
The Price of Not Purging
I’m in the process of de-cluttering my house (too late in the summer to try and pass it off as spring cleaning). You know, cleaning out closets, going through the kids’ toys, and organizing the basement. It’s a painful process. When we moved into our house 10 years ago we had SO much room. Now I feel like there’s stuff everywhere, and it makes it harder to find what I’m really looking for and it takes longer and longer to clean up and organize.
Does this sound like any database you manage?
Many clients that I’ve worked with deal with purging data as an afterthought. At the time of the implementation, everyone wants to save everything. “We never know when we might need it.” After a year or two someone realizes there’s a lot of extra stuff in the database, but now people are afraid to get rid of it. “We need to check with Legal to see if we can delete it.” But no one checks with Legal, or if someone does, Legal goes back to the business owners to ask what to keep, and then the project grinds to a halt. “We cannot come to a consensus about what can be deleted.” The project is forgotten, and then two or four years down the road, the database is suddenly a terabyte, difficult to manage, and people blame all performance issues on database size. You hear the words “partitioning” and “archive database” thrown around, and sometimes you just get to delete a bunch of data, which has its own issues.
Ideally you should decide on your purge strategy before implementation, or within the first six to twelve months of go-live. But since we’re past that stage, let’s look at what impact this extra data can have.
Test Methodology
To set the stage, I took a copy of the Credit database and restored it to my SQL Server 2012 instance. I dropped the three existing nonclustered indexes and added two of my own:
USE [master];
GO
RESTORE DATABASE [Credit]
FROM DISK = N'C:\SQLskills\SampleDatabases\Credit\CreditBackup100.bak'
WITH FILE = 1,
MOVE N'CreditData' TO N'D:\Databases\SQL2012\CreditData.mdf',
MOVE N'CreditLog' TO N'D:\Databases\SQL2012\CreditLog.ldf',
STATS = 5;
GO
ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditData', SIZE = 14680064KB , FILEGROWTH = 524288KB );
GO
ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditLog', SIZE = 2097152KB , FILEGROWTH = 524288KB );
GO
USE [Credit];
GO
DROP INDEX [dbo].[charge].[charge_category_link];
DROP INDEX [dbo].[charge].[charge_provider_link];
DROP INDEX [dbo].[charge].[charge_statement_link];
CREATE NONCLUSTERED INDEX [charge_chargedate] ON [dbo].[charge] ([charge_dt]);
CREATE NONCLUSTERED INDEX [charge_provider] ON [dbo].[charge] ([provider_no]);
I then increased the number of rows in the table to 14.4 million, by re-inserting the original set of rows multiple times, modifying the dates slightly:
INSERT INTO [dbo].[charge]
(
[member_no],
[provider_no],
[category_no],
[charge_dt],
[charge_amt],
[statement_no],
[charge_code]
)
SELECT
[member_no],
[provider_no],
[category_no],
[charge_dt] - 175,
[charge_amt],
[statement_no],
[charge_code]
FROM [dbo].[charge]
WHERE [charge_no] BETWEEN 1 AND 2000000;
GO 3
INSERT INTO [dbo].[charge]
(
[member_no],
[provider_no],
[category_no],
[charge_dt],
[charge_amt],
[statement_no],
[charge_code]
)
SELECT
[member_no],
[provider_no],
[category_no],
[charge_dt],
[charge_amt],
[statement_no],
[charge_code]
FROM [dbo].[charge]
WHERE [charge_no] BETWEEN 1 AND 2000000;
GO 2
INSERT INTO [dbo].[charge]
(
[member_no],
[provider_no],
[category_no],
[charge_dt],
[charge_amt],
[statement_no],
[charge_code]
)
SELECT
[member_no],
[provider_no],
[category_no],
[charge_dt] + 79,
[charge_amt],
[statement_no],
[charge_code]
FROM [dbo].[charge]
WHERE [charge_no] BETWEEN 1 AND 2000000;
GO 3
Finally, I set up a test harness to execute a series of statements against the database four times each. The statements are below:
ALTER INDEX ALL ON [dbo].[charge] REBUILD;
DBCC CHECKDB (Credit) WITH ALL_ERRORMSGS, NO_INFOMSGS;
BACKUP DATABASE [Credit]
TO DISK = N'D:\Backups\SQL2012\Credit.bak'
WITH NOFORMAT,
INIT,
NAME = N'Credit-Full Database Backup',
STATS = 10;
SELECT [charge_no], [member_no], [charge_dt], [charge_amt]
FROM [dbo].[charge]
WHERE [charge_no] = 841345;
DECLARE @StartDate DATETIME = '1999-07-01';
DECLARE @EndDate DATETIME = '1999-07-31';
SELECT [charge_dt], COUNT([charge_dt])
FROM [dbo].[charge]
WHERE [charge_dt] BETWEEN @StartDate AND @EndDate
GROUP BY [charge_dt];
SELECT [provider_no], COUNT([provider_no])
FROM [dbo].[charge]
WHERE [provider_no] = 475
GROUP BY [provider_no];
SELECT [provider_no], COUNT([provider_no])
FROM [dbo].[charge]
WHERE [provider_no] = 140
GROUP BY [provider_no];
Before each statement I executed
DBCC DROPCLEANBUFFERS;
GO
to clear the buffer pool. Obviously this is not something to execute against a production environment. I did it here to provide a consistent starting point for each test.
After each execution, I increased the size of the dbo.charge table by inserting the 14.4 million rows I started with, but I increased the charge_dt by one year for each execution. For example:
INSERT INTO [dbo].[charge]
(
[member_no],
[provider_no],
[category_no],
[charge_dt],
[charge_amt],
[statement_no],
[charge_code]
)
SELECT
[member_no],
[provider_no],
[category_no],
[charge_dt] + 365,
[charge_amt],
[statement_no],
[charge_code]
FROM [dbo].[charge]
WHERE [charge_no] BETWEEN 1 AND 14800000;
GO
After the addition of 14.4 million rows, I re-ran the test harness. I repeated this six times, essentially adding six “years” of data. The dbo.charge table started with data from 1999, and after the repeated inserts contained data through 2005.
Results
The results from the executions can be seen here:
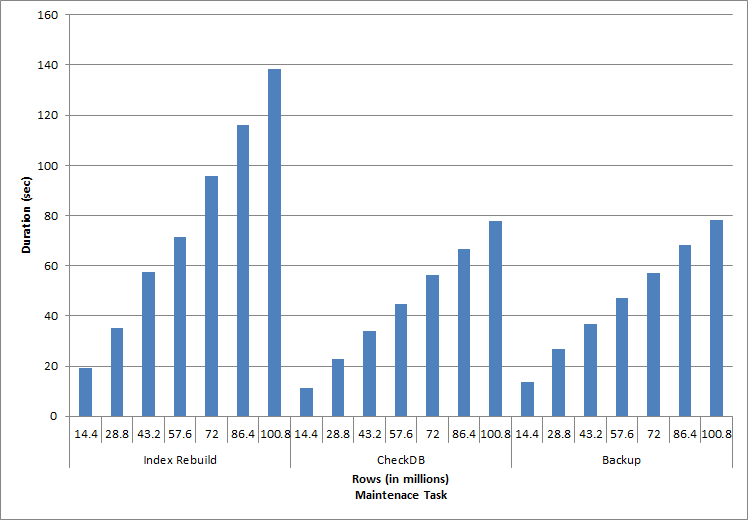
Duration for Maintenance Tasks
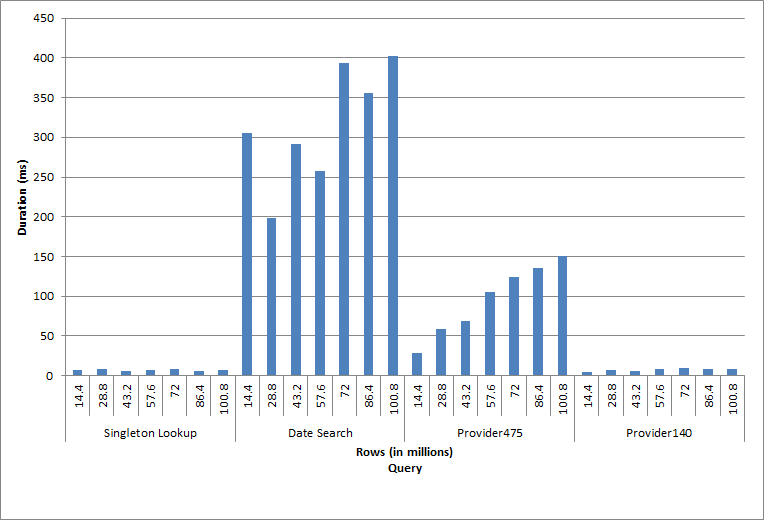
Duration for Queries
The individual statements executed reflect typical database activity. Index rebuilds, integrity checks and backups are part of regular database maintenance. The queries against the charge table represent a singleton lookup as well as three variations of range scans specific to the data in the table.
Index Rebuilds, CHECKDB, and Backups
As expected for the maintenance tasks, duration and IO values increased as more rows were added to the database. The database size increased by a factor of 10, and while the durations did not increase at the same rate, a consistent increase was seen. Each maintenance task initially took less than 20 seconds to complete, but as more rows were added, duration for the tasks increased to almost 1 minute and 20 seconds for 100 million rows (and to over 2 minutes for the index rebuild). This reflects the additional time SQL Server required to complete the task due to additional data.
Singleton Lookup
The query against dbo.charge for a specific charge_no always produced one row – and would have produced one row regardless of the value used, as charge_no is a unique identity. There is minimal variation for this lookup. As rows are continually added to the table, the index may increase in depth by one or two levels (more as the table gets wider), therefore adding a couple IOs, but this is a singleton lookup with very few IOs.
Range Scans
The query for a date range (charge_dt) was modified after each insert to search the most recent year’s data for July (e.g. '2005-07-01' to '2005-07-01' for the last set of tests), but returned just over 1.2 million rows each time. In a real-world scenario, we wouldn’t expect the same number of rows to be returned for the same month, year over year, nor would we expect the same number of rows to be returned for every month in a year. But row counts could stay within the same range between months, with slight increases over time. There exist fluctuations in duration for this query, but a review of the IO data captured from sys.dm_io_virtual_file_stats shows consistency in the number of reads.
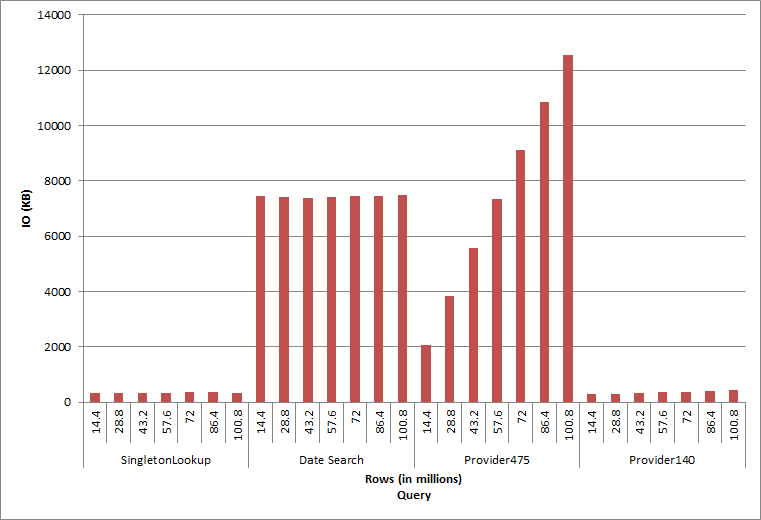
Query IO
The final two queries, for two different provider_no values, show the true effect of keeping data. In the initial dbo.charge table, provider_no 475 had over 126,000 rows and provider_no 140 had over 1700 rows. For each 14.4 million rows that were added, approximately the same number of rows for each provider_no was added. In a production environment, this type of data distribution is not uncommon, and queries for this data may perform well in the first years of the solution, but may degrade over time as more rows are added. Query duration increases by a factor of five (from 31 ms to 153 ms) between the initial and final execution for provider_no 475. While this impact may not seem significant, note the parallel increase in IO (above). If this were a query that executed with high frequency, and/or there were similar queries that executed with regular frequency, the additional load can add up and affect overall resource usage. Further, consider the impact when you’re working with tables that have billions of rows, and are used in queries with complex joins, and the impact on your regular – and extremely critical – maintenance tasks. Finally, take into account recoverability time. Your disaster recovery plan should be based on restore times, and as database size grows, the database will take longer to restore in its entirety. If you’re not regularly testing and timing your restores, recovering from a disaster could take longer than you thought.
Summary
The examples shown here are simple illustrations of what can happen when a data archiving strategy is not determined during database implementation, and there are many other scenarios to explore and test. Old data which is rarely, if ever, accessed impacts more than just space on disk. It can affect query performance and duration of maintenance tasks. As a DBA managing multiple databases on an instance, one database that holds historical data can affect the performance and maintenance tasks of other databases. Further, if reports execute against historical data, this can wreak havoc on already-busy OLTP environment.
From the beginning, it’s critical that the lifespan of data in a database is determined, and a plan of action put in place. For some solutions, it is required to keep all data forever. In this case, employ strategies to keep database size manageable, for example: archive the data to a separate table or separate database on a regular basis. In the event that data does not need to be stored for years and years, implement a purging strategy that removes data on a regular basis. In this manner, you can throw out the toys that are no longer played with, clothes that no longer fit, and random junk that you just don’t use every three months…rather than once every 10 years.
7 thoughts on “The Price of Not Purging”
Comments are closed.

Great stuff. In cases that data must be maintained indefinitely without purge, lifecycle should still be managed to the extent possible with partitioning and possibly data storage tiering. SQL Server 2014 makes that a little bit easier by allowing stats maintenance per partition. Once all maintenance tasks can be handled in SQL Server at the partition level, a combination of a strong partitioning strategy and a reasonable purging strategy should ease the burden on maintenance activities.
Because Adam Machanic is concerned about how the optimizer will/not handle partition level statistics (and now he's got me worried :)) I'll mention that your query test is particularly relevant, and could point out a benefit that purging could provide which may not be delivered by a partitioning strategy.
Thanks for the comment and for reading! Partitioning and data storage tiering are great ideas – but just like with purging, I think so many people don't consider them during design and implementation for whatever reason. (And in the case of partitioning, maybe they're not on Enterprise Edition or aren't familiar with partitioned views.) Perhaps they don't realize how large the table will be, maybe they know it will enormous but don't think they have time to implement something. At any rate, I've worked with many customers that have one or two enormous tables consuming significant space in their database. Some have strategies in place, and others…we're working on it :)
Hi Erin,
nice post, thanks!
Are you aware that for customers where either do not have the time to wait for processing and handling millions of rows / or do not reach consensus of what to delete, we now have SQL Server 2012 PDW around!
PDW distributes the data across 2 to many servers where this effect becomes neglectable for the time being .. (==say till you're customer hits 100's of TB's of data…) also it uses the new updateable clustered columnstore for even faster / in-mem processing.
(for more info see also: http://microsoft.com/pdw)
Brgds,
Henk (SQL PDW)
Hi Henk-
Thank you for comment and for the additional information! I am familiar with PDW and it is an option. In this example I did assume a box SQL Server installation – I didn't go to into actual archiving strategies or options as my focus was more "what happens when you don't purge, but could have?" In a PDW solution you probably have seven years worth of data because you want it! Great reminder of one of the many options that exist – thanks so much,
Erin
Great article Erin – I'm right with you. I am a bit of a no clutter freak in and out of work. I love to run this query across any new servers I'm managing. It's incredible how many of those "temp" table aren't that temporary after all.
EXEC dbo.SP_MSFOREACHDB 'USE ? IF DB_NAME() NOT IN (''DISTRIBUTION'',''MASTER'',''MODEL'',''MSDB'',''TEMPDB'') SELECT DB_NAME(), TABLE_NAME FROM [?].INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME LIKE ''%[0-9][0-9]%'' OR TABLE_NAME LIKE ''%[_][0-9]%'' OR TABLE_NAME LIKE ''%temp%'' OR TABLE_NAME LIKE ''%tmp%'''These objects may not directly affect performance directly as your paper superbly shows, but it can soon become an issue in terms of storage, plus increased backup times incurred. You can bet your bottom dollar that any capacity planning doesn't cater for this and any future decision to drop these objects always carries a small risk.
Paul, please be careful with
sp_MSForEachDB. It is undocumented and unsupported, and for good reason: it often skips databases. I've written about his here:http://www.mssqltips.com/sqlservertip/2201/making-a-more-reliable-and-flexible-spmsforeachdb/
https://sqlblog.org/blogs/aaron_bertrand/archive/2010/02/08/bad-habits-to-kick-relying-on-undocumented-behavior.aspx
https://sqlblog.org/blogs/aaron_bertrand/archive/2010/12/29/a-more-reliable-and-more-flexible-sp-msforeachdb.aspx
And Microsoft acknowledges it has issues but insists that they will not be fixed (or documented):
https://connect.microsoft.com/SQLServer/feedback/details/264677/sp-msforeachdb-provide-supported-documented-version
https://connect.microsoft.com/SQLServer/feedback/details/752629/disable-sp-msforeachdb-by-default-or-fix-it
Paul-
Your point about those "extra" tables is a good one, though I might add 'back_%' and 'bak_%' to your query – or whatever naming convention you most often see for backup tables. When I worked for a software vendor, we often made backups of data before we made modifications, and of course those weren't always cleaned up immediately :) It would also be worth pulling create_date (e.g. via sys.objects) in your query as well…just a thought. Thanks for the comment – it's a very valid example of another way a database become very large unnecessarily!
Erin