
Sparse Columns in SQL Server : Impact on Time & Space
SQL Server 2008 introduced sparse columns as a method to reduce storage for null values and provide more extensible schemas. The trade-off is that there is additional overhead when you store and retrieve non-NULL values. I was interested in understanding the cost for storing non-NULL values, after talking to a customer who was using this data type in a staging environment. They’re looking to optimize write performance, and I wondered whether the use of sparse columns had any effect, as their method required inserting a row into the table, then updating it. I created a contrived example for this demo, explained below, to determine if this was a good methodology for them to use.
Internals Review
As a quick review, remember that when you create a column for a table which allows NULL values, if it is a fixed-length column (e.g. an INT), it will always consume the whole column width on the page even when the column is NULL. If it is a variable-length column (e.g. VARCHAR), it will consume at least two bytes in the column offset array when NULL, unless the columns are after the last populated column (see Kimberly’s blog post Column order doesn't matter…generally, but – IT DEPENDS). A sparse column does not require any space on the page for NULL values, whether it’s a fixed-length or variable-length column, and regardless of what other columns are populated in the table. The trade off is that when a sparse column is populated, it takes four (4) more bytes of storage than a non-sparse column. For example:
| Column type | Storage requirement |
|---|---|
| BIGINT column, non-sparse, with no value | 8 bytes |
| BIGINT column, non-sparse, with a value | 8 bytes |
| BIGINT column, sparse, with no value | 0 bytes |
| BIGINT column, sparse, with a value | 12 bytes |
Therefore, it’s essential to confirm that the storage benefit outweighs the potential performance hit of retrieval – which may be negligible based on the balance of reads and writes against the data. The estimated space savings for different data types is documented in the Books Online link provided above.
Test Scenarios
I set up four different scenarios for testing, described below, and every table had an ID column (INT), a Name column (VARCHAR(100)), and a Type column (INT), and then 997 NULLABLE columns.
| Test ID | Table Description | DML Operations |
|---|---|---|
| 1 | 997 columns of INT data type, NULLABLE, non-sparse | Insert one row at a time, populating ID, Name, Type, and ten (10) random NULLABLE columns |
| 2 | 997 columns of INT data type, NULLABLE, sparse | Insert one row at a time, populating ID, Name, Type, and ten (10) random NULLABLE columns |
| 3 | 997 columns of INT data type, NULLABLE, non-sparse | Insert one row at a time, populating ID, Name, Type only, then update the row, adding values for ten (10) random NULLABLE columns |
| 4 | 997 columns of INT data type, NULLABLE, sparse | Insert one row at a time, populating ID, Name, Type only, then update the row, adding values for ten (10) random NULLABLE columns |
| 5 | 997 columns of VARCHAR data type, NULLABLE, non-sparse | Insert one row at a time, populating ID, Name, Type, and ten (10) random NULLABLE columns |
| 6 | 997 columns of VARCHAR data type, NULLABLE, sparse | Insert one row at a time, populating ID, Name, Type, and ten (10) random NULLABLE columns |
| 7 | 997 columns of VARCHAR data type, NULLABLE, non-sparse | Insert one row at a time, populating ID, Name, Type only, then update the row, adding values for ten (10) random NULLABLE columns |
| 8 | 997 columns of VARCHAR data type, NULLABLE, sparse | Insert one row at a time, populating ID, Name, Type only, then update the row, adding values for ten (10) random NULLABLE columns |
Each test was run twice with a data set of 10 million rows. The attached scripts can be used to replicate testing, and the steps were as follows for each test:
- Create a new database with pre-sized data and log files
- Create the appropriate table
- Snapshot wait statistics and file statistics
- Note the start time
- Execute the DML (one insert, or one insert and one update) for 10 million rows
- Note the stop time
- Snapshot wait statistics and file statistics and write to a logging table in a separate database on separate storage
- Snapshot dm_db_index_physical_stats
- Drop the database
Testing was done on a Dell PowerEdge R720 with 64GB of memory and 12GB allocated to the SQL Server 2014 SP1 CU4 instance. Fusion-IO SSDs were used for data storage for the database files.
Results
Test results are presented below for each test scenario.
Duration
In all cases, it took less time (average 11.6 minutes) to populate the table when sparse columns were used, even when the row was first inserted, then updated. When the row was first inserted, then updated, the test took almost twice as long to run compared to when the row was inserted, as twice as many data modifications were executed.
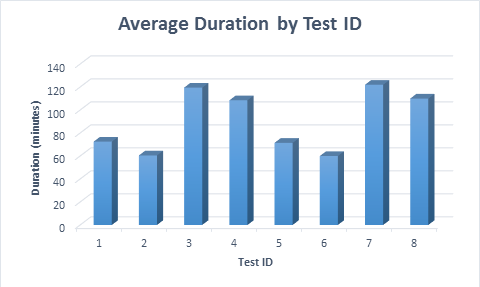 Average duration for each test scenario
Average duration for each test scenario
Wait Statistics
| Test ID | Average Percentage | Average Wait (seconds) |
|---|---|---|
| 1 | 16.47 | 0.0001 |
| 2 | 14.00 | 0.0001 |
| 3 | 16.65 | 0.0001 |
| 4 | 15.07 | 0.0001 |
| 5 | 12.80 | 0.0001 |
| 6 | 13.99 | 0.0001 |
| 7 | 14.85 | 0.0001 |
| 8 | 15.02 | 0.0001 |
The wait statistics were consistent for all tests and no conclusions can be made based on this data. The hardware sufficiently met the resource demands in all test cases.
File Statistics
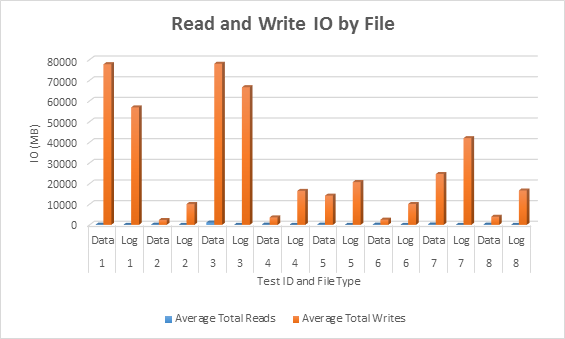 Average IO (read and write) per database file
Average IO (read and write) per database file
In all cases, the tests with sparse columns generated less IO (notably writes) compared to non-sparse columns.
Index Physical Stats
| Test case | Row count | Total page count (clustered index) | Total space (GB) | Average Space Used for leaf pages in CI (%) | Average Record Size (bytes) |
|---|---|---|---|---|---|
| 1 | 10,000,000 | 10,037,312 | 76 | 51.70 | 4,184.49 |
| 2 | 10,000,000 | 301,429 | 2 | 98.51 | 237.50 |
| 3 | 10,000,000 | 10,037,312 | 76 | 51.70 | 4,184.50 |
| 4 | 10,000,000 | 460,960 | 3 | 64.41 | 237.50 |
| 5 | 10,000,000 | 1,823,083 | 13 | 90.31 | 1,326.08 |
| 6 | 10,000,000 | 324,162 | 2 | 98.40 | 255.28 |
| 7 | 10,000,000 | 3,161,224 | 24 | 52.09 | 1,326.39 |
| 8 | 10,000,000 | 503,592 | 3 | 63.33 | 255.28 |
Significant differences exist in space use between the non-sparse and sparse tables. This is most notable when looking at test cases 1 and 3, where a fixed-length data type was used (INT), compared to test cases 5 and 7, where a variable length data type was used (VARCHAR(255)). The integer columns consumes disk space even when NULL. The variable length columns consume less disk space, as only two bytes are used in the offset array for NULL columns, and no bytes for those NULL columns that are after the last populated column in the row.
Further, the process of inserting a row and then updating it causes fragmentation for the variable-length column test (case 7), compared to simply inserting the row (case 5). The table size almost doubles when the insert is followed by the update, due to page splits which occur when updating the rows, which leaves the pages half full (versus 90% full).
Summary
In conclusion, we see a significant reduction in disk space and IO when sparse columns are used, and they perform slightly better than non-sparse columns in our simple data modification tests (note that retrieval performance should also be considered; perhaps the subject of another post).
Sparse columns have a very specific usage scenario and it’s important to examine the amount of disk space saved, based on the data type for the column and the number of columns that will typically be populated in the table. In our example, we had 997 sparse columns, and we only populated 10 of them. At most, in the case where the data type used was integer, a row at the leaf level of the clustered index would consume 188 bytes (4 bytes for the ID, 100 bytes max for the Name, 4 bytes for the type, and then 80 bytes for 10 columns). When 997 columns were non-sparse, then 4 bytes were allocated for every column, even when NULL, so each row was at least 4,000 bytes at the leaf level. In our scenario, sparse columns are absolutely acceptable. But if we populated 500 or more sparse columns with values for an INT column, then the space savings is lost, and modification performance may no longer be better.
Depending on the data type for your columns, and the expected number of columns to be populated of the total, you may want to perform similar testing to ensure that, when using sparse columns, insert performance and storage are comparable or better than when using non-sparse columns. For cases when not all columns are populated, sparse columns are definitely worth considering.
7 thoughts on “Sparse Columns in SQL Server : Impact on Time & Space”
Comments are closed.
Nicely done, Erin. If you still have the data around I would love to see this post extended (or a fresh one) with a variety of retrieval scenarios too. I am curious how the rehydration part will play into that side of the coin.
You didn't happen to capture CPU load during the DML runs did you? I would love to see that as well.
Great bit of analysis.
Moving on to retrieval performance…
An alternative design, in some cases, is to use a 'satellite' table. One to one table with additional/optional data for the core table.
If we have some data that is particularly wide, but only occasional non null, or indeed we have some wide data that is rarely consumed, we can put it into this separate table, and left join to it when needed.
The IO difference there, vs. sparse, is potentially dramatic
Everything in sparse goes up the IO path, regardless of whether it is selected.
Whereas in our satellite table design, the extra table only has an IO hit when we specifically consume it (obviously)
So there's a few variables in play – the data modification IO as tested by Erin above, and then data read IO which has completely different behaviours.
"regardless of whether it is selected." – by that I mean, regardless of whether the *column* is selected.
Paul-
This is absolutely one option, but it then assumes that when you need the data from the satellite table, you have alternate code that is used or generated to include those columns. It all depends on how you've written your TSQL, as you then need to introduce the ability to check for columns requested (and I'm assuming here that columns selected are determined by the user) and make sure those get retrieved.
Thanks for the feedback!
Erin
Indeed – it's very much an "it depends" area of schema design. Some things may or may not be in one's control… like app generated queries.
Before I tested, I had for some reason expected that all the sparse cols would be held in an entirely separate structure, so no IO hit if not consumed. (Almost like an invisible satellite table). But my expectation was wrong.
My tests were fairly basic, but if you follow up with some more in depth measures, I'll be keen to see your findings.
Did you end up doing the analysis of "retrieval costs" associated with sparse columns?
I haven't yet…but perhaps I should as there seems to be some interest in it.