


Almost a year ago to the day, I posted my solution to pagination in SQL Server, which involved using a CTE to locate just the key values for the set of rows in question, and then joining back from the CTE to the source table to retrieve the other columns for just that "page" of rows. This proved most beneficial when there was a narrow index that supported the ordering requested by the user, or when the ordering was based on the clustering key, but even performed a little better without an index to support the required sort.
Since then, I've wondered if ColumnStore indexes (both clustered and non-clustered) might help any of these scenarios. TL;DR: Based on this experiment in isolation, the answer to the title of this post is a resounding NO. If you don't want to see the test setup, code, execution plans, or graphs, feel free to skip to my summary, keeping in mind that my analysis is based on a very specific use case.
Setup
On a new VM with SQL Server 2016 CTP 3.2 (13.0.900.73) installed, I ran through roughly the same setup as before, only this time with three tables. First, a traditional table with a narrow clustering key and multiple supporting indexes:
CREATE TABLE [dbo].[Customers]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL UNIQUE,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID])
);
CREATE NONCLUSTERED INDEX [Active_Customers]
ON [dbo].[Customers]([FirstName],[LastName],[EMail])
WHERE ([Active]=1);
-- to support "PhoneBook" sorting (order by Last,First)
CREATE NONCLUSTERED INDEX [PhoneBook_Customers]
ON [dbo].[Customers]([LastName],[FirstName])
INCLUDE ([EMail]);
Next, a table with a clustered ColumnStore index:
CREATE TABLE [dbo].[Customers_CCI]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL UNIQUE,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_CustomersCCI] PRIMARY KEY NONCLUSTERED ([CustomerID])
);
CREATE CLUSTERED COLUMNSTORE INDEX [Customers_CCI]
ON [dbo].[Customers_CCI];
And finally, a table with a non-clustered ColumnStore index covering all of the columns:
CREATE TABLE [dbo].[Customers_NCCI]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL UNIQUE,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_CustomersNCCI] PRIMARY KEY CLUSTERED
([CustomerID])
);
CREATE NONCLUSTERED COLUMNSTORE INDEX [Customers_NCCI]
ON [dbo].[Customers_NCCI]
(
[CustomerID],
[FirstName],
[LastName],
[EMail],
[Active],
[Created],
[Updated]
);
Notice that for both tables with ColumnStore indexes, I left out the index that would support quicker seeks on the "PhoneBook" sort (last name, first name).
Test Data
I then populated the first table with 1,000,000 random rows, based on a script I've re-used from previous posts:
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (1000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (2000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name+c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn;
Then I used that table to populate the other two with exactly the same data, and rebuilt all of the indexes:
INSERT dbo.Customers_CCI WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT CustomerID, FirstName, LastName, EMail, [Active]
FROM dbo.Customers;
INSERT dbo.Customers_NCCI WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT CustomerID, FirstName, LastName, EMail, [Active]
FROM dbo.Customers;
ALTER INDEX ALL ON dbo.Customers REBUILD;
ALTER INDEX ALL ON dbo.Customers_CCI REBUILD;
ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
The total size of each table:
| Table | Reserved | Data | Index |
|---|---|---|---|
| Customers | 463,200 KB | 154,344 KB | 308,576 KB |
| Customers_CCI | 117,280 KB | 30,288 KB | 86,536 KB |
| Customers_NCCI | 349,480 KB | 154,344 KB | 194,976 KB |
And the row count / page count of the relevant indexes (the unique index on e-mail was there more for me to babysit my own data generation script than anything else):
| Table | Index | Rows | Pages |
|---|---|---|---|
| Customers | PK_Customers | 1,000,000 | 19,377 |
| Customers | PhoneBook_Customers | 1,000,000 | 17,209 |
| Customers | Active_Customers | 808,012 | 13,977 |
| Customers_CCI | PK_CustomersCCI | 1,000,000 | 2,737 |
| Customers_CCI | Customers_CCI | 1,000,000 | 3,826 |
| Customers_NCCI | PK_CustomersNCCI | 1,000,000 | 19,377 |
| Customers_NCCI | Customers_NCCI | 1,000,000 | 16,971 |
Procedures
Then, in order to see if the ColumnStore indexes would swoop in and make any of the scenarios better, I ran the same set of queries as before, but now against all three tables. I got at least a little bit smarter and made two stored procedures with dynamic SQL to accept the table source and sort order. (I am well aware of SQL injection; this isn't what I would do in production if these strings were coming from an end user, so please don't take it as a recommendation to do so. I trust myself just enough in my enclosed environment that it's not a concern for these tests.)
CREATE PROCEDURE dbo.P_Old
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N'
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
CREATE PROCEDURE dbo.P_CTE
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
;WITH pg AS
(
SELECT CustomerID
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.' + QUOTENAME(@Table) + N' AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
Then I whipped up some more dynamic SQL to generate all the combinations of calls I would need to make in order to call both the old and new stored procedures, in all three of the desired sort orders, and at different page numbers (to simulate needing a page near the beginning, middle, and end of the sort order). So that I could copy PRINT output and paste it into SQL Sentry Plan Explorer in order to get runtime metrics, I ran this batch twice, once with the procedures CTE using P_Old, and then again using P_CTE.
DECLARE @sql NVARCHAR(MAX) = N'';
;WITH [tables](name) AS
(
SELECT N'Customers' UNION ALL SELECT N'Customers_CCI'
UNION ALL SELECT N'Customers_NCCI'
),
sorts(sort) AS
(
SELECT 'Key' UNION ALL SELECT 'PhoneBook' UNION ALL SELECT 'Unsupported'
),
pages(pagenumber) AS
(
SELECT 1 UNION ALL SELECT 500 UNION ALL SELECT 5000 UNION ALL SELECT 9999
),
procedures(name) AS
(
SELECT N'P_CTE' -- N'P_Old'
)
SELECT @sql += N'
EXEC dbo.' + p.name
+ N' @Table = N' + CHAR(39) + t.name
+ CHAR(39) + N', @Sort = N' + CHAR(39)
+ s.sort + CHAR(39) + N', @PageNumber = '
+ CONVERT(NVARCHAR(11), pg.pagenumber) + N';'
FROM tables AS t
CROSS JOIN sorts AS s
CROSS JOIN pages AS pg
CROSS JOIN procedures AS p
ORDER BY t.name, s.sort, pg.pagenumber;
PRINT @sql;
This produced output like this (36 calls altogether for the old method (P_Old), and 36 calls for the new method (P_CTE)):
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 1;
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 500;
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 5000;
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 9999;
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 1;
...
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 9999;
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 1;
...
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 9999;
EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Key', @PageNumber = 1;
...
EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Unsupported', @PageNumber = 9999;
EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Key', @PageNumber = 1;
...
EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Unsupported', @PageNumber = 9999;
I know, this is all very cumbersome; we're getting to the punchline soon, I promise.
Results
I took those two sets of 36 statements and started two new sessions in Plan Explorer, running each set multiple times to ensure we were getting data from a warm cache and taking averages (I could compare cold and warm cache too, but I think there are enough variables here).
I can tell you right off the bat a couple of simple facts without even showing you supporting graphs or plans:
- In no scenario did the "old" method beat the new CTE method I promoted in my previous post, no matter what type of indexes were present. So that makes it easy to virtually ignore half of the results, at least in terms of duration (which is the one metric end users care about most).
- No ColumnStore index fared well when paging toward the end of the result – they only provided benefits toward the beginning, and only in a couple of cases.
- When sorting by the primary key (clustered or not), the presence of ColumnStore indexes did not help – again, in terms of duration.
With those summaries out of the way, let's take a look at a few cross-sections of the duration data. First, the results of the query ordered by first name descending, then e-mail, with no hope of using an existing index for sorting. As you can see in the chart, performance was inconsistent – at lower page numbers, the non-clustered ColumnStore did best; at higher page numbers, the traditional index always won:
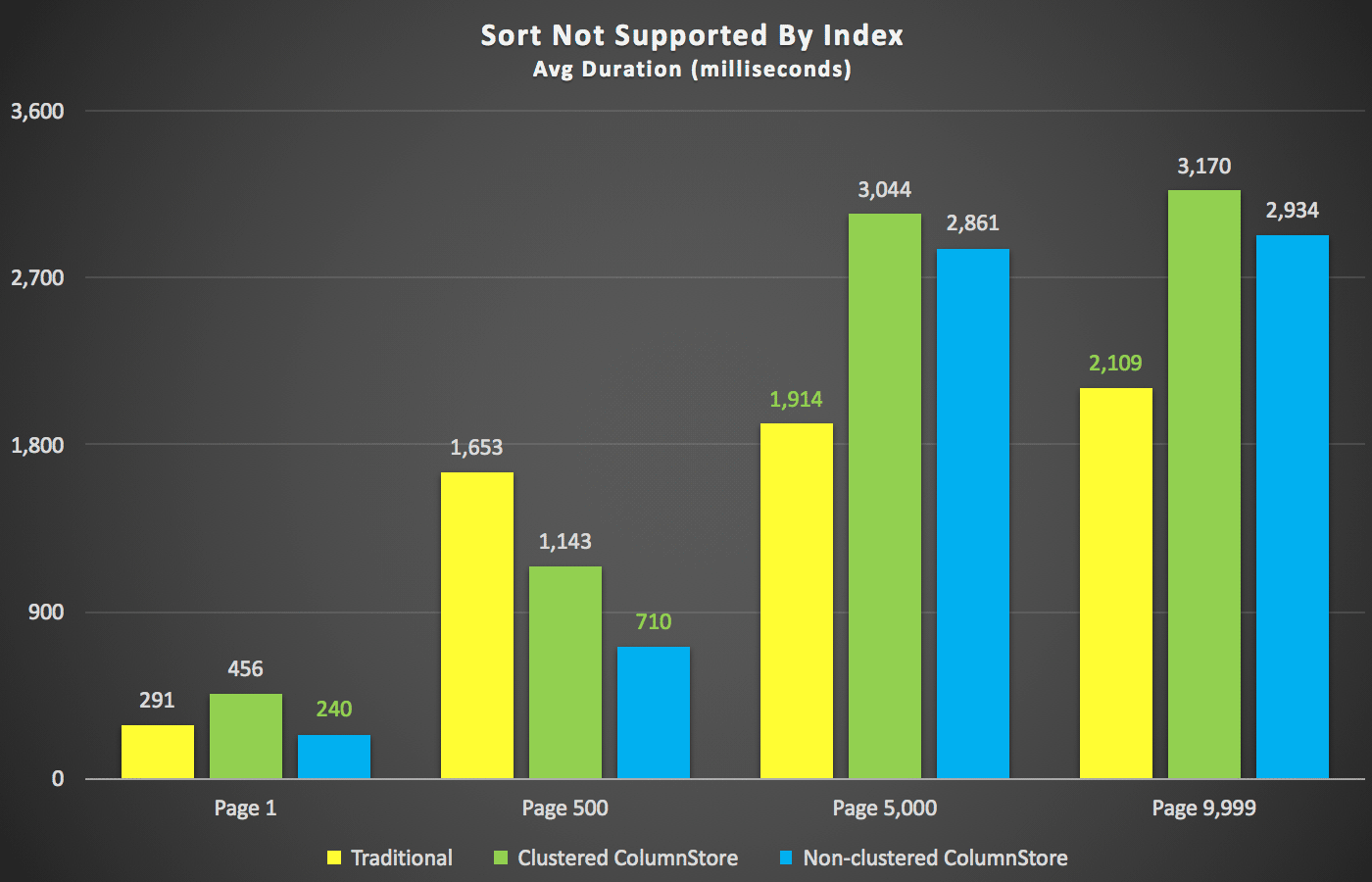 Duration (milliseconds) for different page numbers and different index types
Duration (milliseconds) for different page numbers and different index types
And then the three plans representing the three different types of indexes (with grayscale added by Photoshop in order to highlight the major differences between the plans):
 Plan for traditional index
Plan for traditional index
 Plan for clustered ColumnStore index
Plan for clustered ColumnStore index
 Plan for non-clustered ColumnStore index
Plan for non-clustered ColumnStore index
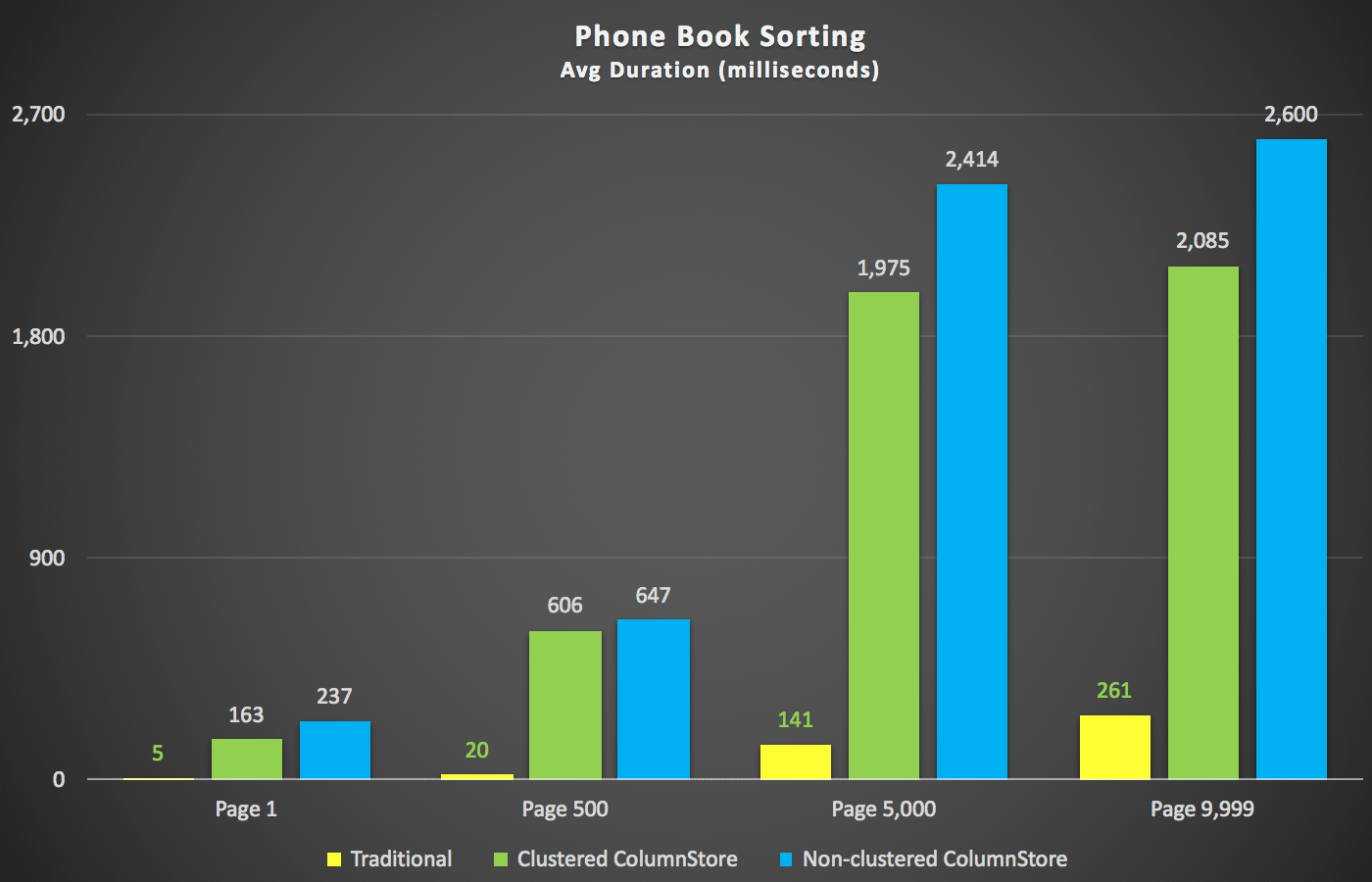
A scenario I was more interested in, even before I started testing, was the phone book sorting approach (last name, first name). In this case the ColumnStore indexes were actually quite detrimental to the performance of the result:
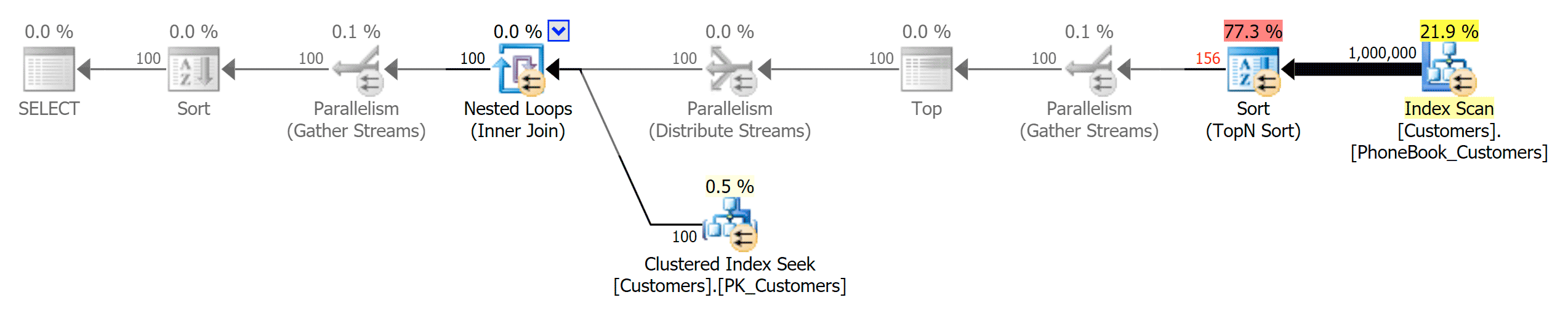
The ColumnStore plans here are near mirror images to the two ColumnStore plans shown above for the unsupported sort. The reason is the same in both cases: expensive scans or sorts due to a lack of a sort-supporting index.
So next, I created supporting "PhoneBook" indexes on the tables with the ColumnStore indexes as well, to see if I could coax a different plan and/or faster execution times in any of those scenarios. I created these two indexes, then rebuilt again:
CREATE NONCLUSTERED INDEX [PhoneBook_CustomersCCI]
ON [dbo].[Customers_CCI]([LastName],[FirstName])
INCLUDE ([EMail]);
ALTER INDEX ALL ON dbo.Customers_CCI REBUILD;
CREATE NONCLUSTERED INDEX [PhoneBook_CustomersNCCI]
ON [dbo].[Customers_NCCI]([LastName],[FirstName])
INCLUDE ([EMail]);
ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Here were the new durations:
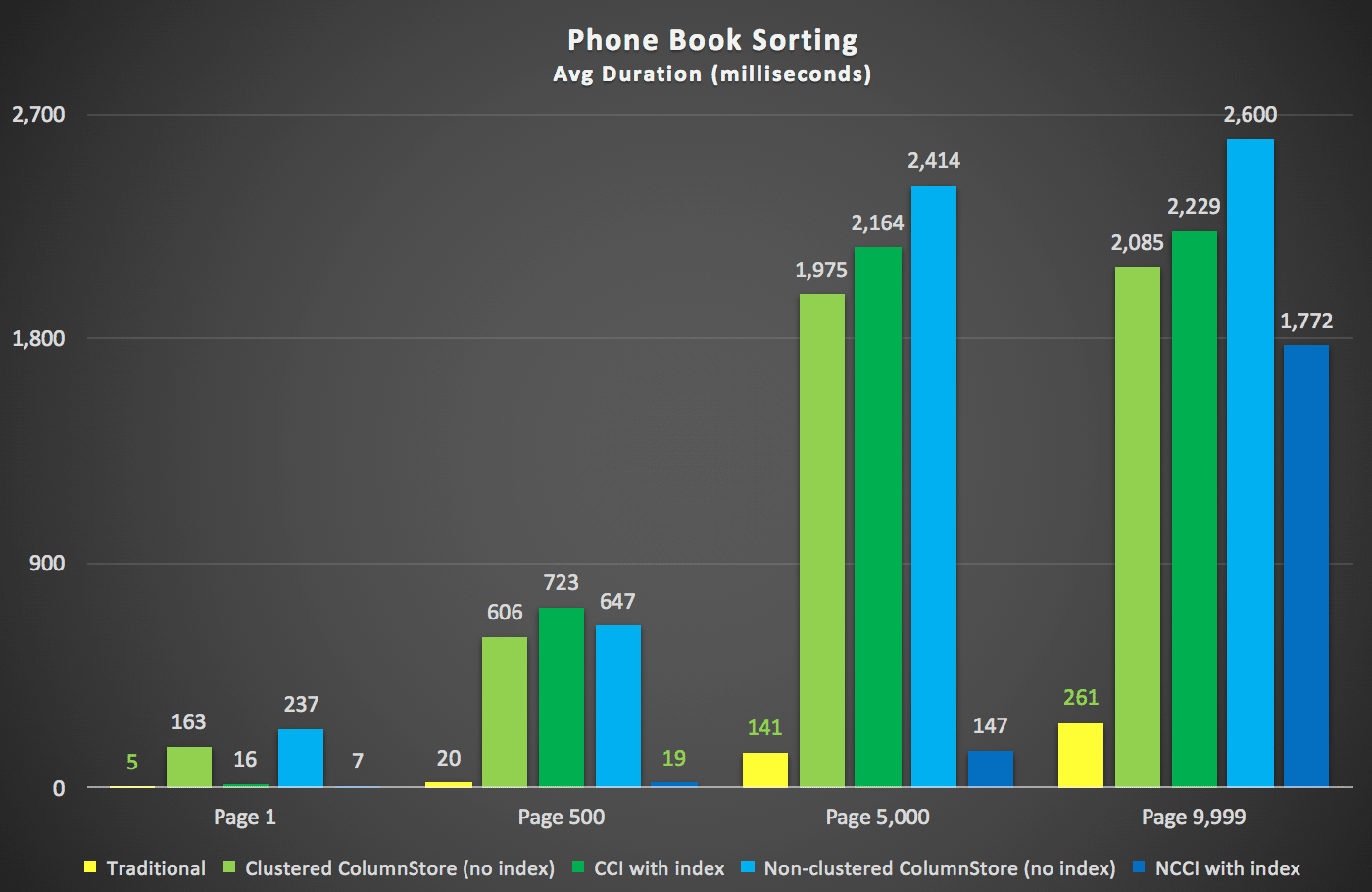
Most interesting here is that now the paging query against the table with the non-clustered ColumnStore index seems to be keeping pace with the traditional index, up until we get beyond the middle of the table. Looking at the plans, we can see that at page 5,000, a traditional index scan is used, and the ColumnStore index is completely ignored:
 Phone Book plan ignoring the non-clustered ColumnStore index
Phone Book plan ignoring the non-clustered ColumnStore index
But somewhere between the mid-point of 5,000 pages and the "end" of the table at 9,999 pages, the optimizer has hit a kind of tipping point and – for the exact same query – is now choosing to scan the non-clustered ColumnStore index:
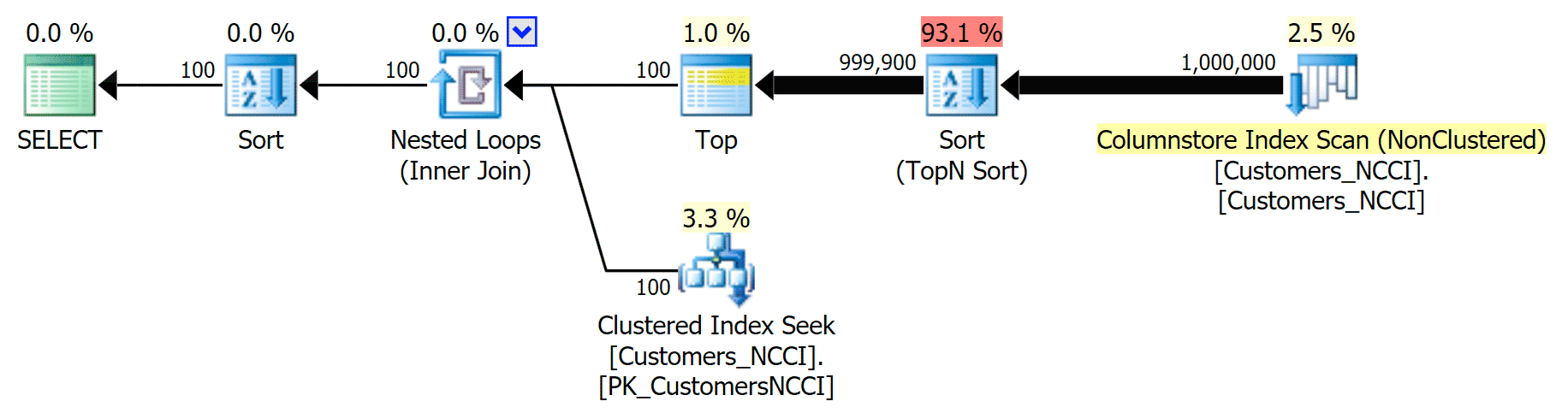 Phone Book plan 'tips' and uses the ColumnStore index
Phone Book plan 'tips' and uses the ColumnStore index
This turns out to be a not-so-great decision by the optimizer, primarily due to the cost of the sort operation. You can see how much better the duration gets if you hint the regular index:
-- ...
;WITH pg AS
(
SELECT CustomerID
FROM dbo.[Customers_NCCI] WITH (INDEX(PhoneBook_CustomersNCCI)) -- hint here
ORDER BY LastName, FirstName OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
-- ...
This yields the following plan, almost identical to the first plan above (a slightly higher cost for the scan, though, simply because there is more output):
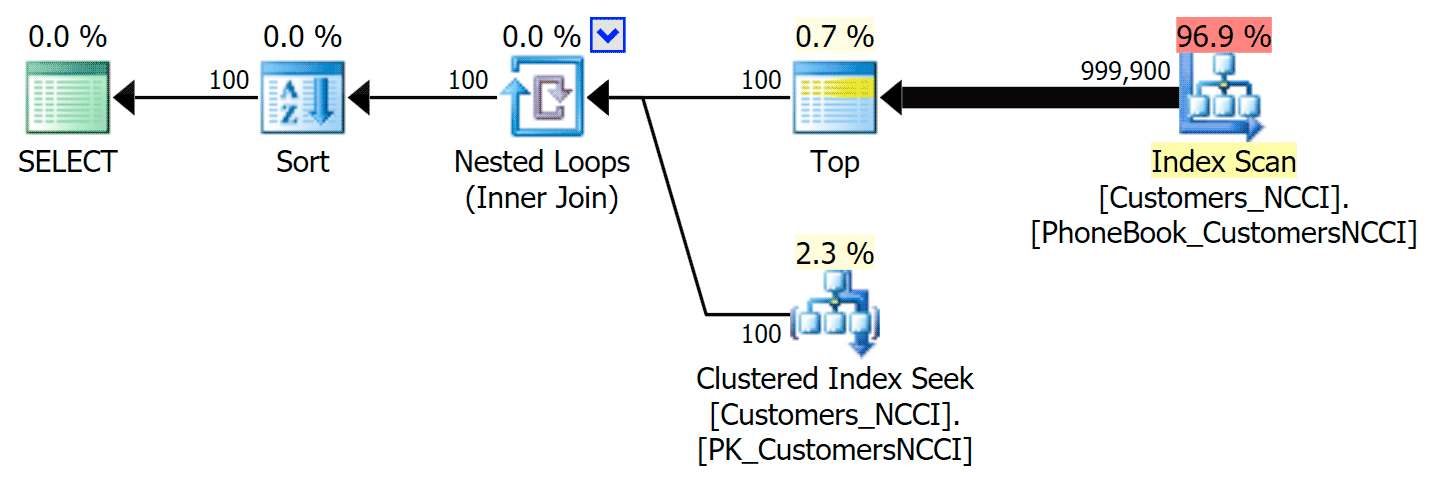 Phone Book plan with hinted index
Phone Book plan with hinted index
You could achieve the same using OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX) instead of the explicit index hint. Just keep in mind that this is the same as not having the ColumnStore index there in the first place.
Conclusion
While there are a couple of edge cases above where a ColumnStore index might (barely) pay off, it doesn't seem to me that they're a good fit for this specific pagination scenario. I think, most importantly, while ColumnStore does demonstrate significant space savings due to compression, the runtime performance is not fantastic because of the sort requirements (even though these sorts are estimated to run in batch mode, a new optimization for SQL Server 2016).
In general, this could do with a whole lot more time spent on research and testing; in piggy-backing off of previous articles, I wanted to change as little as possible. I'd love to find that tipping point, for example, and I'd also like to acknowledge that these are not exactly massive-scale tests (due to VM size and memory limitations), and that I left you guessing about a lot of the runtime metrics (mostly for brevity, but I don't know that a chart of reads that aren't always proportional to duration would really tell you). These tests also assume the luxuries of SSDs, sufficient memory, an always-warm cache, and a single-user environment. I'd really like to perform a larger battery of tests against more data, on bigger servers with slower disks and instances with less memory, all the while with simulated concurrency.
That said, this could also just be a scenario that ColumnStore isn't designed to help solve in the first place, as the underlying solution with traditional indexes is already pretty efficient at pulling out a narrow set of rows – not exactly ColumnStore's wheelhouse. Perhaps another variable to add to the matrix is page size – all of the tests above pull 100 rows at a time, but what if we are after 10,000 or 100,000 rows at a time, regardless of how big the underlying table is?
Do you have a situation where your OLTP workload was improved simply by the addition of ColumnStore indexes? I know that they are designed for data warehouse-style workloads, but if you've seen benefits elsewhere, I'd love to hear about your scenario and see if I can incorporate any differentiators into my test rig.



It would be nice to have an index that helps with pagination. So far there is none. All pagination queries are O(N) in the page number.