
T-SQL Tuesday #64 : One Trigger or Many?

It's that Tuesday of the month – you know, the one when the blogger block party known as T-SQL Tuesday happens. This month it is hosted by Russ Thomas (@SQLJudo), and the topic is, "Calling All Tuners and Gear Heads." I'm going to treat a performance-related problem here, though I do apologize that it might not be fully in line with the guidelines Russ set out in his invitation (I'm not going to use hints, trace flags or plan guides).
At SQLBits last week, I gave a presentation on triggers, and my good friend and fellow MVP Erland Sommarskog happened to attend. At one point I suggested that before creating a new trigger on a table, you should check to see if any triggers already exist, and consider combining the logic instead of adding an additional trigger. My reasons were primarily for code maintainability, but also for performance. Erland asked if I had ever tested to see if there was any additional overhead in having multiple triggers fire for the same action, and I had to admit that, no, I hadn't done anything extensive. So I'm going to do that now.
In AdventureWorks2014, I created a simple set of tables that basically represent sys.all_objects (~2,700 rows) and sys.all_columns (~9,500 rows). I wanted to measure the effect on the workload of various approaches to updating both tables – essentially you have users updating the columns table, and you use a trigger to update a different column in the same table, and a few columns in the objects table.
- T1: Baseline: Assume that you can control all data access through a stored procedure; in this case, the updates against both tables can be performed directly, with no need for triggers. (This isn't practical in the real world, because you can't reliably prohibit direct access to the tables.)
- T2: Single trigger against other table: Assume that you can control the update statement against the affected table and add other columns, but the updates to the secondary table need to be implemented with a trigger. We'll update all three columns with one statement.
- T3: Single trigger against both tables: In this case, we have a trigger with two statements, one that updates the other column in the affected table, and one that updates all three columns in the secondary table.
- T4: Single trigger against both tables: Like T3, but this time, we have a trigger with four statements, one that updates the other column in the affected table, and a statement for each column updated in the secondary table. This might be the way it's handled if the requirements are added over time and a separate statement is deemed safer in terms of regression testing.
- T5: Two triggers: One trigger updates just the affected table; the other uses a single statement to update the three columns in the secondary table. This might be the way it's done if the other triggers aren't noticed or if modifying them is prohibited.
- T6: Four triggers: One trigger updates just the affected table; the other three update each column in the secondary table. Again, this might be the way it's done if you don't know the other triggers exist, or if you're afraid to touch the other triggers due to regression concerns.
Here is the source data we're dealing with:
-- sys.all_objects:
SELECT * INTO dbo.src FROM sys.all_objects;
CREATE UNIQUE CLUSTERED INDEX x ON dbo.src([object_id]);
GO
-- sys.all_columns:
SELECT * INTO dbo.tr1 FROM sys.all_columns;
CREATE UNIQUE CLUSTERED INDEX x ON dbo.tr1([object_id], column_id);
-- repeat 5 times: tr2, tr3, tr4, tr5, tr6Now, for each of the 6 tests, we're going to run our updates 1,000 times, and measure the length of time
T1: Baseline
This is the scenario where we're lucky enough to avoid triggers (again, not very realistic). In this case, we'll be measuring the reads and duration of this batch. I put /*real*/ into the query text so that I can easily pull the stats for just these statements, and not any statements from within the triggers, since ultimately the metrics roll up to the statements that invoke the triggers. Also note that the actual updates I'm making do not really make any sense, so ignore that I'm setting the collation to the server/instance name and the object's principal_id to the current session's session_id.
UPDATE /*real*/ dbo.tr1 SET name += N'',
collation_name = @@SERVERNAME
WHERE name LIKE '%s%';
UPDATE /*real*/ s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN dbo.tr1 AS t
ON s.[object_id] = t.[object_id]
WHERE t.name LIKE '%s%';
GO 1000T2: Single Trigger
For this we need the following simple trigger, which only updates dbo.src:
CREATE TRIGGER dbo.tr_tr2
ON dbo.tr2
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = SUSER_ID()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GOThen our batch only needs to update the two columns in the primary table:
UPDATE /*real*/ dbo.tr2 SET name += N'', collation_name = @@SERVERNAME
WHERE name LIKE '%s%';
GO 1000T3: Single trigger against both tables
For this test, our trigger looks like this:
CREATE TRIGGER dbo.tr_tr3
ON dbo.tr3
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr3 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GOAnd now the batch we're testing merely has to update the original column in the primary table; the other one is handled by the trigger:
UPDATE /*real*/ dbo.tr3 SET name += N''
WHERE name LIKE '%s%';
GO 1000T4: Single trigger against both tables
This is just like T3, but now the trigger has four statements:
CREATE TRIGGER dbo.tr_tr4
ON dbo.tr4
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr4 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GOThe test batch is unchanged:
UPDATE /*real*/ dbo.tr4 SET name += N''
WHERE name LIKE '%s%';
GO 1000T5: Two triggers
Here we have one trigger to update the primary table, and one trigger to update the secondary table:
CREATE TRIGGER dbo.tr_tr5_1
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr5 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr5_2
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GOThe test batch is again very basic:
UPDATE /*real*/ dbo.tr5 SET name += N''
WHERE name LIKE '%s%';
GO 1000T6: Four triggers
This time we have a trigger for each column that is affected; one in the primary table, and three in the secondary tables.
CREATE TRIGGER dbo.tr_tr6_1
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr6 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_2
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_3
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_4
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GOAnd the test batch:
UPDATE /*real*/ dbo.tr6 SET name += N''
WHERE name LIKE '%s%';
GO 1000Measuring workload impact
Finally, I wrote a simple query against sys.dm_exec_query_stats to measure reads and duration for each test:
SELECT
[cmd] = SUBSTRING(t.text, CHARINDEX(N'U', t.text), 23),
avg_elapsed_time = total_elapsed_time / execution_count * 1.0,
total_logical_reads
FROM sys.dm_exec_query_stats AS s
CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t
WHERE t.text LIKE N'%UPDATE /*real*/%'
ORDER BY cmd;Results
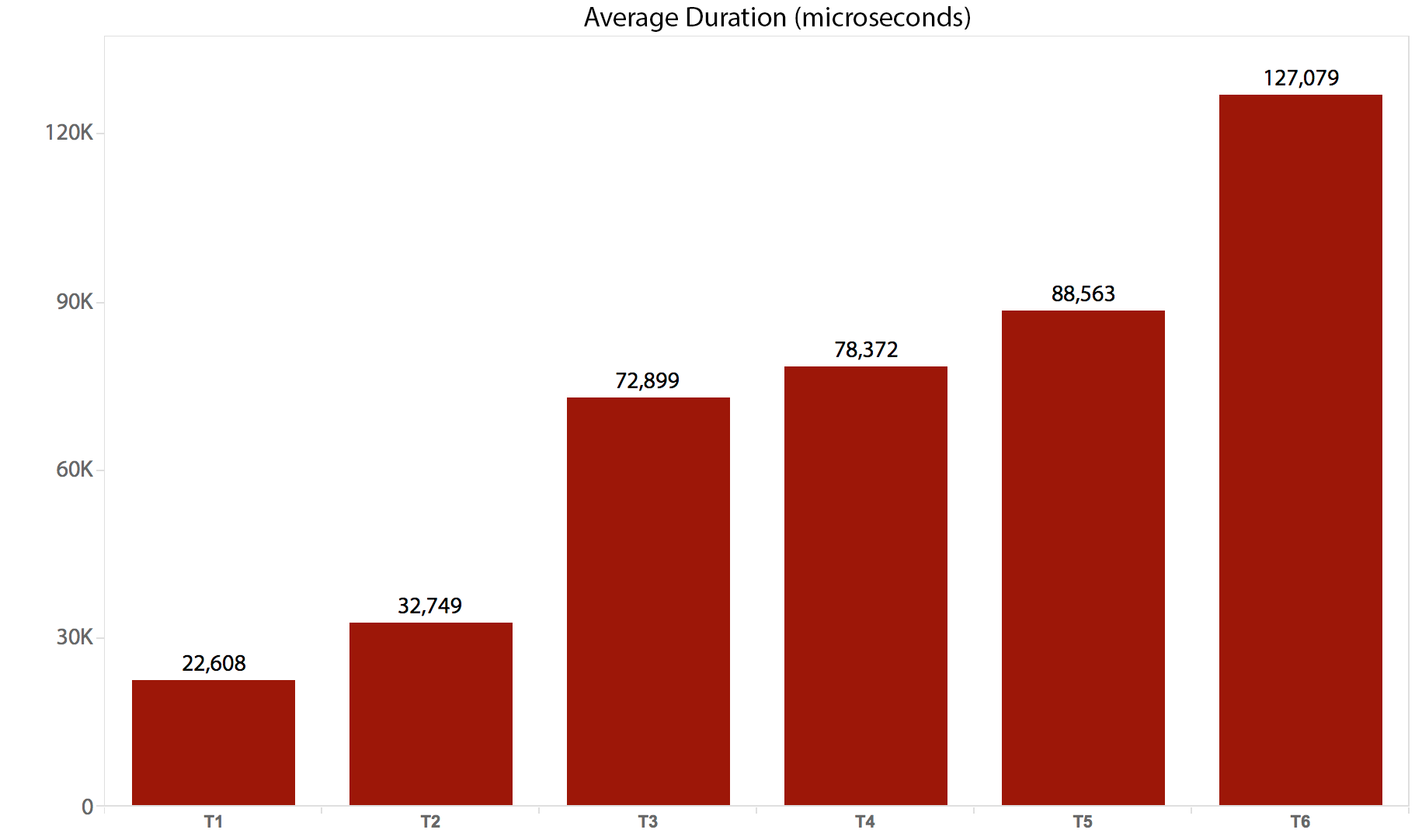
I ran the tests 10 times, collected the results, and averaged everything. Here is how it broke down:
| Test/Batch | Average Duration (microseconds) |
Total Reads (8K pages) |
|---|---|---|
| T1: UPDATE /*real*/ dbo.tr1 … | 22,608 | 205,134 |
| T2: UPDATE /*real*/ dbo.tr2 … | 32,749 | 11,331,628 |
| T3: UPDATE /*real*/ dbo.tr3 … | 72,899 | 22,838,308 |
| T4: UPDATE /*real*/ dbo.tr4 … | 78,372 | 44,463,275 |
| T5: UPDATE /*real*/ dbo.tr5 … | 88,563 | 41,514,778 |
| T6: UPDATE /*real*/ dbo.tr6 … | 127,079 | 100,330,753 |
And here is a graphical representation of the duration:
Conclusion
It is clear that, in this case, there is some substantial overhead for each trigger that gets invoked – all of these batches ultimately affected the same number of rows, but in some cases the same rows were touched multiple times. I will probably perform further follow-on testing to measure the difference when the same row is never touched more than once – a more complicated schema, perhaps, where 5 or 10 other tables have to be touched every time, and these different statements could be in a single trigger or in multiple. My guess is that the overhead differences will be driven more by things like concurrency and the number of rows affected than by the overhead of the trigger itself – but we shall see.
Want to try the demo yourself? Download the script here.
10 thoughts on “T-SQL Tuesday #64 : One Trigger or Many?”
Comments are closed.

From this data I do not derive the conclusion that *additional* triggers cost a lot of throughput. The first one clearly does. After that adding a second trigger did very little (T4 -> T5). Adding two more (T5 -> T6) is kind of in line with that (it's about twice as much performance cost as expected from the previous test – reason could be anything).
Maybe you should test N triggers with each trigger doing the same thing (maybe have each increment a different integer column). We should see a linear progression in wallclock time starting with N = 1.
Right now the tests are too mixed up for my taste.
@tobi,
Not quite sure I follow your objection. The only difference between T4 and T6 is that the same statements, affecting the same number of rows, are executed from one trigger in T4 and four triggers in T6. T5 deviated from that a bit in that the second trigger combined the three updates into a single operation, and I think that's why it didn't go up linearly.
Hi Aaron,
A lot of the overhead is the enabling of the version store I guess, so we should see increase in tempdb IOPS and transactions as the various virtual tables need to be maintained.
Do you think we can correlate the differences as we add triggers back to an increase in transactions/sec in the tempdb as more and more of these virtual tables need to be created ?
Thanks Bob, yes I suspect the bulk of the overhead is due to extra flexing in tempdb, though I haven't investigated metrics to prove that theory. Yet. :-)
What is environmental setting for your SSMS. Its looking good.
Thanks, that is what my SSMS looks like; I did that manually through Tools > Options > Fonts and Colors.
What you're seeing on this page, though, is just CSS. We use a plug-in called WP-GeSHi, which does automatic syntax highlighting for a variety of languages.
If i want my SSMS to look exactly like this then what and all colors i need to keep. Like Backgroung :Black etc..Do you have a list please share if possible. Its really looking cool. may not be useful or valuable comment but still i want that setup in my SSMS.
It was a manual process. Basically highlight text editor and make the background dark and the foreground light:
(Mine are RGB(228,228,228) for Item foreground and RGB(64,64,64) for Item background.)
Then go down the list and change the "Item foreground" color for things you want to change, using the Custom… button. Put a snippet of text in a query window that has just about everything – DMVs, functions, keywords, system procedures, comments, highlighted text, string, etc. so you can see the effects after every change:
You'll have to play with it on your own to get the settings you like. Here are some of the other customizations that were easy to track down:
(Note that this setup may differ slightly from the CSS implemented for this site; for example, my system stored procedures are a reddish color, but the above snippet shows yellow.)
Also, see https://blogs.sentryone.com/aaronbertrand/making-ssms-pretty-my-dark-theme/