
Getting Started Tuning Performance in Azure SQL Database
With the introduction of Azure SQL Database and the addition of more functionality in v12, database administrators are starting to see their organizations more interested in moving databases to this platform.
I recently started diving more into Azure SQL Database to see what’s drastically different from supporting the box version in datacenters across the world and Azure SQL Database. In my previous article, "Tuning: A Good Place to Start," I covered my approach for getting started with tuning SQL Server. I decided to review this against Azure SQL Database to discover the major differences.
In my original article, I started with common instance-level settings that I see ignored or left as default, as well as maintenance items. These include memory, maxdop, cost threshold for parallelism, enabling optimize for ad hoc workloads, and configuring tempdb. With Azure SQL Database, you aren’t responsible for the instance, and can’t modify those settings. Azure SQL Database is a Platform as a Service (PaaS), meaning Microsoft manages the instance for you; you’re simply a tenant with your database or databases.
You are responsible for maintenance, however, so you have to update statistics and handle index fragmentation like you do for the box product. For those tasks, I’ve found that most clients manage those processes with a dedicated Azure VM running SQL Server and using SQL Server Agent with scheduled jobs.
Following the steps from my article, the next areas I start looking into are file and wait statistics and high-cost queries. If you’re wondering if this aspect of your job as a production dba with on-premises databases will change when working with Azure SQL Database, the answer is not really. File and wait statistics are still there, but we have to get to them in a slightly different way. If you’re used to using Paul Randal's scripts for file stats and wait stats (or the queries for file stats for a period of time and wait stats for a period of time), then you’ll have to make some changes in order for those scripts to work with Azure SQL Database.
When I first tried Paul’s file stats script, it failed due to Azure SQL Database not supporting sys.master_files:
Invalid object name 'sys.master_files'.
I was able to modify the script to use sys.databases in the join to get the database name and remove the portion of the script to get the individual file names since we will only be dealing with a single data and log file. You can see the changes I had to make in the following image:
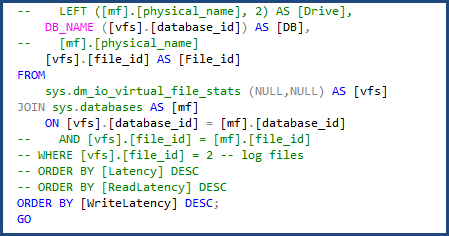
When I ran the file-stats-over-a-period-of-time script after, making the same change to sys.databases and removing the references to file_id in the join, it failed due to Azure SQL Database v12 not supporting global ##temp tables.
Once I changed all the global ##temp tables to local, I had another issue with the script unable to drop existing temp tables that were used, because local #temp tables cannot be referenced directly by name the way global ##temp tables can, but this was easy to overcome by changing such checks to OBJECT_ID('tempdb..#SQLskillsStats1'). I made the same change for the second temporary table, and updated the block of code at the beginning and end of the script.
I had to make one more change and remove [mf].[type_desc] and LEFT ([mf].[physical_name], 2) AS [Drive] since those are dependent on sys.master_files. The script was then complete and ready to use with Azure SQL Database.
I use the file-stats-over-a-period-of-time regularly when troubleshooting performance issues. The cumulative data has its purpose, but I’m more interested in specific segments of time when user workloads are being ran.
With file stats, we are concerned with our latency per database file and how we can tune to help reduce overall I/O. The approach is the same as SQL Server, where you need to tune your queries properly and have the correct indexes. If the workload is just too large, then you have to move to a faster performing DTU database tier. For me, this is great: you just throw hardware at it; but it's not really hardware in the traditional sense. With Azure SQL Database, you get to start with a less expensive tier and scale as your business and I/O demands grow – essentially by just flipping a switch.
Trying to find the best method for obtaining wait stats was easier. The standard script that many of us use still works, however it’s pulling wait stats for the container in which your database is running. Those waits still apply to your system, but can include waits incurred by other databases in the same container. Azure SQL Database contains a new DMV, sys.dm_db_wait_stats, which filters to the current database. If you’re like me and primarily use Paul's wait stats script that omits all the benign waits, just change sys.dm_os_wait_stats to sys.dm_db_wait_stats. The same change works for the waits-over-a-period-of-time-script as well, but you also have to make the change from global variables to local.
When it comes to finding high cost queries, one of my favorite scripts to run finds the most used execution plans. In my experience, tuning a query that is called 100,000 times per day is usually a bigger win than tuning a query that has the highest IO but is only run once per week. The following query is what I use to find the most used plans:
SELECT usecounts ,
cacheobjtype ,
objtype ,
[text]
FROM sys.dm_exec_cached_plans
CROSS APPLY sys.dm_exec_sql_text(plan_handle)
WHERE usecounts > 1
AND objtype IN ( N'Adhoc', N'Prepared' )
ORDER BY usecounts DESC;When using this query in demos, I always flush my plan cache to reset the values. When I tried running DBCC FREEPROCCACHE in Azure SQL Database, I was given the following error:
It turns out that DBCC FREEPROCCACHE is not supported in Azure SQL Database. This was troubling to me, what if I’m in production and have some bad plans and want to clear the procedure cache like I can with the box version. A little Google/Bing research lead me to find the Microsoft article, "Understanding the Procedure Cache on SQL Azure," which states:
In discussing this with Kimberly Tripp after not seeing that described behavior, it does not flush the plan from cache, but it does invalidate the plan (and then the plan will be eventually aged out of the cache). While this is helpful in certain situations, this was not what I needed. For my demo I wanted to reset the counters in sys.dm_exec_cached_plans. Generating a new plan would not give me the desired results. I reached out to my team and Glenn Berry told me to try the following script:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE;This command worked; I was able to clear the procedure cache for the specific database. Database Scoped Configurations is a new feature added in SQL Server 2016 RC0; Glenn blogged about it here: Using ALTER DATABASE SCOPED CONFIGURATION in SQL Server 2016.
I am excited to move several of my own databases into Azure SQL Database, and to continue learning about the new features and scalability options. I am also looking forward to working with SentryOne DB Sentry, a recent addition to the SentryOne Platform. I am most interested in experimenting with the DTU Usage dashboard, which Mike Wood described in his recent post.
5 thoughts on “Getting Started Tuning Performance in Azure SQL Database”
Comments are closed.

Awesome Article Tim!
Don't you think it would be cool to have the Database level scoped wait stats in the on-premise product? (sys.dm_db_wait_stats)
I think the addition of sys.dm_exec_session_wait_stats was more useful, but yeah that would be a good one to have too.
Great Article Tim!!! Thanks!
Link "Using ALTER DATABASE SCOPED CONFIGURATION in SQL Server 2016." is pointing to the wrong article
Regards
Fixed, thanks!