
Proactive SQL Server Health Checks, Part 1 : Disk Space
As 2014 winds down, I’m kicking off a series of posts on proactive SQL Server health checks, based on one I wrote back at the beginning of this year – Performance Issues: The First Encounter. In that post, I discussed what I look for first when troubleshooting a performance issue in an unfamiliar environment. In this series of posts, I want to talk about what I look for when I check in with my long-term customers. We provide a Remote DBA service, and one of our regular tasks is a monthly “mini” health audit of their environment. We have monitoring in place and, typically, I’m working on projects, so I’m in the environment regularly. But as an additional step to make sure we’re not missing anything, once a month we go through the same data we collect in our standard health audit and look for anything out of the ordinary. That could be many things, right? Yes! So, let’s start with space.
Whoa, space? Yes, space. Don’t worry, I’ll get to other topics. ☺
What to check
Why would I start with space? Because it’s something I often see neglected, and if you run out of disk space for your database files, you become extremely limited in what you can do in your database. Need to add data but can’t grow the file because the disk is full? Sorry, now users can’t add data. Not taking log backups for some reason, so the transaction log fills up the drive? Sorry, now you can’t modify any data. Space is critical. We have jobs that monitor free space on disk and in the files, but I still verify the following for every audit, and compare the values to those from the previous month:
- Size of each log file
- Size of each data file
- Free space in each data file
- Free space on each drive with database files
- Free space on each drive with backup files
Log File Growth
The majority of issues I see related to disk space are because of log file growth. The growth typically occurs for one of two reasons:
- The database is in FULL recovery and transaction log backups aren’t being taken for some reason
- Someone runs a single, very large transaction which consumes all existing log space, forcing the file to grow
I’ve also seen the log file grow as part of index maintenance. For rebuilds, every allocation is logged and for large indexes, that can generate a significant amount of log. Even with regular transaction log backups, the log can still grow faster than the backups can occur. To manage the log you need to adjust backup frequency, or modify your index maintenance methodology.
You need to determine why the log file grew, which can be tricky unless you’re tracking it. I have a job that runs every hour to snapshot log file size and usage:
USE [Baselines];
GO
IF (NOT EXISTS (SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'dbo'
AND TABLE_NAME = 'SQLskills_TrackLogSpace'))
BEGIN
CREATE TABLE [dbo].[SQLskills_TrackLogSpace](
[DatabaseName] [VARCHAR](250) NULL,
[LogSizeMB] [DECIMAL](38, 0) NULL,
[LogSpaceUsed] [DECIMAL](38, 0) NULL,
[LogStatus] [TINYINT] NULL,
[CaptureDate] [DATETIME2](7) NULL
) ON [PRIMARY];
ALTER TABLE [dbo].[SQLskills_TrackLogSpace] ADD DEFAULT (SYSDATETIME()) FOR [CaptureDate];
END
CREATE TABLE #LogSpace_Temp (
DatabaseName VARCHAR(100),
LogSizeMB DECIMAL(10,2),
LogSpaceUsed DECIMAL(10,2),
LogStatus VARCHAR(1)
);
INSERT INTO #LogSpace_Temp EXEC('dbcc sqlperf(logspace)');
INSERT INTO Baselines.dbo.SQLskills_TrackLogSpace
(DatabaseName, LogSizeMB, LogSpaceUsed, LogStatus)
SELECT DatabaseName, LogSizeMB, LogSpaceUsed, LogStatus
FROM #LogSpace_Temp;
DROP TABLE #LogSpace_Temp;I use this information to determine when the log file started to grow, and I start looking through the logs and job history to see what additional information I can find. Log growth should be static – the log should be appropriately sized and managed through backups (if running in FULL recovery), and if the file needs to be larger, I need to understand why, and re-size it accordingly.
If you’re dealing with this issue, and you weren’t already proactively tracking file growth events, you may still be able to figure out what happened. Auto-growth events are captured by SQL Server; SQL Sentry's Aaron Bertrand blogged about this back in 2007, where he shows how to discover when these events happened (as long as they were recent enough to still exist in the default trace).
Size and Free Space in Data Files
You have probably already heard that your data files should be pre-sized so they do not have to grow automatically. If you follow this guidance, you probably haven’t experienced the event where the data file grows unexpectedly. But if you’re not managing your data files, then you probably have growth occurring regularly – whether you realize it or not (especially with the default growth settings of 10% and 1 MB).
There’s a trick to pre-sizing data files – you don’t want to size a database too large, because remember, if you to restore to, say, a dev or QA environment, the files are sized the same, even if they’re not full of data. But you still want to manually manage growth. I find that DBAs have the hardest time with new databases. The business users have no idea about growth rates and how much data is being added, and that database is a bit of a loose cannon in your environment. You need to pay close attention to these files until you have a handle on size and expected growth. I use a query that gives information about the size and free space:
SELECT
[file_id] AS [File ID],
[type] AS [File Type],
substring([physical_name],1,1) AS [Drive],
[name] AS [Logical Name],
[physical_name] AS [Physical Name],
CAST([size] as DECIMAL(38,0))/128. AS [File Size MB],
CAST(FILEPROPERTY([name],'SpaceUsed') AS DECIMAL(38,0))/128. AS [Space Used MB],
(CAST([size] AS DECIMAL(38,0))/128) - (CAST(FILEPROPERTY([name],'SpaceUsed') AS DECIMAL(38,0))/128.) AS [Free Space],
[max_size] AS [Max Size],
[is_percent_growth] AS [Percent Growth Enabled],
[growth] AS [Growth Rate],
SYSDATETIME() AS [Current Date]
FROM sys.database_files;Every month, I check the size of the data files and the space used, then decide whether the size needs to be increased. I also monitor the default trace for growth events, as this tells me exactly when growth occurs. With the exception of new databases, I can always stay ahead of automatic file growth and handle it manually. Ok, almost always. Right before the holidays last year, I was notified by a customer’s IT department about low free space on a drive (hold that thought for the next section). Now, the notification is based on a threshold of less than 20% free. This drive was over 1TB, so there was about 150GB free when I checked the drive. It wasn’t an emergency, yet, but I needed to understand where the space had gone.
In checking the database files for one database, I could see that they were full – and the previous month each file had over 50GB free. I then dug into table sizes, and found that in one table, over 270 million rows had been added in the past 16 days – totaling over 100GB of data. Turns out there had been a code modification and the new code was logging more information than intended. We quickly set up a job to purge the rows and recover the free space in the files (and they fixed the code). However, I couldn’t recover disk space – I would have to shrink the files, and that wasn’t an option. I then had to determine how much space was left on disk and decide if it was an amount I was comfortable with or not. My comfort level is dependent upon knowing how much data is being added per month – the typical growth rate. And I only know how much data is being added because I monitor file use and can estimate how much space will be needed for this month, for this year, and for the next two years.
Drive Space
I mentioned earlier that we have jobs to monitor free space on disk. This is based on a percentage, not a fixed amount. My general rule of thumb has been to send notifications when less than 10% of the disk is free, but for some drives, you may need to set that higher. For example, with a 1 TB drive, I get notified when there is less than 100GB free. With a 100GB drive, I get notified when there is less than 10GB free. With a 20GB drive… well, you see where I’m going with this. That threshold needs to alert you before there’s a problem. If I only have 10GB free on a drive that hosts a log file, I might not have enough time to react before it shows up as a problem for the users – depending on how often I’m checking the free size space and what the problem is.
It’s very easy to use xp_fixeddrives to check free space, but I wouldn’t recommend this as it is undocumented and the use of extended stored procedures in general has been deprecated. It also doesn’t report the total size of each drive, and may not report on all drive types that your databases may be using. As long as you’re running SQL Server 2008R2 SP1 or higher, you can use the much more convenient sys.dm_os_volume_stats to get the information you need, at least about the drives where database files exist:
SELECT DISTINCT
vs.volume_mount_point AS [Drive],
vs.logical_volume_name AS [Drive Name],
vs.total_bytes/1024/1024 AS [Drive Size MB],
vs.available_bytes/1024/1024 AS [Drive Free Space MB]
FROM sys.master_files AS f
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) AS vs
ORDER BY vs.volume_mount_point;I often see a problem with drive space on volumes that host tempdb. I’ve lost count of the times I’ve had clients with unexplained tempdb growth. Sometimes it’s just a few GB; most recently it was 200GB. Tempdb is a tricky beast – there’s no formula to follow when sizing it, and too often it’s placed on a drive with little free space that can’t handle the crazy event caused by the rookie developer or DBA. Sizing the tempdb data files requires you to run your workload for a “normal” business cycle to determine how much it uses tempdb, and then size it accordingly.
I recently heard a suggestion for a way to avoid running out of space on a drive: create a database with no data, and size the files so they consume however much space you want to “set aside.” Then, if you run into an issue, just drop the database and viola, you have free space again. Personally, I think this creates all kind of other issues and wouldn’t recommend it. But if you have storage administrators who don’t like seeing hundreds of unused GBs on a drive, this would be one way to make a drive “look” full. It reminds me of something I’ve heard a good friend of mine say: “If I can’t work with you, I’ll work around you.”
Backups
One of the primary tasks of a DBA is to protect the data. Backups are one method used to protect it, and as such, the drives that hold those backups are an integral part of a DBA’s life. Presumably you’re keeping one or more backups online, to restore immediately if needed. Your SLA and DR run book help dictate how many backups you keep online, and you must ensure you have that space available. I advocate that you also don’t delete old backups until the current backup has completed successfully. It’s way too easy to fall into the trap of deleting old backups, then running the current backup. But what happens if the current backup fails? And, what happens if you’re using compression? Wait a second… compressed backups are smaller right? They are smaller, in the end. But did you know the .bak file size usually starts out larger than the end size? You can use trace flag 3042 to change this behavior, but you should be thinking that with backups, you need plenty of space. If your backup is 100GB, and you’re keeping 3 days’ worth online, you need 300GB for the 3 days of backups, and then probably a healthy amount (2X current database size) free for the next backup. Yes, this means that at any given time you will have plenty more than 100GB free on this drive. That’s ok. It’s better than having the delete job succeed, and the backup job fail, and find out three days later you have no backups at all (I had that happen to a customer at my previous job).
Most databases just get larger over time, which means that backups get larger as well. Don’t forget to regularly check the size of the backup files and allocate additional space as needed – having a “200GB free” policy for a database that has grown to 350GB will not be very helpful. If the space requirements change, be sure to change any associated alerts, too.
Using Performance Advisor
There are several queries included in this post that you can use for monitoring space, if you need to roll your own process. But if you happen to have SQL Sentry Performance Advisor in your environment, this gets a lot easier with Custom Conditions. There are several stock conditions included by default, but you can also create your own.
Within the SQL Sentry client, open the Navigator, right-click Shared Groups (Global), and select Add Custom Condition → SQL Sentry. Provide a name and description for the condition, then add a numeric comparison, and change the type to Repository Query. Enter the query:
SELECT MIN(FreeSpace*100.0/Size)
FROM SQLSentry.dbo.PerformanceAnalysisDeviceLogicalDisk;Change Equals to Is less than, and set an Explicit Value of 10. Finally, change the Default Evaluation Frequency to something less frequent than every 10 seconds. Once a day or once every 12 hours is probably a good value – you should not need to check free space more often than once a day, but you can check it as often as you like. The screen shot below shows the final configuration:
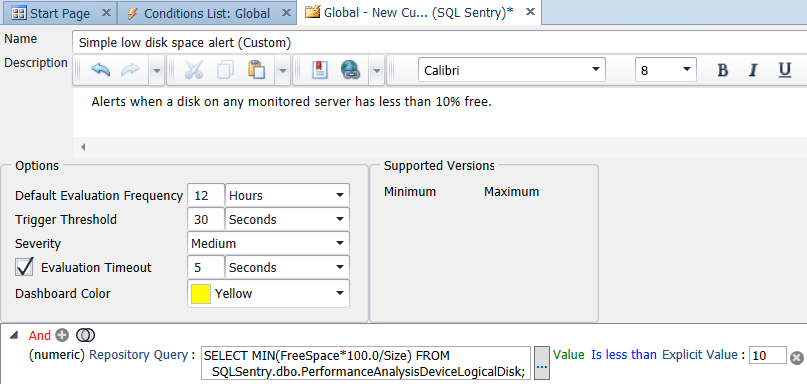
Once you click save for the condition, you will be asked if you want to assign actions for the custom condition. The option to Send to Alerting Channels is selected by default, but you may want to perform other tasks, such as Execute a Job – say, to copy old backups off to another location (if that’s the drive with low space).
As I mentioned previously, a default of 10% free space for all drives probably isn’t appropriate for every drive in your environment. You can customize the query for different instances and drives, for example:
SELECT Alert = MAX(CASE
WHEN Name = N'C:' AND [FreeSpace%] < 10 THEN 1
WHEN Name = N'S:' AND [FreeSpace%] < 25 THEN 1
WHEN Name = N'T:' AND [FreeSpace%] < 20 THEN 1
ELSE 0 END)
FROM
(
SELECT
d.Name,
d.FreeSpace * 100.0/d.Size AS [FreeSpace%]
FROM SQLSentry.dbo.PerformanceAnalysisDeviceLogicalDisk AS d
INNER JOIN SQLSentry.dbo.EventSourceConnection AS c
ON d.DeviceID = c.DeviceID
WHERE c.ObjectName = N'HANK\SQL2012' -- replace with your server/instance
) AS s;You can alter and expand this query as necessary for your environment, and then change the comparison in the condition accordingly (basically evaluating to true if the outcome is ever 1):
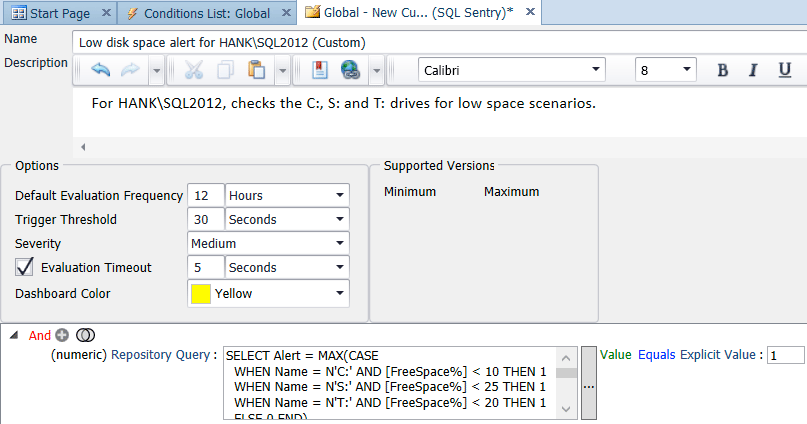
If you want to see Performance Advisor in action, feel free to download a trial.
Note that for both of these conditions, you will only be alerted once, even if multiple drives fall below your threshold. In complex environments you may want to lean toward a larger number of more specific conditions to provide more flexible and customized alerting, rather than fewer “catch-all” conditions.
Summary
There are many critical components in a SQL Server environment, and disk space is one that needs to be proactively monitored and maintained. With just a little bit of planning, this is simple to do, and it alleviates many unknowns and reactive problem solving. Whether you use your own scripts or a third-party tool, making sure there is plenty of free space for database files and backups is a problem that’s easily solvable, and well worth the effort.
3 thoughts on “Proactive SQL Server Health Checks, Part 1 : Disk Space”
Comments are closed.

Nice article, it works fine. here is another post for the same http://www.sqlservercentral.com/blogs/zoras-sql-tips/2016/01/15/four-ways-to-find-free-space-in-sql-server-database-/