
Incremental Statistics are NOT used by the Query Optimizer
In my previous post on incremental statistics, a new feature in SQL Server 2014, I demonstrated how they can help decrease maintenance task duration. This is because statistics can be updated at the partition level, and the changes merged into the main histogram for the table. I also noted that the Query Optimizer doesn’t use those partition-level statistics when generating query plans, which may be something that people were expecting. No documentation exists to state that incremental statistics will, or will not, be used by the Query Optimizer. So how do you know? You have to test it. :-)
The Setup
The setup for this test will be similar to the one in the last post, but with less data. Note that the default sizes are smaller for the data files, and the script only loads in a few million rows of data:
USE [AdventureWorks2014_Partition];
GO
/* add filesgroups */
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011];
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012];
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013];
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014];
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015];
/* add files */
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE
(
FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf',
NAME = N'2011', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB
) TO FILEGROUP [FG2011];
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE
(
FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf',
NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB
) TO FILEGROUP [FG2012];
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE
(
FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf',
NAME = N'2013', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB
) TO FILEGROUP [FG2013];
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE
(
FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf',
NAME = N'2014', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB
) TO FILEGROUP [FG2014];
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE
(
FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf',
NAME = N'2015', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB
) TO FILEGROUP [FG2015];
CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime])
AS RANGE RIGHT FOR VALUES
(
'20110101', --everything in 2011
'20120101', --everything in 2012
'20130101', --everything in 2013
'20140101', --everything in 2014
'20150101' --everything in 2015
);
GO
CREATE PARTITION SCHEME [OrderDateRangePScheme]
AS
PARTITION [OrderDateRangePFN] TO
([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]);
GO
CREATE TABLE [dbo].[Orders]
(
[PurchaseOrderID] [int] NOT NULL,
[EmployeeID] [int] NULL,
[VendorID] [int] NULL,
[TaxAmt] [money] NULL,
[Freight] [money] NULL,
[SubTotal] [money] NULL,
[Status] [tinyint] NOT NULL,
[RevisionNumber] [tinyint] NULL,
[ModifiedDate] [datetime] NULL,
[ShipMethodID] [tinyint] NULL,
[ShipDate] [datetime] NOT NULL,
[OrderDate] [datetime] NOT NULL,
[TotalDue] [money] NULL
) ON [OrderDateRangePScheme] (OrderDate);When we create the clustered index for dbo.Orders, we will create it without the STATISTICS_INCREMENTAL option enabled, so we’ll start with a traditional partitioned table with no incremental statistics:
ALTER TABLE [dbo].[Orders]
ADD CONSTRAINT [OrdersPK]
PRIMARY KEY CLUSTERED ([OrderDate], [PurchaseOrderID])
ON [OrderDateRangePScheme] ([OrderDate]);
Next we’ll load in about 4 million rows, which takes just under a minute on my machine:
SET NOCOUNT ON;
DECLARE @Loops SMALLINT = 0;
DECLARE @Increment INT = 3000;
WHILE @Loops < 1000
BEGIN
INSERT [dbo].[Orders]
([PurchaseOrderID]
,[EmployeeID]
,[VendorID]
,[TaxAmt]
,[Freight]
,[SubTotal]
,[Status]
,[RevisionNumber]
,[ModifiedDate]
,[ShipMethodID]
,[ShipDate]
,[OrderDate]
,[TotalDue] )
SELECT [PurchaseOrderID] + @Increment
, [EmployeeID]
, [VendorID]
, [TaxAmt]
, [Freight]
, [SubTotal]
, [Status]
, [RevisionNumber]
, [ModifiedDate]
, [ShipMethodID]
, DATEADD(DAY, 365, [ShipDate])
, DATEADD(DAY, 365, [OrderDate])
, [TotalDue] + 365
FROM [Purchasing].[PurchaseOrderHeader];
CHECKPOINT;
SET @Loops = @Loops + 1;
SET @Increment = @Increment + 5000;
ENDAfter the data load, we’ll update statistics with a FULLSCAN (so we can create a consistent-as-possible histogram for tests) and then verify what data we have in each partition:
UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN;
SELECT $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number]
, MIN([o].[OrderDate]) AS [Min_Order_Date]
, MAX([o].[OrderDate]) AS [Max_Order_Date]
, COUNT(*) AS [Rows_In_Partition]
FROM [dbo].[Orders] AS [o]
GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate])
ORDER BY [Partition Number]; Data in each partition after data load
Data in each partition after data load
Most of the data is in the 2015 partition, but there’s also data for 2012, 2013, and 2014. And if we check the output from the undocumented DMV sys.dm_db_stats_properties_internal, we can see that no partition level statistics exist:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id]; sys.dm_db_stats_properties_internal output showing only one statistic for dbo.Orders
sys.dm_db_stats_properties_internal output showing only one statistic for dbo.Orders
The Test
Testing requires a simple query that we can use to verify that partition elimination occurs, and also check estimates based on statistics. The query doesn’t return any data, but that doesn’t matter, we’re interested in what the optimizer thought it would return, based on statistics:
SELECT *
FROM [dbo].[Orders]
WHERE [OrderDate] = '2014-04-01';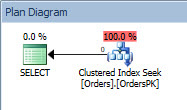 Query plan for the SELECT statement
Query plan for the SELECT statement
The plan has a Clustered Index Seek, and if we check the properties, we see that it estimated 4000 rows, and accessed partition 5, which contains 2014 data.
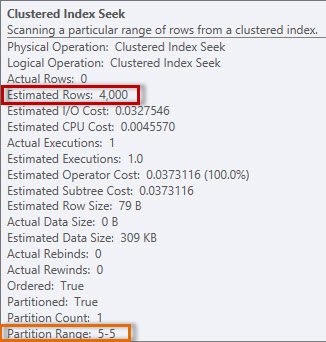 Estimated and actual information from the Clustered Index Seek
Estimated and actual information from the Clustered Index Seek
If we look at the histogram for the dbo.Orders table, specifically in the area of April 2014 data, we see that there is no step for 2014-04-01, so the optimizer estimates the number of rows for that date using the step for 2014-04-24, where the AVG_RANGE_ROWS is 4000 (for any one value between 2014-02-14 and 2014-04-23 inclusive, the optimizer will estimate that 4000 rows will be returned).
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');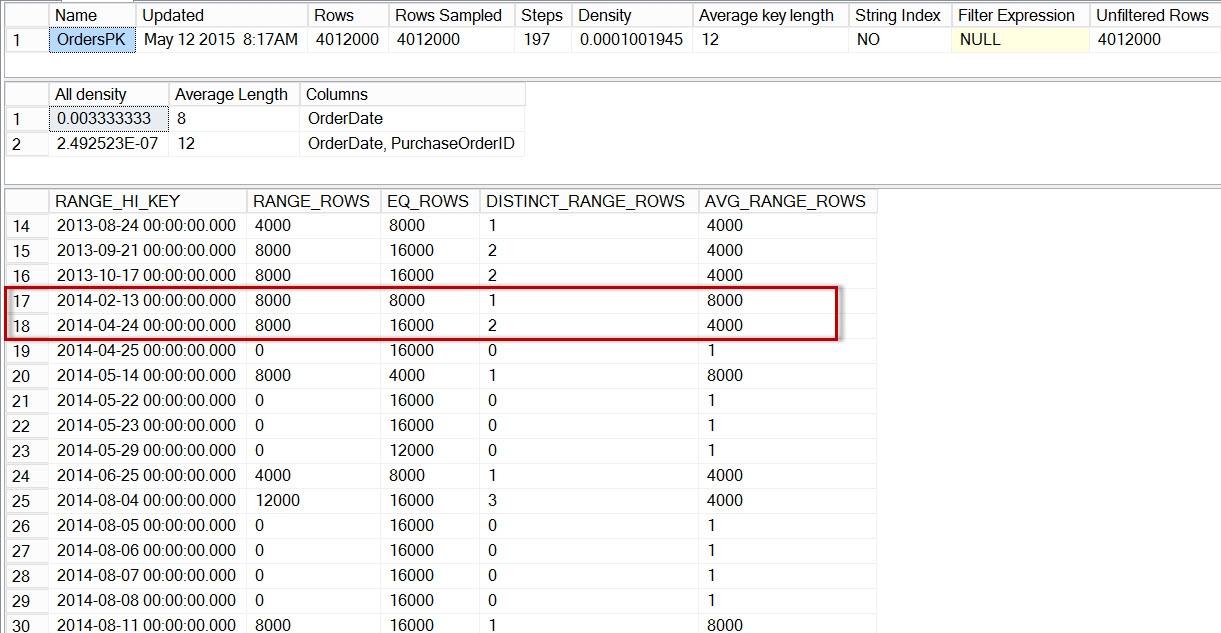 Distribution in the dbo.Orders histogram
Distribution in the dbo.Orders histogram
The estimate and the plan are completely expected. Let’s enable incremental statistics and see what we get.
ALTER INDEX [OrdersPK] ON [dbo].[Orders]
REBUILD WITH (STATISTICS_INCREMENTAL = ON);
GO
UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN;If we re-run our query against sys.dm_db_stats_properties_internal, we can see the incremental statistics:
 sys.dm_db_stats_properties_internal showing incremental statistics information
sys.dm_db_stats_properties_internal showing incremental statistics information
Now let’s re-run our query again dbo.Orders, and we’ll run DBCC FREEPROCCACHE first to fully ensure the plan isn’t re-used:
DBCC FREEPROCCACHE;
GO
SELECT *
FROM [dbo].[Orders]
WHERE [OrderDate] = '2014-04-01';We get the same plan, and the same estimate:
Query plan for the SELECT statement
Estimated and actual information from the Clustered Index Seek
If we check the main histogram for dbo.Orders, we see nearly the same histogram as before:
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');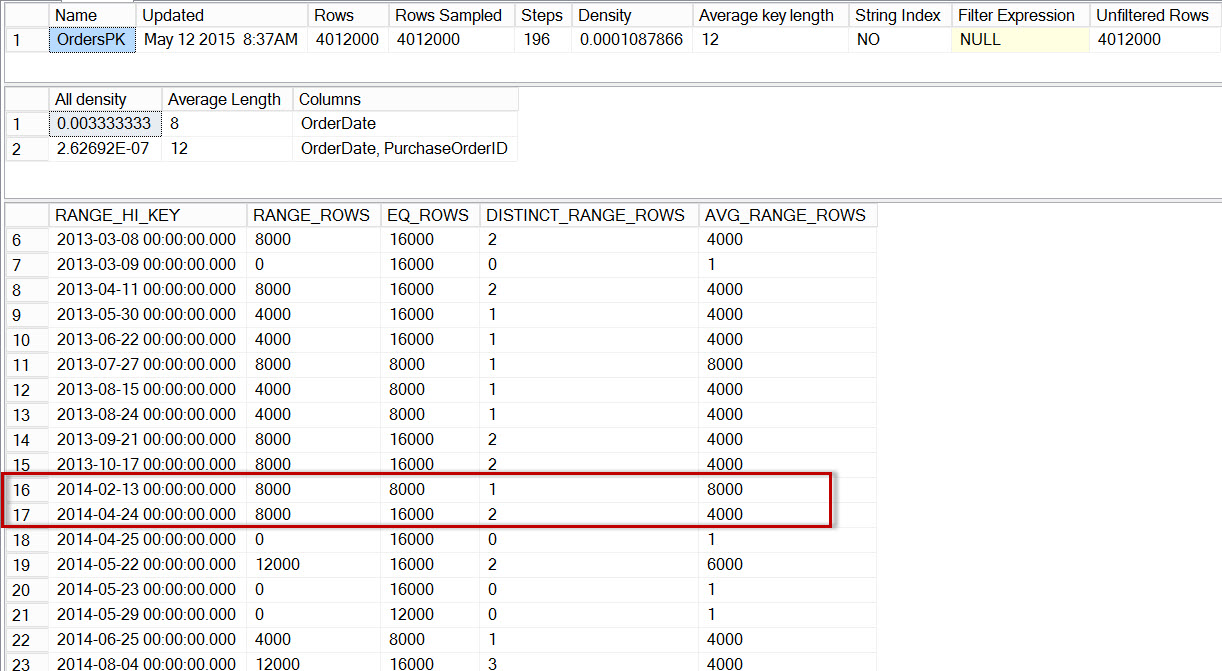 Histogram for dbo.Orders, after enabling incremental statistics
Histogram for dbo.Orders, after enabling incremental statistics
Now, let’s check the histogram for the partition with 2014 data (we can do this using undocumented trace flag 2309, which allows for a partition number to be specified as an additional argument to DBCC SHOW_STATISTICS):
DBCC TRACEON(2309);
GO
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK', 6);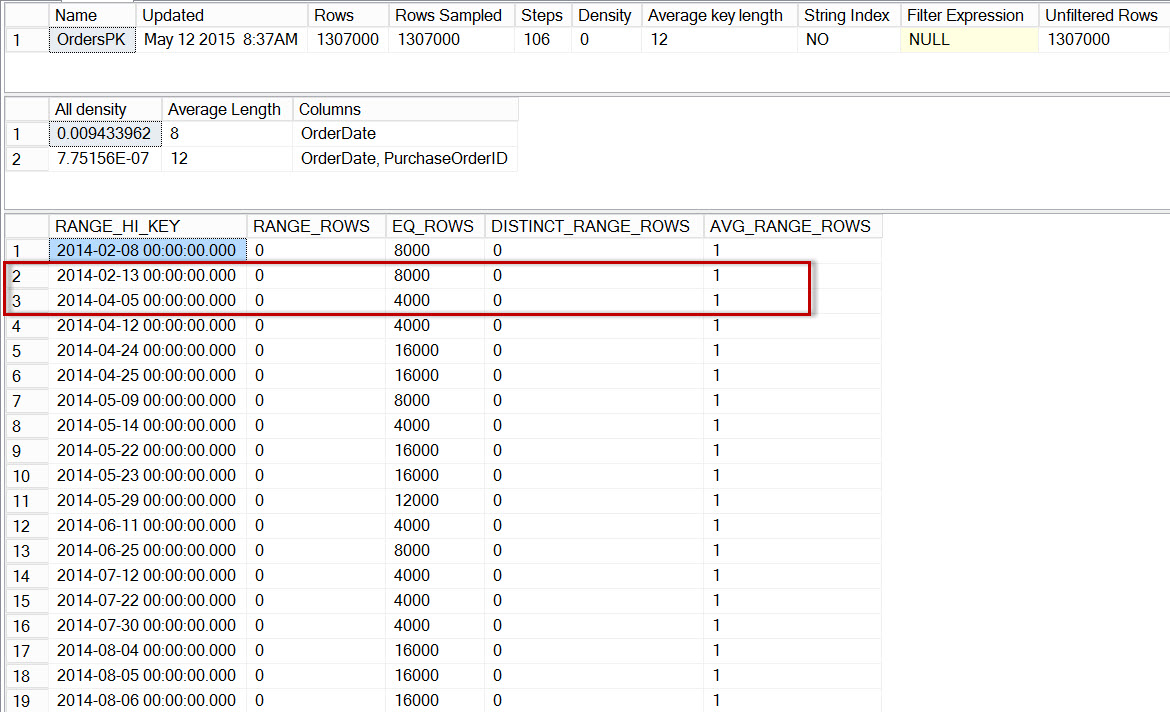 Histogram for the 2014 partition of dbo.Orders, after enabling incremental statistics
Histogram for the 2014 partition of dbo.Orders, after enabling incremental statistics
Here we see that, again, there is no step for 2014-04-01, but there are 0 RANGE_ROWS between 2014-02-13 and 2014-04-05, with an AVG_RANGE_ROWS of 1. If the optimizer was using the histogram for the partition level statistics, then the estimate for the number of rows for 2014-04-01 would be 1.
Note: The partition identified as used in the query plan is 5, but you’ll notice that the DBCC SHOW_STATISTICS statement references partition 6. The assumption is an inconsistency in statistics metadata (a common off-by-one error, likely due to 0-based vs. 1-based counting), which may or may not be fixed in the future. Understand that the trace flag is not documented at this time, and that it is not recommended to use in a production environment.
Summary
The addition of incremental statistics in the SQL Server 2014 release is a step in the right direction for improved cardinality estimates for partitioned tables. However, as we’ve demonstrated, the current value of incremental statistics is limited to decreased maintenance durations, as those incremental statistics are not yet used by the Query Optimizer.
10 thoughts on “Incremental Statistics are NOT used by the Query Optimizer”
Comments are closed.

Hi Erin,
Thanks for this analysis. I just wanted to chime in and note that I've observed this off-by-one behavior with RANGE RIGHT partitioning, but the partition_number lines up correctly with RANGE LEFT partition functions. A curiosity, for sure.
And it will probably never be fixed, now, due to backward compatibility issues. Kind of too bad when great features are affected by lapses in attention to detail. :-(
What am I missing? If the optimizer is not using the stats then what was the point of adding the feature.
Hello Erin,
Great article! I'm not sure if I missed something here… But what is the point of incremental statistics if they aren't used by the Query Optmizer?
I believe that the intent of Erin's article is to shed light on the fact that the individual partition-level stats pages are not being used to generate cardinality estimates. Those are still derived from the merged stats page. The current benefit of incremental statistics is limited to maintenance operations (updating stats only on the partitions that need the update and not on the entire stats object).
The merged stats for the whole table are still used by the optimizer, and those benefit from being updated only for the active partition (which is much less work than updating stats for the entire table, and can enable
FULLSCANin cases where it wouldn't be possible across the whole table – this can lead to much more accurate overall histograms). While it's true that it would be nice to use a more accurate histogram for a query that is able to eliminate all other partitions, this is like many other features – v1 implementation is neither perfect nor complete, but there are improvements they can invest in later (perhaps depending on feedback, feature uptake, etc). ColumnStore and Hekaton are two features that come to mind that had narrow use cases when originally implemented but are much more compelling in their newer implementations.Reran with SQL Server 2016 CTP2, similar results but we get the partition level stats on the first check against dm_db_stats_properties_internal.
Hey David – can you explain what you mean when you say "we get the partition level stats on the first check against dm_db_stats_properties_internal"? I was hoping to test this last week but didn't get the chance. Thanks!
Erin
I know it has been awhile since this post and the last comment, but I'm trying to use sys.dm_db_stats_properties_internal modification_counter to determine if I want to update statistics on a partition and I have found that for some partitions, the modification counter doesn't reset to 0 after you update statistics, but the last last_updated column does. Anyone else noticed the same thing?
Hey William-
I haven't seen that behavior – where AFTER you update statistics on a partition you do not see the modification counter set to 0. Did you just update the statistics at the partition level, or for the entire table? If you can try to describe what you did, I can see if I can reproduce it.
Thanks!
Erin