
Hekaton with a twist: In-memory TVPs – Part 3
In my previous post in this series, I demonstrated that not all query scenarios can benefit from In-Memory OLTP technologies. In fact, using Hekaton in certain use cases can actually have a detrimental effect on performance (click to enlarge):
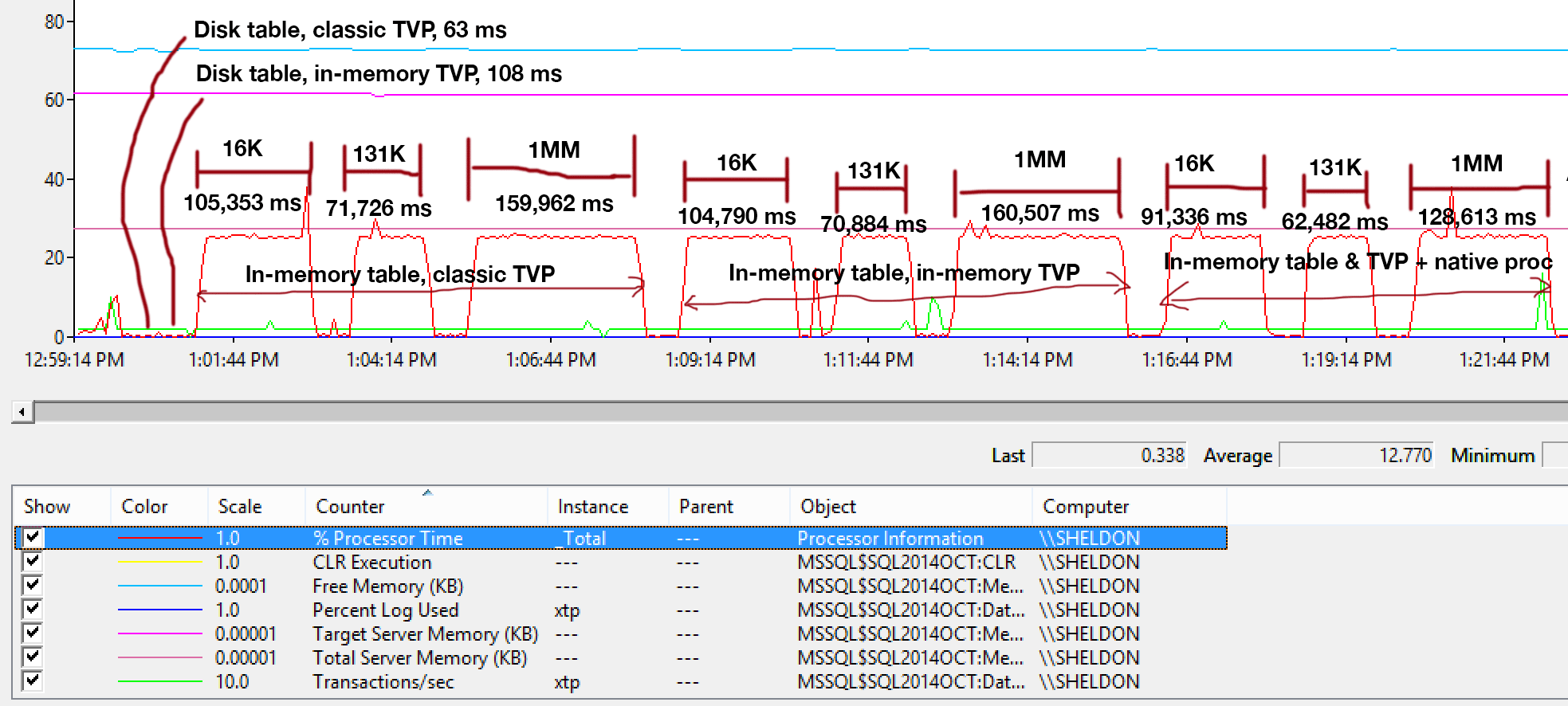
Performance monitor profile during stored procedure execution
However, I might have stacked the deck against Hekaton in that scenario, in two ways:
- The memory-optimized table type I created had a bucket count of 256, but I was passing in up to 2,000 values to compare. In a more recent blog post from the SQL Server team, they explained that over-sizing the bucket count is better than under-sizing it – something that I knew in general, but didn't realize also had significant effects on table variables:
Keep in mind that for a hash index the bucket_count should be about 1-2X the number of expected unique index keys. Over-sizing is usually better than under-sizing: if sometimes you insert only 2 values in the variables, but sometimes insert up to 1000 values, it’s usually better to specify
BUCKET_COUNT=1000.They don't explicitly discuss the actual reason for this, and I'm sure there are plenty of technical details we could delve into, but the prescriptive guidance seems to be to over-size.
- The primary key was a hash index on two columns, whereas the table-valued parameter was only attempting to match values in one of those columns. Quite simply, this meant that the hash index couldn't be used. Tony Rogerson explains this in a little more detail in a recent blog post:
The hash is generated across all the columns contained in the index, you must also specify all the columns in the hash index on your equality check expression otherwise the index cannot be used.
I didn't show it before, but notice that the plan against the memory-optimized table with the two-column hash index actually does a table scan rather than the index seek you might expect against the non-clustered hash index (since the leading column was
SalesOrderID):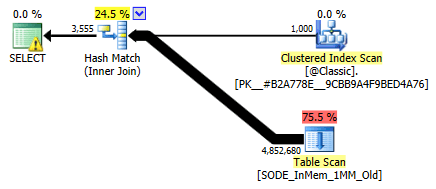
Query plan involving an in-memory table with a two-column hash indexTo be more specific, in a hash index, the leading column doesn't mean a hill of beans on its own; the hash is still matched across all columns, so it does not work like a traditional B-tree index at all (with a traditional index, a predicate involving only the leading column could still be very useful in eliminating rows).
What To Do?
Well, first, I created a secondary hash index on only the SalesOrderID column. An example of one such table, with a million buckets:
CREATE TABLE [dbo].[SODE_InMem_1MM]
(
[SalesOrderID] [int] NOT NULL,
[SalesOrderDetailID] [int] NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL,
[LineTotal] [numeric](38, 6) NOT NULL,
[rowguid] [uniqueidentifier] NOT NULL,
[ModifiedDate] [datetime] NOT NULL
PRIMARY KEY NONCLUSTERED HASH
(
[SalesOrderID],
[SalesOrderDetailID]
) WITH (BUCKET_COUNT = 1048576),
/* I added this secondary non-clustered hash index: */
INDEX x NONCLUSTERED HASH
(
[SalesOrderID]
) WITH (BUCKET_COUNT = 1048576)
/* I used the same bucket count to minimize testing permutations */
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);
Remember that our table types are set up this way:
CREATE TYPE dbo.ClassicTVP AS TABLE
(
Item INT PRIMARY KEY
);
CREATE TYPE dbo.InMemoryTVP AS TABLE
(
Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256)
)
WITH (MEMORY_OPTIMIZED = ON);
Once I populated the new tables with data, and created a new stored procedure to reference the new tables, the plan we get correctly shows an index seek against the single-column hash index:
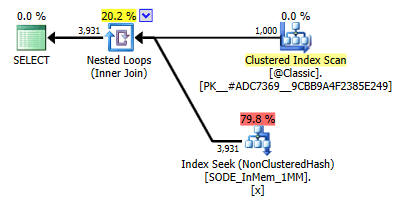
Improved plan using the single-column hash index
But what would that really mean for performance? I ran the same set of tests again – queries against this table with bucket counts of 16K, 131K, and 1MM; using both classic and in-memory TVPs with 100, 1,000 and 2,000 values; and in the in-memory TVP case, using both a traditional stored procedure and a natively compiled stored procedure. Here is how the performance went for 10,000 iterations per combination:
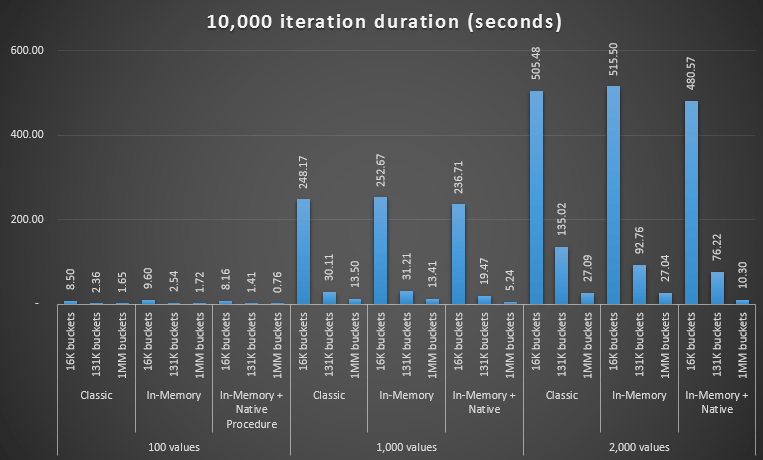
Performance profile for 10,000 iterations against a single-column hash index, using a 256-bucket TVP
You may think, hey, that performance profile does not look that great; on the contrary, it is much better than my previous test last month. It just demonstrates that the bucket count for the table can have a huge impact on SQL Server's ability to effectively use the hash index. In this case, using a bucket count of 16K clearly is not optimal for any of these cases, and it gets exponentially worse as the number of values in the TVP increases.
Now, remember, the bucket count of the TVP was 256. So what would happen if I increased that, as per Microsoft's guidance? I created a second table type with a more appropriate bucket size. Since I was testing 100, 1,000 and 2,000 values, I used the next power of 2 for the bucket count (2,048):
CREATE TYPE dbo.InMemoryTVP AS TABLE
(
Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 2048)
)
WITH (MEMORY_OPTIMIZED = ON);
I created supporting procedures for this, and ran the same battery of tests again. Here are the performance profiles side-by-side:
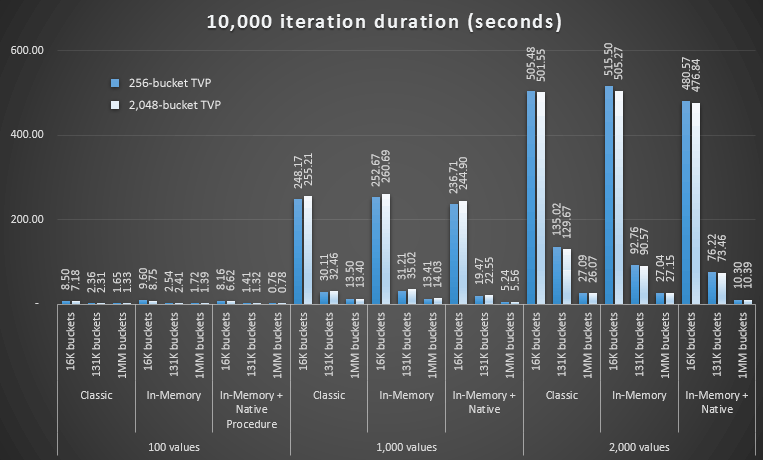
Performance profile comparison with 256- and 2,048-bucket TVPs
The change in bucket count for the table type did not have the impact I would have expected, given Microsoft's statement on sizing. It really didn't have much of a positive effect at all; in fact for some scenarios it was a little bit worse. But overall the performance profiles are, for all intents and purposes, the same.
What did have a huge effect, though, was creating the *right* hash index to support the query pattern. I was thankful that I was able to demonstrate that – in spite of my previous tests that indicated otherwise – an in-memory table and in-memory TVP could beat the old school way to accomplish the same thing. Let's just take the most extreme case from my previous example, when the table only had a two-column hash index:
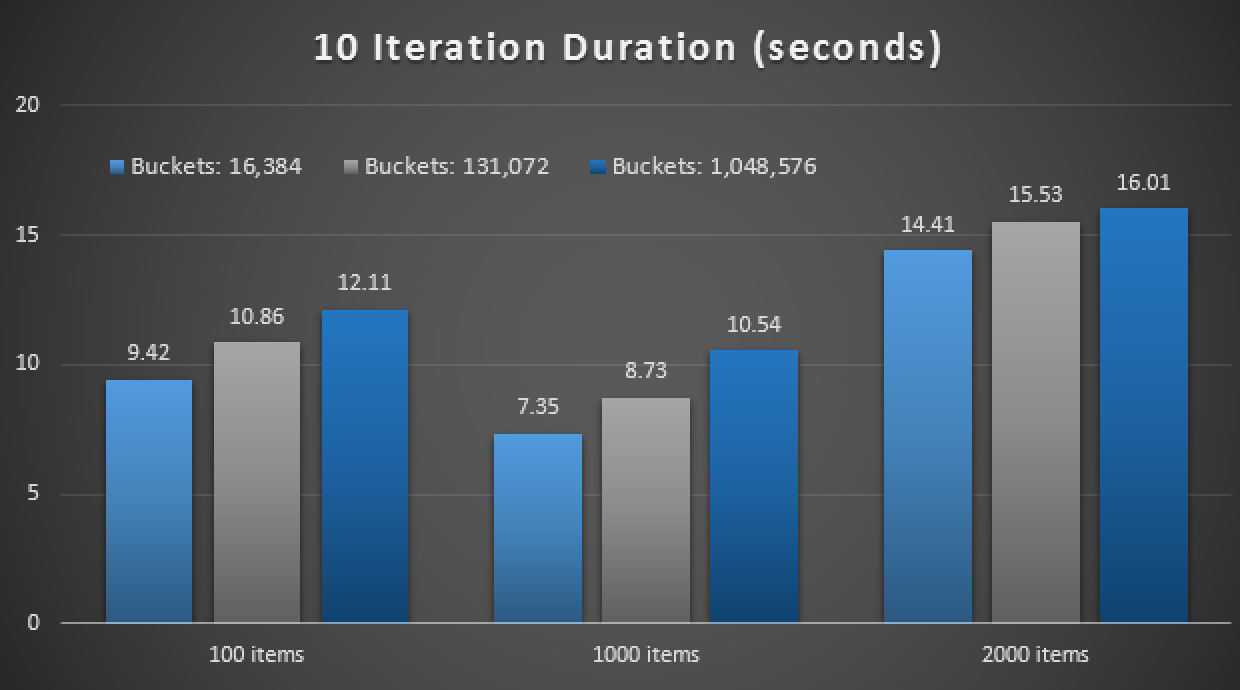
Performance profile for 10 iterations against a two-column hash index
The right-most bar shows the duration of just 10 iterations of the native stored procedure matching against an inappropriate hash index – query times ranging from 735 to 1,601 milliseconds. Now, however, with the right hash index in place, the same queries are executing in much smaller range – from 0.076 milliseconds to 51.55 milliseconds. If we leave out the worst case (16K bucket counts), the discrepancy is even more pronounced. In all cases, this is at least twice as efficient (at least in terms of duration) as either method, without a naively compiled stored procedure, against the same memory-optimized table; and hundreds of times better than any of the approaches against our old memory-optimized table with the sole, two-column hash index.
Conclusion
I hope I have demonstrated that much care must be taken when implementing memory-optimized tables of any type, and that in a lot of cases, using a memory-optimized TVP on its own may not yield the largest performance gain. You will want to consider using natively-compiled stored procedures to get the most bang for your buck, and to best scale, you will really want to pay attention to the bucket count for the hash indexes in your memory-optimized tables (but perhaps not so much attention to your memory-optimized table types).
For additional reading on In-Memory OLTP technology in general, you may want to check out these resources:
- The SQL Server Team Blog (Tag: Hekaton and Tag: In-Memory OLTP – aren't code names fun?)
- Bob Beauchemin's blog
- Klaus Aschenbrenner's blog
3 thoughts on “Hekaton with a twist: In-memory TVPs – Part 3”
Comments are closed.

The indexing structure on the TVP should almost not matter because it is only ever scanned and the row count is not even that big. No huge gains to be expected here. Seems plausible.
Nothing unexpected, this is now “none auto expanding” hash table have behaved since I did my degree 20 years ago. Maybe the problem is that Microsoft is assuming the SQL server DBAs have experience of hash tables and/or studied them at university.