
Using Microsoft DiskSpd to Test Your Storage Subsystem
Previously, I covered the basics of storage subsystem metrics and testing in my article Analyzing I/O Subsystem Performance for SQL Server, including an introduction of CrystalDiskMark 4.0. CrystalDiskMark was recently rewritten to use Microsoft DiskSpd for its testing, which makes it an even more valuable tool for your initial storage subsystem testing efforts. DiskSpd provides the functionality needed to generate a wide variety of disk request patterns, which can be very helpful in diagnosis and analysis of I/O performance issues with a lot more flexibility than older benchmark tools like SQLIO. It is extremely useful for synthetic storage subsystem testing when you want a greater level of control than that available in CrystalDiskMark.
Now, we are going to dive a little deeper into how to actually use Microsoft DiskSpd to test your storage subsystem without using CrystalDiskMark 4.0. In order to do this, you’ll need to download and unzip DiskSpd. To make things easier, I always copy the desired diskspd.exe executable file from the appropriate executable folder (amd64fre, armfre or x86fre) to a short, simple path like C:\DiskSpd. In most cases you will want the 64-bit version of DiskSpd from the amd64fre folder.
Once you have the diskspd.exe executable file available, you will need to open a command prompt with administrative rights (by choosing “Run as Administrator”), and then navigate to the directory where you copied the diskspd.exe file.
Here are some of the command line parameters that you will want to start out with:
| Parameter | Description |
| -b | Block size of the I/O, specified as (K/M/G). For example –b8K means an 8KB block size, which is relevant for SQL Server |
| -d | Test duration in seconds. Tests of 30-60 seconds are usually long enough to get valid results |
| -o | Outstanding I/Os (meaning queue depth) per target, per worker thread |
| -t | Worker threads per test file target |
| -h | Disable software caching at the operating system level and hardware write caching, which is a good idea for testing SQL Server |
| -r | Random or sequential flag. If –r is used random tests are done, otherwise sequential tests are done |
| -w | Write percentage. For example, –w25 means 25% writes, 75% reads |
| -Z | Workload test write source buffer size, specified as (K/M/G). Used to supply random data for writes, which is a good idea for SQL Server testing |
| -L | Capture latency information during the test, which is a very good idea for testing SQL Server |
| -c | Creates workload file(s) of the specified size, specified as (K/M/G) |
Table 1: Basic command line parameters for DiskSpd
You will also want to specify the test file location and the file name for the results at the end of the line. Here is an example command line:
This example command line will run a 30 second random I/O test using a 20GB test file located on the T: drive, with a 25% write and 75% read ratio, with an 8K block size. It will use eight worker threads, each with four outstanding I/Os and a write entropy value seed of 1GB. It will save the results of the test to a text file called DiskSpeedResults.txt. This is a pretty good set of parameters for a SQL Server OLTP workload.
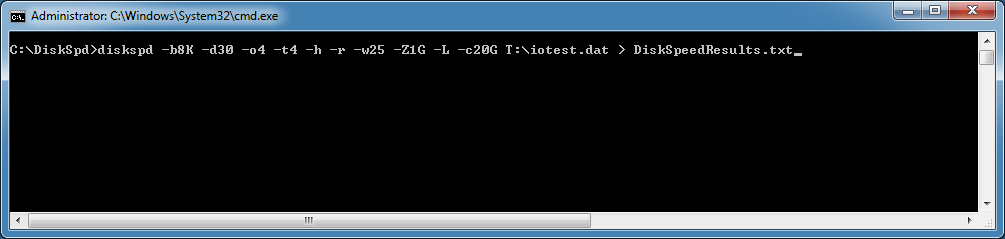 Figure 1: Example command line for DiskSpd
Figure 1: Example command line for DiskSpd
Running the test starts with a default five second warm up time (before any measurements actually start), and then the actual test will run for the specified duration in seconds with a default cool down time of zero seconds. When the test finishes, DiskSpd will provide a description of the test and the detailed results. By default this will be a simple text summary in a text file using the file name that you specified, which will be in the same directory as the diskspd executable.
Here are what the results look like for this particular test run on my workstation.
 Figure 2: Example DiskSpd test results
Figure 2: Example DiskSpd test results
The first section of the results gives you the exact command line that was used for the test, then specifies all of the input parameters that were used for the test run (which include the default values that may not have been specified in the actual command line). Next, the test results are shown starting with the actual test time, thread count, and logical processor count. The CPU section shows the CPU utilization for each logical processor, including user and kernel time, for the test interval.
The more interesting part of the test results comes next. You get the total bytes, total I/Os, MB/second, I/O per second (IOPS), and your average latency in milliseconds. These results are broken out for each thread (four in our case), with separate sections in the results for Total IO, Read IO, and Write IO. The results for each thread should be very similar in most cases. Rather than initially focusing on the absolute values for each measurement, I like to compare the values when I run the same test on different logical drives, (after changing the location of the test file in the command line), which lets you compare the performance for each logical drive.
The last section of the test results is even more interesting. It shows a percentile analysis of the distribution of the latency test results starting from the minimum value in milliseconds going up to the maximum value in milliseconds, broken out for reads, writes, and total latency. The “nines” in the %-ile column refer to the number of nines, where 3-nines means 99.9, 4-nines means 99.99, etc. The reason why the values for the higher percentile rows are the same is because this test had a relatively low number of total operations. If you want to accurately characterize the higher percentiles, you will have to run a longer duration test that generates a higher number of separate I/O operations.
What you want to look for in these results is the point where the values make a large jump. For example, in this test we can see that 99% of the reads had a latency of 1.832 milliseconds or less.
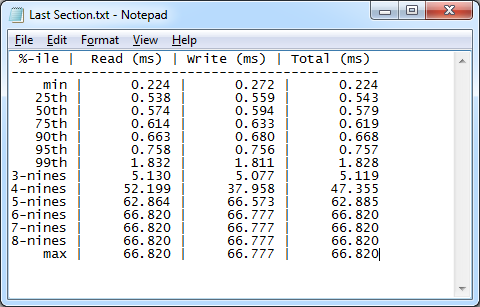 Figure 3: Latency results distribution
Figure 3: Latency results distribution
As you can see, running DiskSpd is actually pretty simple once you understand what the basic parameters mean and how they are used. Not only can you run DiskSpd from an old-fashioned command line, you can also run it using PowerShell. DiskSpd also gives you a lot more detailed information than you get from SQLIO. The more complicated part of using DiskSpd is analyzing and interpreting the results, which is something I will cover in a future article.
52 thoughts on “Using Microsoft DiskSpd to Test Your Storage Subsystem”
Comments are closed.

Is DiskSpd a rebranding of SQLIO?
Nice post Glenn. Nice tool.
Ismail,
No, DiskSpd is not a rebranding of SQLIO. It is a completely different testing tool.
Mike,
Thanks! Glad you liked it.
Nice post. I like to use Diskspd for testing basic storage performance on slow SQL server systems. It is fast, easy to use, and the results are usually pretty clear: Very high latency, low number of IOPS, etc.
Should the SQL Server be idle when this is used? I am looking to test new storage and want to benchmark our existing SAN in production and then compare to the same tests performed on evaluation storage that my organisation will be looking to purchase. Should I have the production SQL instances shutdown and no other work being performed on then whilst testing?
Nice 1! Been having issues with our SAN. SAN Team will be reconfiguring for better results. Will be nice to do some before\after testing.
MonkeyButler,
That depends on what sort of test you decide to run. An intense DskSpd test that runs for more than a few seconds can definitely affect your storage subsystem in a negative way (by putting a heavy load on it). The I/O activity from your normal SQL Server workload will also affect your benchmark results. Ideally, you would want to run DskSpd testing when there is no production workload from SQL Server, to eliminate both possibilities. It would be a more valid test to compare your current system to the evaluation system.
That is what I expected. Thanks.
Whit,
That is a good use case for DiskSpd. You can also run CrystalDiskMark before and after, just to have some more data points.
Is it possible to run this on a server with more than 64 processors? I am receiving the following error.
WARNING: Complete CPU utilization cannot currently be gathered within DISKSPD for this system.
Use alternate mechanisms to gather this data such as perfmon/logman.
Active KGroups 2 > 1 and/or processor count 80 > 64.
Error opening file: ûd120 [2]
…
There has been an error during threads execution
Error generating I/O requests
@Maxwell I had the same problem and it was due to cut and paste from the web, try to manually retype the whole command line
This is just what I needed, when I needed it! I've used SQLIO before, but the output of this is so much better. Thank you!
Maxwell,
From that error message, it appears that not working with more than 64 cores is a known issue or is by design. I have reached out to some people at Microsoft to try to find out more information. Thanks!
Hi Glenn,
it could be that it will not work with more than 64bits, but the specific "error accessing file" happened to me trying to cut and paste the commands from internet.
The reference to "ûd120" (with a strange character near the d120 that is supposed to be -d120 parameter) helped me understanding that something was wrong in the parameters' handling
Norberto,
I think that Maxwell is having a different issue than you had. It looks like his system has 80 cores, and DiskSpd has a problem with that. It does not seem to have anything to do with 32-bit vs. 64-bit
diskspd is not only a freely available tool released by Microsoft, but the source is also freely available via GitHub:
https://github.com/microsoft/diskspd
That means that DiskSpd can only use publicly available APIs to obtain its information, and unfortunately, the API that is called to efficiently get CPU stats doesn't yet support > 64 CPUs.
I'm told that this is being worked on in Windows Server 2016, but can't say for sure what form that will take.
So, for now, systems beyond 64 cores will need to use Perfmon to gather CPU statistics during a run, but the other information should be accurate.
Nice post Glenn. Would it possible to configure block size different for writes and reads? I have a SQL box subsystem to test with 25KB of writes and 46KB for reads and then measuring throughput in MB to compare it with old disk subsystem.
I have thought to test it in two stages and then combine just want to know if there is already better way.
The other comment I got from the guys that wrote diskspd is that you can probably get by with a lot smaller entropy seed. You're using -Z1G. Is there a particular reason for allocating a gig for the entropy buffer? SQLIO used a buffer of about 20MB.
After further testing, you are correct Glenn. While I did remedy the strange character issue by manually keying the command, the issue with > 64 CPU cores is real. Keep in mind the total core count is due to HyperThreading. The server has 40 physical cores and 80 logical processors. The tool works perfectly on a 48 logical core server. Thanks!
Thanks for digging up this info Kevin!
Just wanted to thank you for this post; I will be testing and incorporating it myself into my toolbag. Thanks.
Can Diskspd generate all unique data or unique blocks of data with the diskspd test file? Is this the -Z parameter? Seems like FIO is the only tool capable of doing this.
IOmeter can't generate unique data either.
Question for everyone.
I have been reading about disk performance (iops/latency/throughput). I'm looking for a way to determine the IOPS I can get from my system with less than 10ms. Is it possible ? All these softwares beat up my disk performance with crazy amount of IOPS and very high latency, which is not useful. I want to know how much IOPS my system can handle with acceptable latency.
Thank you
thx for the post. You screen shot shows -T4 which I think means 4 threads but you mention 8 in the comments preceeding the screen shot. The example does show -T8 however :)
Thx! Very helpful post. Would you be able to provide a resource for ballpark metrics required for a healthy SQL environment? For example, what is the min IOPS or min MB/s for an OLTP SQL instance? Or guidance on 3/4/5 9s latency?
Again, many thanks
Hello,
Is there any option that shows me actual Read/Write IO while the Program is running?
How is everyone creating .bat file of different sizes? After thinking back to my old basics I tried using SQLIO and it generated me a .bat file and I used it for diskspd testing. Is everyone doing the same or is there any easy way where we can create .bat file with more than 10 or 20 GB?
When analyzing the results of diskspd, I'm questioning the meaning of total I/O per second.
the total I/O per second is a sunm of both read and Write I/O per Second. Shouldn't it be an Average of both to determine the Disk speed?
I am trying to use the invoke-command powershell cmdlet to fire diskspd load on a number of VMs.
the diskspd command runs fine when I run it in the PowerShell prompt directly inside the VM, but if I fire the command using Invoke-command I see the same error. Any inputs on how this can be fixed?
Invoke-Command -Session $s -ScriptBlock {C:\Diskspd-v2.0.15\amd64fre\diskspd.exe -b8k -d30 -o4 -t2 -h -r -w25 -L -Z1G -c30G -Rxml e:\iostat.dat > result.xml}
Error generating I/O requests
+ CategoryInfo : NotSpecified: (Error generating I/O requests:String) [], RemoteException
+ FullyQualifiedErrorId : NativeCommandError
+ PSComputerName : OS-1
Thank you
I solved this by changing Z1G to Z20M.
My VMs were not capable of accepting 1G value
The XML output in diskspd contains Total IO, Write IO, Read IO threadwise. The txt output has both values in clear text.
There is no way I can directly derive a sum of all threads (Total IO, Write IO, Read IO).
Any suggestions?
Nice one .. its really helps .
Great post. I'm trying to run this on Server 2012 under a local admin account and regardless of the drive location it cannot create the files. all I get is "Error opening file: d:\test\file.dat [2]"
Any idea what this is from?
thanks
DiskSpd does not appear to be able to create testfiles (.dat) larger than 10GB on multi-terabyte volumes which are presented as mountpoints. Both diskspd and CrystalDiskMark appear to want to create the testfiles in the root of the drive. If you have a path such as d:\data1\file.dat where data1 is a mountpoint of a volume of say 1TB mounted on D: where D: is a volume of say 10GB, then DiskSpd will not let you create the testfile greater than 10GB.
I have also tested with the volumes presented as luns/drives, but even here if I have a drive with 1TB free space the largest test file I have been able to create is only 85GB. There appears to be no documentation regarding bugs, errors issues and nowhere to log these issues. It's all provided 'as is'. As a replacement for SQLIO it's a good idea, looking at the results from the small files I have managed to create, but it's a long way for being useful as it does not actually work (i.e. create large enough test files) for most real world scenarios I have seen in the last 5 years.
Can i use DiskSpd on my current database production server? Will it impact performance?
How can i test a specific drive. What parameter should i pass?
Ditto. Replace the – with – and it should work.
Can confirm AA_Online's comments regarding using Mount Points. Still an issue as of version 2.0.17. Frustrating.
Part of the parameter set you give to diskspd along with what IO patterns to use, is a list of file paths for the test files. Just specify the path you want.
I just created a set of 8 100GB testfiles using DiskSpd 2.0.17, under C:\ClusterStorage\Volume\Dir
where Volume is a mounted Storage Spaces Direct volume.
Perhaps there is something different about an S2D volume, but at least it works under that mountpoint.
Diskspd will not cause any problems for SQL Server unless it consumes all available disk space and/or IO resources, starving a running SQL Server.
Should I test with -b8k because a SQL server page is always 8k or should I better test with -b64k because an extend is 64k and I formated my HDD with 64k block size?
I'm a little bit unsure, if the SQL server uses the 64k only when it increases the file size of a database or also when it is reading pages from the disk…
8k reads and writes – single pages – do occur but. They tend to be fairly rare. I recommend capturing perfmon for a few days on an existing system, and basing a test off what is observed. Capture reads/sec, writes/sec, read bytes/sec, write bytes/sec, sec/read, sec/write, and current disk queue length. If taking SQL Server backups, those reads and writes tend to be large (1 mb or max xfer size for adapter usually 512kb) and the queue length is fixed for the backup itself. Checkdb, and index & star maintenance tend to have large IOS as well.
Tx log will be almost exclusively writes if simple recovery mode. 512 byte minimum, 60kb maximum. Max queue length of 32 per txlog for 60k writes.
Database reads can be up to 512kb the default max xfer size but if max xfer is increased sometimes might see even higher.
I recommend not testing average size only; I like to ensure acceptable behavior with large reads and writes also if my workloads can generate them.
I wanted to know what data DiskSpd writes and if there is a way to specify it. My storage system has compression enabled so writing repeated pattern or all zeros does not actually fill the storage media.
Looking into my iotest.dat file I see some random stuff as
¯€øeá™™jƒŠoß,¨7ó:ßý‰MÀ9Ù„Î>sõPqœdg¼U¯^‹ŒLq„¶šà\/RÆÇÜÆ8™Pǽ6mÒ±\3jì‘u•ímÆß™T0¡®#\µ”iŸ€á"Þ!(zé[µÆ¨lÒÀ
€2|0I’jv‰Ú¼C”¡Ÿ'4‹¾o«{3‰9~`™ƒw1/å
o Lýo¹oAàñ_ßñ9\¯p1Oƒ2nO¢¶„ixd¡‹Üé4±
#!æEݼ]4í´y#qìhÚÊWÚYªú-_Ùê(L¾}ìÈ+Ì}ÛÞ/$¼°ãú¿Ee['¯7@•v¡f6˜m«®£8ÉO©[û%õLà©?7¤¤Šbë›Ý–0}÷R¿šy¸ÖŸÈðÖ$ü²€uêBœ´c`v5‘:vË¢ÈÆ'å=íeQÄ56&¯{ÐÆ5¤Þ´S®¦WmßÞŽdbXX¥w_J’T.o¯‘÷ÒŽyê[¯ìû+rF?¨a‹z @{³Bc»-“€Ãg£'â
õÀ)]yêx§îr$Î6í…õ±GW“Í€®[€ð±+·š>1OÀþÃhJ!WôЄý„ b—BœñuOƽo…ñ8 }šUâ/ÛÏýƒ-+3D›<Yuvhâõæ…„dá JZV`¸œZR‡€üÃm^ì‘`¨ç[ˆ{A¾ÆaëîíÍÜ©‚©Ñ
PS: there are some empty (Hex 00) "pages" inside the file too (maybe 10-20 %). On the other hand this should be a similar behavior to SQL server with some empty extends etc.
Can DiskSpd read only test run on an existing file?
I tried to a read only test on an existing file and it wiped out the contents of the file.
If I make the file read only, the test fails to run. Any thoughts on how to run read only test using existing dataset?
diskspd is designed to be run against its own data files. I would not run it against any file that I cared about.
However, there is an option to use the contents of a file that you specify to fill the write buffer with data that you put in the pattern file. See the second form of the -Z option below:
-Z[K|M|G|b] Separate read and write buffers, and initialize a per-target write source buffer sized to the specified number of bytes or KiB, MiB, GiB, or blocks. This write source buffer is initialized with random data, and per-IO write data is selected from it at 4-byte granularity.
-Z[K|M|G|b], Same, but using a file as the source of data to fill the write source buffers.
Also note that diskspd is now open source. You can find it at https://github.com/microsoft/diskspd
It is really a nice article. I learned about DiskSpd tool, and how to use it
Is it valid to use this tool on Hyper-V Virtual machines( ex: SQL Server vhd) for a true iops comparision or should the tool be ran from the host where the VHD's reside?
Thank you,
Jeff
Hi Jeff,
I would run it on both. You will only be able to achieve the performance metrics achieved within your guest though. By that i mean, if you've created a new VM and you want to see what performance you'll get out of it, then you should run the baseline there.
In order to figure out if there are any bottlenecks though, i'd run the same test on your host (Hyper-V host in your case) and compare the results. If you're seeing dramatic differences in your results, consider the formatting of your Guest VHD LUNs.
If the Guest VM is hosted on a Hyper-V host which is hosting multiple guest VMs then you should consider that any baseline you get may be 'as the wind blows' i.e. it could change if VM01 is performing a lot of work while you're testing VM02.
The best way to test would be to evacuate other guest VMs (if possible of course) to other Hyper-V hosts, or turn them off while you're perfoming your testing, then test on your host and your guest and see what perfomance you're realising from both. Compare your results, but be aware that there will be an overhead from it being virtual (albeit small these days!) and an over head from the formatting you have on your host and guest.
Hope that helps!
Thanks,
Dan
Any suggestions for good test-patterns for:
-Windows OS (I guess a lot of small mixed random read/writes with enabled caching)
-File-server (I guess rather big non-mixed seq. reads and seq. seq. writes).
I have no idea what I should set for block size, queue depth, threads etc?