


There is a regression bug in SQL Server 2012 and SQL Server 2014 where, if you rebuild an index online in parallel, and you also experience a fatal error such as a lock timeout, you could experience data loss or corruption. This should be a relatively rare scenario (Phil Brammer has a simple repro in Connect #795134), but data loss is data loss, and I am not prepared to gamble. The fix is described in KB #2969896 : FIX: Data loss in clustered index occurs when you run online build index in SQL Server 2012.
Not everyone needs to be concerned about this issue. If you are not running Enterprise (or an equivalent) Edition, you can't perform parallel or online rebuilds in the first place (and there are probably some folks on Enterprise not rebuilding or not rebuilding online). If you have instance-wide MAXDOP set to 1, they can't go parallel unless you override it at the statement level. But, if you are on 2012 or 2014, running an adequate edition, and your online rebuilds could go parallel, you are vulnerable to this problem.
As I alluded to above, this problem could manifest in SQL Server 2012 RTM, Service Pack 1, and even Service Pack 2, which was released on June 10. The bug was not fixed until long after the SP2 code was frozen, so SP2 does not include this fix or any of the fixes from SP1 CU #10 or #11. I blogged about this here. The RTM branch is officially out of support, so you will not be seeing a fix there. The issue can also occur in SQL Server 2014.
There are now cumulative updates available for SQL Server 2012 Service Pack 1 & 2 as well as SQL Server 2014. A quick summary of the options I recommend:
If your branch / @@VERSION is…
|
…you should… | ||||
|---|---|---|---|---|---|
|
|||||
|
|||||
| Do nothing; you already have the fix. | |||||
|
|||||
| Do nothing; you already have the fix. | |||||
| SQL Server 2014 RTM |
|
||||
| Do nothing; you already have the fix. | |||||
| * If you install the SP1 hotfix or Cumulative Update #11 and then install SP2, you will undo those changes, including this fix. | |||||
Solutions for the hotfix/CU averse
Since all affected branches (well, except 2012 RTM) have an on-demand hotfix and/or a cumulative update that addresses the issue, the easy answer is to just install the relevant update. However, you may be in a scenario where your company policy or testing cycles prevent you from deploying these updates quickly, or maybe ever. So what other options do you have?
- You can stop performing rebuilds until there is a new service pack available for your branch (maybe you can just stick with
REORGANIZEfor now). Unfortunately, if you are in a "service pack only" company, your options are very limited: you can fight harder to change that policy, or you can wait for SQL Server 2012 Service Pack 3 (which may be a long time, or may simply never come – see FAQ #21 here) or SQL Server 2014 Service Pack 1 (which we probably won't see before 2015 rolls around). - You can set the instance-wide
max degree of parallelismto 1, however this may have a negative effect on the rest of your workload – think about things like multi-threaded DBCC, parallel queries against or between partitioned tables, and other operations where you may want to reduce parallelism but not eliminate it altogether. Also, this setting won't affect an online rebuild with, say, an explicitMAXDOP = 8hard-coded into the command, as this will override thesp_configuresetting.
- You can add the
WITH (MAXDOP = 1)option manually to all of your rebuild commands. (Note: you don't have to do this for XML indexes, since they inherently run single-threaded, but I would just apply it to all rebuilds for consistency and to avoid any unnecessary conditional logic.)
- You can set your index maintenance jobs to run as a specific login, and then use Resource Governor to create a Workload Group that limits that login's
MAX_DOPto 1, regardless of what they are doing. I have an example of this in the 2008 white paper I wrote with Boris Baryshnikov, Using the Resource Governor, in the section entitled, "Limiting Parallelism for Intensive Background Jobs."
- If you are using Ola Hallengren's index maintenance solution, you can add the
@MaxDopparameter to your calls todbo.IndexOptimize:
EXEC dbo.IndexOptimize /* other parameters */ @MaxDop = 1; - If you are using SQL Sentry Fragmentation Manager, you can dictate the level of
MAXDOPto use under Settings – and you can do this enterprise-wide, per instance, per database, or even per individual index (in this case, you'd probably want to set this per instance, for all instances without a fix available):
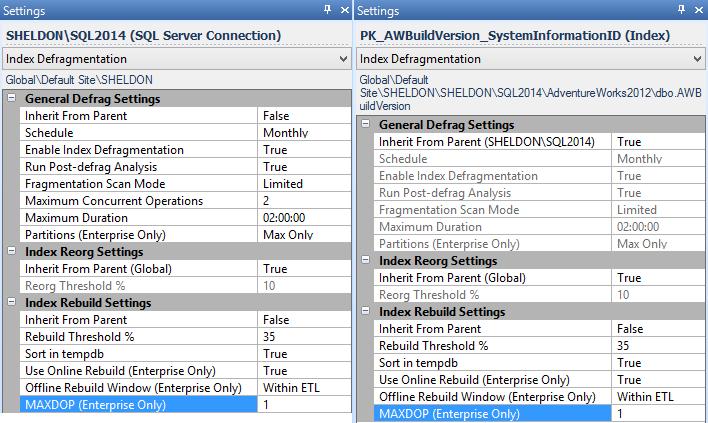
Fragmentation Manager settings for the instance (left) and an individual index (right). - If you're using Maintenance Plans for your index rebuilds, you're going to have to change them to use Execute T-SQL Statement Tasks, and write your
ALTER INDEX ... WITH (ONLINE = ON, MAXDOP = 1);commands manually (so may as well switch to an automated solution). See, the Index Rebuild Task does not have an exposed property forMAXDOP, even though it has been requested multiple times (most recently in 2012, by Alberto Morillo, and as far back as 2006, by Linchi Shea). And just look at all of these other useful properties they expose, likeAdvSortInTempdb,ObjectTypeSelection, andTaskAllowesDatbaseSelection[sic2!]:
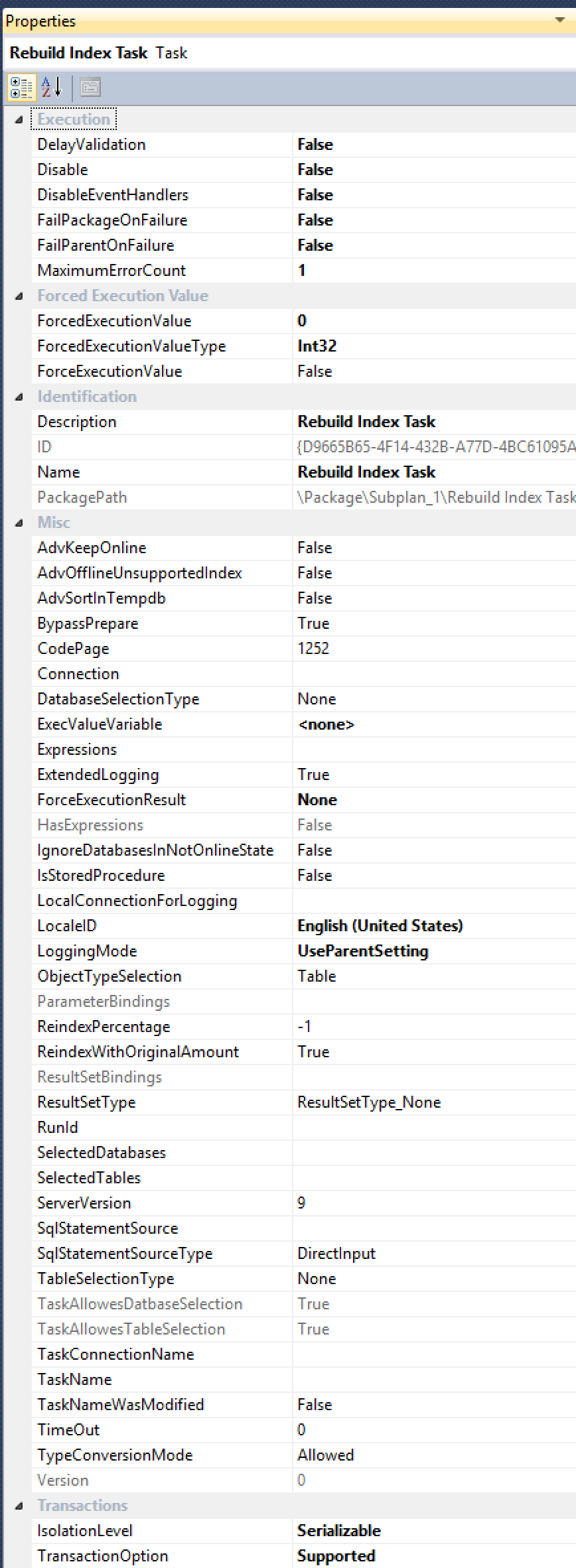
All those options, but still no cure for MAXDOP.



Is this fix in the CU10 (11.00.3431)?
Hi Alvaro, no, this fix is not in CU #10. It was important enough for Microsoft to release an out-of-band hotfix.
Hi,
what if i set MAXDOP instance wide to 1?
Yes, I suppose you could do that as well, but you should take into account what operations in your workload that will affect, aside from just online rebuilds that might go parallel. In other words, I think there are much more targeted methods you can use to reliably avoid this problem without dramatically impacting all of the rest of your workload which isn't vulnerable to this issue in the first place.
Sure, if the instance has MAXDOP 1 anyway, the instance is not vulnerable.
Well, that's not necessarily true – you could very easily have rebuild command
with (maxdop = 8), for example, and this would override the sp_configure setting.Aaron,
I would hope that if Microsoft can produce a hotfix for SP1 post CU10 that they could also create an equivalent hotfix for SP2 post RTM before CU1 appears next month.
Chris
I hope so too! For 2014 I think the interval is too short to justify an out-of-band hotfix, but who knows, I've seen stranger decisions…
Aaron,
Thanks a lot for sharing this info.
Are you aware of any other potential issue on SP2? Especially to those running Standard edition.
That's the only issue I know about – and really if you're on SP1 < 3437, SP2 without the hotfix makes you no *more* vulnerable to the issue, but applying the hotfix is better.
Chris, the post-SP2 COD hotfix has been released (see the same KB article and my update above).
The SP2 version now available build 5522.
Chris
But, as of today, it still says only SP1 in the "applies to" list. I'm just going to have to trust you Aaron. ;-) ;-)
Thanks!!
kt
Yep… two download options – one for SP1 and one for SP2. Thanks Aaron!
I am looking at the maintenance plan Rebuild Index task on my Microsoft SQL Server 2012 (SP1) – 11.0.3128.0 (X64) instance and see the option to "Keep Index online while reindexing".
If this is NOT selected, am I subject to this bug ?
Mike, if that is the only possible way for indexes to be rebuilt, you *might* be safe. Of course, anyone could go and check that box tomorrow, or run their own manual rebuilds, so I wouldn't assume that you are safe; I would rather apply 11.0.3449 if I were in your shoes.
It appears there is an issue with this fix. We have a cluster that has SQL 2012 Native replication where there are 21 different publications, each for a different database. All was working fine, but since applying the patch it will only allow one log reader agent at a time to run. It doesn’t matter which one, they all seem to work ok, but once one is running all the others throw an error like below:
2014-08-19 14:26:42.307 Status: 0, code: 1007, text: 'Another logreader agent for the subscription or subscriptions is running, or the server is working on a previous request by the same agent.'.
2014-08-19 14:26:42.307 Another logreader agent for the subscription or subscriptions is running, or the server is working on a previous request by the same agent.
2014-08-19 14:26:42.307 Status: 0, code: 22037, text: 'The last step did not log any message!'.
Alex, this has been reported by a few other users as well:
http://connect.microsoft.com/SQLServer/feedbackdetail/view/950118
And they have committed to a hotfix next week. In the meantime, potential workarounds are (a) removing the hotfix or (b) upgrading to Service Pack 2 + CU #1, where this isn't an issue. Just keep in mind that SP2 + CU #1 will be missing some of the fixes from SP1 CU #11.
I've updated our "latest 2012 builds" post to warn people about this issue as well. You were on 2012 SP1, correct?
https://blogs.sentryone.com/team-posts/latest-builds-sql-server-2012/