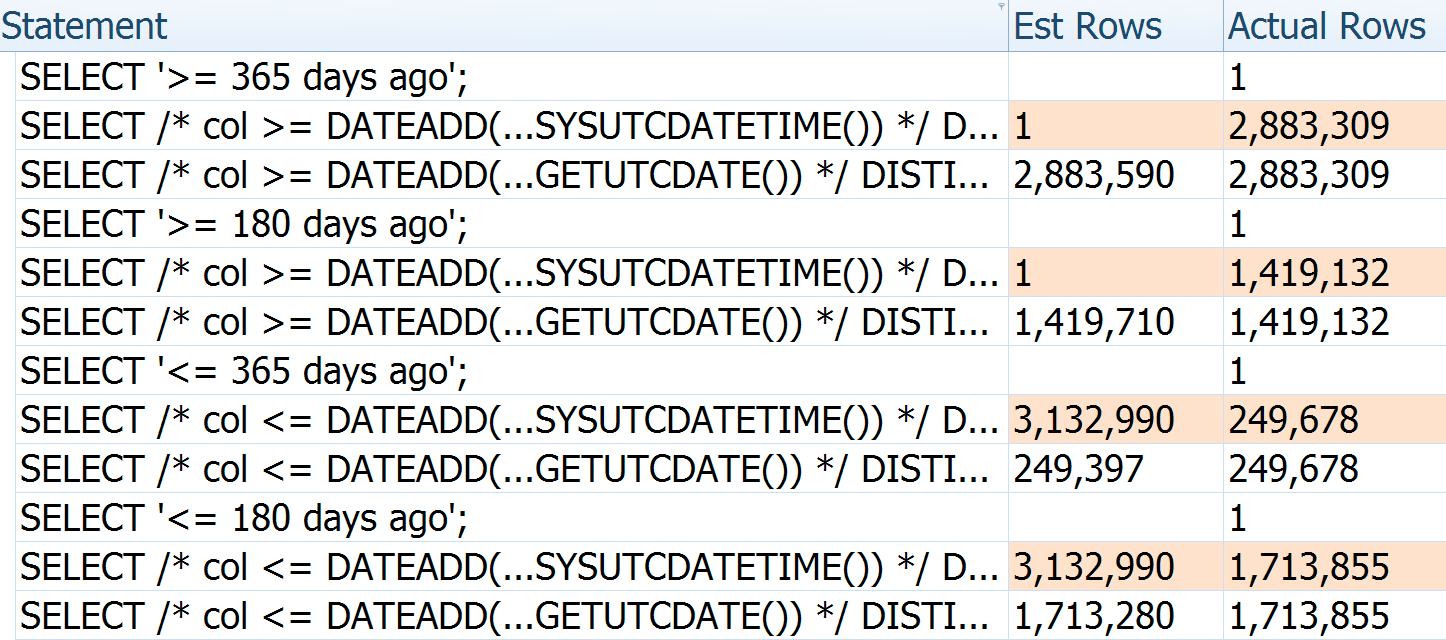 Actual rows for the first query are slightly lower because this was executed after a lengthy nap
Actual rows for the first query are slightly lower because this was executed after a lengthy nap
The estimates won't always be this good; my table just has relatively stable distribution. I populated it with the following query and then updated statistics with fullscan, in case you want to try this out on your own:
-- OP's table definition:
CREATE TABLE dbo.DateaddRepro
(
SessionId int IDENTITY(1, 1) NOT NULL PRIMARY KEY,
CreatedUtc datetime2(7) NOT NULL DEFAULT SYSUTCDATETIME()
);
GO
CREATE NONCLUSTERED INDEX [IX_User_Session_CreatedUtc]
ON dbo.DateaddRepro(CreatedUtc) INCLUDE (SessionId);
GO
INSERT dbo.DateaddRepro(CreatedUtc)
SELECT dt FROM
(
SELECT TOP (3150000) dt = DATEADD(HOUR, (s1.[precision]-ROW_NUMBER()
OVER (PARTITION BY s1.[object_id] ORDER BY s2.[object_id])) / 15, GETUTCDATE())
FROM sys.all_columns AS s1 CROSS JOIN sys.all_objects AS s2
) AS x;
UPDATE STATISTICS dbo.DateaddRepro WITH FULLSCAN;
SELECT DISTINCT SessionId FROM dbo.DateaddRepro
WHERE /* pick your WHERE clause to test */;
I commented on the new Connect item, and will likely go back and touch up my Stack Exchange answer.
The moral of the story
Try to avoid combining DATEADD() with expressions that yield datetime2, especially on older versions of SQL Server (this was on SQL Server 2012). It can also be a problem, even on SQL Server 2016, when using the older cardinality estimation model (due to lower compatibility level, or explicit use of trace flag 9481). Problems like this are subtle and not always immediately obvious, so hopefully this serves as a reminder (maybe even for me the next time I come across a similar scenario). Like I suggested in the last post, if you have query patterns like this, check that you are getting correct estimates, and make a note somewhere to check them again whenever anything major changes in the system (like an upgrade or a service pack).
12 thoughts on “Performance Surprises and Assumptions : DATEADD”
Comments are closed.

Thanks for this! I normaly use dateadd vs datediff to try and ensure a SARGable join/where clause, but didn't know that this bug could occur. Since I normally use getdate() I guess I never ran across this problem as it seems to be a datetime value instead of datetime2.
Good writeup, not to mention I love that you use dark theme code as well. Now if you'd update your preferred font to Bitstream Vera Sans Mono, you'd have your code snippets setup perfectly :-)
That font is too Lucida Console for me. I like Consolas, and my second choice would be Source Code Pro. :-)
Sounds like a solid debate could ensue.. i will check out source code pro. I like how bitstream handles 0's, so let me see how source code pro does. I think i had tried it before and found it substandard…
I value the font smoothness – especially at HiDPI – over the number 0 / letter O differentiation. It's nice, sure, but I guess I just don't have enough real use cases where I am struggling to determine if something is a zero or an oh. Usually when I am doing that it's a captcha (which should never have 0 or O anyway), in a variable width font on a site I can't control.
I'm not using a retina display. Is this where the difference in your perspective is coming through? I'm running 3 1920×1200 S-IPS displays.
Using http://pxcalc.com/ i calculated my DPI at a mindblowing 94.34
Oh great! I see sysdatetime used in queries all the time and never once suspected it could be causing problems.
Thanks Aaron, Paul, and Erlin!
Would using a cte to derive the appropriate datatime data value serve to alleviate what looks like a data type mismatch?
The thing is – datetime2 is not really a data type.
it's a formula.
A formula to calculate a value from the pieces of data stored in the field.
Therefore there is no much difference if you apply another formula on top of the existing one or not.
Predicates cannot work effectively on non-homogenic values.
By "values" I mean not the strings representing dates you see on your screen but the actual binary values stored in a datetime2 field.
And that's pretty much all you need to know to understand the issue.
If you want effective querying – don't use datetime2.
Hmm, not sure I agree about not using datetime2 at all, and am also a little confused – datetime is internally stored as two numbers, so it doesn't seem to meet your definition of a data type either.
Typically I'll declare a variable to compare against…
DECLARE @DateCompare datetime2 = DATEADD(DAY, -365, SYSUTCDATETIME())
Then just compare against that?
"two numbers" is just how you see it.
You may say the same about a float number – it's made out of two numbers, an integer part and a decimal part.
Which is not quite true.
In fact, datetime is a binary string, as well as datetime2.
The advantage of datetime comparing to datetime2 is that it's sequential, "continuous".
What I mean – an increase in stored datetime value always means a corresponding increase in the binary string representing the datetime value.
To add a minute to a datetime value you may simply add two binaries representing that datetime value and a minute.
The same cannot be said about datime2.
The order of bytes in datitime2 is messed up, therefore you cannot say if a date in future will be represented with a bigger or smaller binary value comparing to the binary string representing "now".
Therefore indexing of datetime2 column is as "useful" as indexing of [uniqueidentifier].
It may help to find a single value in a column by seeking for it in the index, but it's absolutely useless for range selections.
When you need to find all last month datetime2 values recorded in a table you have no way to say what range of binaries stored in the table you need to select.
That is exactly why optimiser will always give wrong estoimations when selecting a range of datetime values.
Well, almost always wrong. It always goes for 1/2 of rows estimations – the best it can do.
Which might be correct in some cases.
Like stopped watches – they indicate correct time twice a day.
It cannot be fixed in any version of SQL Server.
Because it's not a bug.
It's by design.
Very bad design.
Somebody did not think it through.
Only way to fix it – change the internals of datetime2 data type.
Therefore, once again:
If you want effective querying – do not use datetime2.
via GIPHY