

When I was in Chicago a few weeks ago for one of our Immersion Events, an attendee had a statistics question. I won't go into all the details around the issue, but the attendee mentioned that stats were updated using sp_updatestats. This is a method to update statistics that I've never recommended; I have always recommended a combination of index rebuilds and UPDATE STATISTICS to keep statistics up to date. If you’re not familiar with sp_updatestats, it’s a command that is run for the entire database to update statistics. But as Kimberly pointed out to the attendee, sp_updatestats will update a statistic as long as it has had one row modified. Whoa. I immediately opened up Books Online, and for sp_updatestats you'll see this:
Now, I admit, I made an assumption on what "…require updating based on the rowmodctr information in the sys.sysindexes catalog view…" meant. I assumed that the update decision would follow the same logic that the Auto Update Statistics option follows, which is:
- The table size has gone from 0 to >0 rows (test 1).
- The number of rows in the table when the statistics were gathered was 500 or less, and the colmodctr of the leading column of the statistics object has changed by more than 500 since then (test 2).
- The table had more than 500 rows when the statistics were gathered, and the colmodctr of the leading column of the statistics object has changed by more than 500 + 20% of the number of rows in the table when the statistics were gathered (test 3).
This logic is not followed for sp_updatestats. In fact, the logic is so incredibly simple, it's scary: If one row is modified, the statistic is updated. One row. ONE ROW. What’s my concern? I’m worried about the overhead of updating statistics for a bunch of statistics that don't truly need to be updated. Let's take a closer look at sp_updatestats.
We'll start off with a fresh copy of the AdventureWorks2012 database which you can download from Codeplex. I’m going to first update rows in a three different tables:
USE [AdventureWorks2012];
GO
SET NOCOUNT ON;
GO
UPDATE [Production].[Product]
SET [Name] = 'Bike Chain'
WHERE [ProductID] = 952;
UPDATE [Person].[Person]
SET [LastName] = 'Cameron'
WHERE [LastName] = 'Diaz';
GO
INSERT INTO Sales.SalesReason
(Name, ReasonType, ModifiedDate)
VALUES('Stats', 'Test', GETDATE());
GO 10000
We modified one row in Production.Product, 211 rows in Person.Person, and we added 10,000 rows to Sales.SalesReason. If the sp_updatestats procedure followed the same logic for updates as the Auto Update Statistics option, then only Sales.SalesReason would update because it had 10 rows to start (whereas the 211 rows updated in Person.Person represent about one percent of the table). However, if we dig into sp_updatestats, we can see that the logic used is different. Note that I’m only extracting the statements from within sp_updatestats that are used to determine what statistics get updated.
A cursor iterates through all user-defined tables and internal tables in the database:
declare ms_crs_tnames cursor local fast_forward read_only for
select name, object_id, schema_id, type from sys.objects o
where o.type = 'U' or o.type = 'IT'
open ms_crs_tnames
fetch next from ms_crs_tnames into @table_name, @table_id, @sch_id, @table_type
Another cursor loops through the statistics for each table, and excludes heaps and hypothetical indexes and statistics. Note that sys.sysindexes is used in sp_helpstats. Sysindexes is a SQL Server 2000 system table and is scheduled to be removed in a future version of SQL Server. This is interesting, as the other method to determine rows updated is the sys.dm_db_stats_properties DMF, which is only available in SQL 2008 R2 SP2 and SQL 2012 SP1.
set @index_names = cursor local fast_forward read_only for
select name, indid, rowmodctr
from sys.sysindexes
where id = @table_id
and indid > 0
and indexproperty(id, name, 'ishypothetical') = 0
order by indid
After a bit of preparation and additional logic, we get to an IF statement which reveals that sp_updatestats filters out statistics that haven’t had any rows updated… confirming that even if only one row has been modified, the statistic will be updated. There’s also a check for @is_ver_current, which is determined by a built-in, internal function.
if ((@ind_rowmodctr <> 0) or ((@is_ver_current is not null) and (@is_ver_current = 0)))
A couple more checks related to sampling and compatibility level, and then the UPDATE statement executes for the statistic. Before we actually run sp_updatestats, we can query sys.sysindexes to see what statistics will update:
SELECT [o].[name], [si].[indid], [si].[name], [si].[rowmodctr], [si].[rowcnt], [o].[type]
FROM [sys].[objects] [o]
JOIN [sys].[sysindexes] [si] ON [o].[object_id] = [si].[id]
WHERE ([o].[type] = 'U' OR [o].[type] = 'IT')
AND [si].[indid] > 0
AND [si].[rowmodctr] <> 0
ORDER BY [o].[type] DESC, [o].[name];
In addition to the three tables that we modified, there’s another statistic for a user table (dbo.DatabaseLog) and three internal statistics that will be updated:
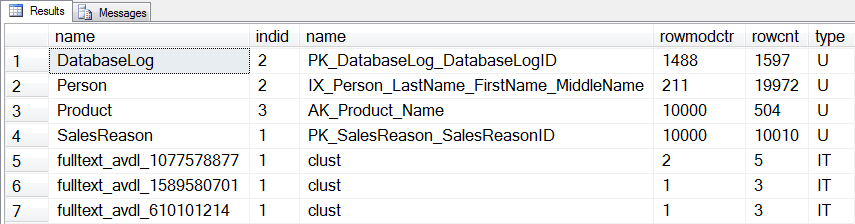
Statistics that will be updated
If we run sp_updatestats for the AdventureWorks database, the output lists every table and the statistic(s) updated. The output below is modified to only show updated statistics:
Updating [sys].[fulltext_avdl_1589580701]
[clust] has been updated…
1 index(es)/statistic(s) have been updated, 0 did not require update.
…
Updating [dbo].[DatabaseLog]
[PK_DatabaseLog_DatabaseLogID] has been updated…
1 index(es)/statistic(s) have been updated, 0 did not require update.
…
Updating [sys].[fulltext_avdl_1077578877]
[clust] has been updated…
1 index(es)/statistic(s) have been updated, 0 did not require update.
…
Updating [Person].[Person]
[PK_Person_BusinessEntityID], update is not necessary…
[IX_Person_LastName_FirstName_MiddleName] has been updated…
[AK_Person_rowguid], update is not necessary…
1 index(es)/statistic(s) have been updated, 2 did not require update.
…
Updating [Sales].[SalesReason]
[PK_SalesReason_SalesReasonID] has been updated…
1 index(es)/statistic(s) have been updated, 0 did not require update.
…
Updating [Production].[Product]
[PK_Product_ProductID], update is not necessary…
[AK_Product_ProductNumber], update is not necessary…
[AK_Product_Name] has been updated…
[AK_Product_rowguid], update is not necessary…
[_WA_Sys_00000013_75A278F5], update is not necessary…
[_WA_Sys_00000014_75A278F5], update is not necessary…
[_WA_Sys_0000000D_75A278F5], update is not necessary…
[_WA_Sys_0000000C_75A278F5], update is not necessary…
1 index(es)/statistic(s) have been updated, 7 did not require update.
…
Statistics for all tables have been updated.
The last line of the output is a bit misleading – statistics for all tables haven’t been updated, only the statistics that have had one row or more modified have been updated. And again, the drawback of that is that maybe resources were used that didn’t need to be. If a statistic only has one row modified, should it be updated? No. If it has 10,000 rows updated, should it be updated? Well, that depends. If the table only has 5,000 rows, then absolutely; if the table has 1 million rows, then no, as only one percent of the table has been modified.
The take-away here is that if you’re using sp_updatestats to update your statistics, you are most likely wasting resources, including CPU, I/O, and tempdb. Further, it takes time to update each statistic, and if you have a tight maintenance window you probably have other maintenance tasks that can execute in that time, instead of unnecessary updates. Finally, you’re probably not providing any performance benefits by updating statistics when so few rows have changed. The distribution change is likely insignificant if only a small percentage of rows have been modified, so the histogram and density values don’t end up changing that much. In addition, remember that updating statistics invalidates query plans that use those statistics. When those queries execute, plans be re-generated, and the plan will probably be exactly the same as it was before, because there was no significant change in the histogram. There’s a cost to re-compiling query plans – it’s not always easy to measure, but it shouldn’t be ignored.
A better method to manage statistics – because you do need to manage statistics – is to implement a scheduled job that updates based on the percentages of rows that have been modified. You can use the aforementioned query that interrogates sys.sysindexes, or you can use the query below that takes advantage of the new DMF added in SQL Server 2008 R2 SP2 and SQL Server 2012 SP1:
SELECT [sch].[name] + '.' + [so].[name] AS [TableName] ,
[ss].[name] AS [Statistic],
[sp].[last_updated] AS [StatsLastUpdated] ,
[sp].[rows] AS [RowsInTable] ,
[sp].[rows_sampled] AS [RowsSampled] ,
[sp].[modification_counter] AS [RowModifications]
FROM [sys].[stats] [ss]
JOIN [sys].[objects] [so] ON [ss].[object_id] = [so].[object_id]
JOIN [sys].[schemas] [sch] ON [so].[schema_id] = [sch].[schema_id]
OUTER APPLY [sys].[dm_db_stats_properties]([so].[object_id],
[ss].[stats_id]) sp
WHERE [so].[type] = 'U'
AND [sp].[modification_counter] > 0
ORDER BY [sp].[last_updated] DESC;
Realize that different tables may have different thresholds and you will need to tweak the query above for your databases. For some tables, waiting until 15% or 20% of the rows have been modified may be ok. But for others, you may need to update at 10% or even 5%, depending on the actual values and their skew. There is no silver bullet. As much as we love absolutes, they rarely exist in SQL Server and statistics is no exception. You still want to leave Auto Update Statistics enabled – it’s a safety that will kick in if you miss something, just like Auto Growth for your database files. But your best bet is to know your data, and implement a methodology that allows you to update statistics based on the percentage of rows changed.



Thanks Erin for sharing great info on sp_updatestats.
Cheers
Neeraj Mittal
Hi Erin,
Thank you for the very useful info; I will adopt your last query above in my maintenance routines, going forward.
One question: does it have to be an OUTER APPLY on the dm_db_stats_properties DMF or would a CROSS APPLY suffice?
The DMF should return results for all stats objects, so there is no risk of any rows not being returned with a CROSS APPLY.
Thanks again!
Marios
Fantastic reading, Erin. Great article!
-Kev
Great article, Erin.
However I get this error when I run the script on some databases.
"Incorrect syntax near 'so'"
Any ideas.
Cheers
Roy
Marios-
You should be able to use CROSS APPLY – in my quick tests it returned the same results. I might have used OUTER APPLY just out of habit :)
Thanks for reading!
Erin
Roy-
I need a bit more information – what do those databases that give the error have in common? Is it a different version of SQL Server? A different compatibility level? Remember that sys.dm_db_stats_properties is only supported with SQL 2008R2 and SQL 2012SP1.
Erin
Roy, almost certainly they are in an earlier compatibility mode, so you won't be able to use
OUTER APPLYthat way, even in cases where the function exists.Thanks Erin and Aaron, that's right on the mark! We are on SQL2008R2 but a few of the legacy and 3rd party databases are in mode = 80. Having now tested on our development server there are issues when incrementing the compatibility mode, so we are taking the appropriate steps with the vendors and developers.
SELECT name, compatibility_level from sys.databases reveals the culprits!
Roy
Hi Erin,
Great article!!!, but I still have a question regarding sp_updatestats. If I just issue a exec sp_updatestats against the database, it will be like a update statistics with fullscan? I'm concerned about the sample used when we run this procedure.
Thanks,
Marcos
SQL Server MVP
Hi Marcos-
If you issue sp_updatestats against a database, it will update statistics with the default sample, unless you specify RESAMPLE. If you specify RESAMPLE, then stats are updated with the most recent sample rate (which could have been a full scan, but maybe not). So, do not expect that sp_updatestats will update statistics with a fullscan. Hope that helps,
Erin
Interesting, I haven't thought about that. Thank you very much for writing it up. Another Microsoft provided tool out-of-box but suggest not use.
–here you go. Hard-coded 0.10 as 10%.
–comment out IF to run on all DBs.
–if each DB needs different percentage, then we need to create a table to store that lookup value.
sp_MSforeachdb @command1='
USE [?];
IF ("?" IN ("WSS_Content"))
BEGIN
–EXEC sp_createstats;
DECLARE @tbls TABLE (rowId INT IDENTITY(1,1), tblschema NVARCHAR(128), tblname NVARCHAR(128));
DECLARE @stmt NVARCHAR(2000), @rowId INT, @maxRowId INT, @tblschema NVARCHAR(128), @tblname NVARCHAR(128);
INSERT INTO @tbls (tblschema, tblname)
SELECT [sch].[name], [so].[name] AS [TableName]
FROM [sys].[stats] [ss]
JOIN [sys].[objects] [so] ON [ss].[object_id] = [so].[object_id]
JOIN [sys].[schemas] [sch] ON [so].[schema_id] = [sch].[schema_id]
OUTER APPLY [sys].[dm_db_stats_properties]([so].[object_id], [ss].[stats_id]) sp
WHERE [so].[type] = "U"
AND [sp].[modification_counter] > 0 AND ss.user_created = 0 AND [sp].[modification_counter]/[sp].[rows] > 0.10
ORDER BY [sp].[last_updated] DESC;
SELECT @rowId = MIN(rowId), @maxRowId = MAX(rowId) FROM @tbls;
WHILE @rowId '2014-07-07 00:00:00.000';
Hi, Erin, I am going to link to this blog post. Grant has one blog too, but he is kind of not suggesting this, not suggesting that ….
sp_MSforeachdb @command1='
USE [?];
IF ("?" IN ("WSS_Content"))
BEGIN
–EXEC sp_createstats;
DECLARE @tbls TABLE (rowId INT IDENTITY(1,1), tblschema NVARCHAR(128), tblname NVARCHAR(128));
DECLARE @stmt NVARCHAR(2000), @rowId INT, @maxRowId INT, @tblschema NVARCHAR(128), @tblname NVARCHAR(128);
INSERT INTO @tbls (tblschema, tblname)
SELECT [sch].[name], [so].[name] AS [TableName]
FROM [sys].[stats] [ss]
JOIN [sys].[objects] [so] ON [ss].[object_id] = [so].[object_id]
JOIN [sys].[schemas] [sch] ON [so].[schema_id] = [sch].[schema_id]
OUTER APPLY [sys].[dm_db_stats_properties]([so].[object_id], [ss].[stats_id]) sp
WHERE [so].[type] = "U"
AND [sp].[modification_counter] > 0 AND ss.user_created = 0 AND [sp].[modification_counter]/[sp].[rows] > 0.10
ORDER BY [sp].[last_updated] DESC;
SELECT @rowId = MIN(rowId), @maxRowId = MAX(rowId) FROM @tbls;
WHILE @rowId <= @maxRowId
BEGIN
SELECT @tblschema = tblschema, @tblname = tblname FROM @tbls WHERE rowId = @rowId;
SET @stmt = "UPDATE STATISTICS " + "[" + @tblschema + "].[" + @tblname + "];";
PRINT "?: " + @stmt;
EXECUTE (@stmt);
SET @rowId = @rowId + 1;
END
END
';
kind of funny who wrote this line at Microsoft:
….((@is_ver_current is not null) and (@is_ver_current = 0))
must be a VB programmer. lol.
Great post.
I wonder what the reasoning was behind using different alogs for the stats update.
Hi Mike-
Not sure what you mean – can you rephrase or clarify your question?
Thanks,
Erin
Different catalog views, maybe?
Something that has always bugged me about algorithms for manually updating stats (although it's more an issue with the system objects that hold this info) is that the modification counters just record then number of times rows change, not the actual number of rows that change.
So, for example, if I have a 1 million row table and I update 1 row in that table 10 million times (assuming, for simplicity's sake, there's a single column index that's involved, and therefore a single column stat for it), then my understanding is that rowmodctr (or colmodctr) in sys.sysindexes, or modification_counter in sys.dm_db_stats_properties(), will be 10,000,000, even though only 1 row has changed. In this example, I wouldn't want to update stats on my entire 1 million row table, because only a single row changed (it just happens to change a lot) so the data distribution & cardinality estimates in the related index/stat are still fine.
How can you determine the actual percentage of rows that have changed in an index (or, more importantly, stat)? It must be possible somehow if the auto update stats algorithm has logic based on percentage of rows changed.
Cheers,
Mike
i want to know after the Rebuil index it's recommended the Update Statistique.
Have a nice WE
because Rebuild = reor + update statistique
Hi-
Remember that a rebuild (which is not the same as a reorganize, it's a different operation) will update statistics with a fullscan, so if you have any indexes that are NOT rebuilt as part of your job (e.g. because you're only rebuilding those that are fragmented), then you would need a separate step to update out-of-date statistics for those indexes and column level stats that need it.
Hope that helps.
Just to clarify, a rebuild is not the equivalent of a rebuild and then an update of statistics. A rebuild and a reorganize are two separate operations which do different things. A by-product of a rebuild is that statistics are updated with a full scan. Stats are not updated when you run a reorg.
Hi Mike-
This is an interesting question. You're correct in that SQL Server just tracks the true number of modifications, not the number of rows that were modified. It is possible to modify the same row over and over and that will trigger an update. As far as I know, there's no way around that. There's nothing (to my knowledge) that tracks the distinct number of rows modified. I am sure you could figure out a way to track it yourself, but I don't know if that's worth the trouble.
Erin
Good article. Just a note on a mistake, you said we will query sys.indexes, but you queried sysindexes instead.
Hi-
Can you please include the entire sentence where sys.indexes is referenced? I did a FIND on the page and couldn't locate it. Thank you!
Erin
Hi Erin,
I have crores of rows in my table and weekly maintenance plan of re-index and update statistics is failing by last 3 weeks.
All time, I am using reindex by Query and statistic update by "sp_updatestats". But unfortunately Non-clustered index is not behaving well some time and i am getting "PAGELATCH_UP" wait type.
So is it sp_updatestats issue?
Hi Jerry-
I'm not sure I understand your question. When you state that you "reindex", I understand that to be a rebuild of an index. If you rebuild an index there is no reason to run sp_updatestats.
Further, I don't understand what "non-clustered index is not behaving well" means, or how that relates to PAGELATCH_UP waits and sp_updatestats. Are you seeing the PAGELATCH waits while stats are updating or at other times? And have you confirmed the PAGELATCH waits are in the user database and not tempdb?
Erin