
Sample Size and the Duration of UPDATE STATISTICS: Does It Matter?
For any new database created in SQL Server, the default value for the Auto Update Statistics option is enabled. I suspect that most DBAs leave the option enabled, as it allows the optimizer to automatically update statistics when they are invalidated, and it’s generally recommend to leave it enabled. Statistics are also updated when indexes are rebuilt, and while it’s not uncommon for statistics to be well managed via the auto update statistics option and through index rebuilds, from time to time a DBA may find it necessary to set up a regular job to update a statistic, or set of statistics.
Custom management of statistics often involves the UPDATE STATISTICS command, which seems fairly benign. It can be run for all statistics for a table or indexed view, or for a specific statistic. The default sample can be used, a specific sample rate or number of rows to sample can be specified, or you can use the same sample value that was used previously. If statistics are updated for a table or indexed view, you can choose to update all statistics, only index statistics, or only column statistics. And finally, you can disable the auto update statistics option for a statistic.
For most DBAs, the biggest consideration may be when to run the UPDATE STATISTICS statement. But DBAs also decide, consciously or not, the sample size for the update. The sample size selected can affect the performance of the actual update, as well as the performance of queries.
Understanding the Effects of Sample Size
The default sample size for the UPDATE STATISTICS comes from a non-linear algorithm, and the sample size decreases as the table size gets larger, as Joe Sack showed in his post, Auto-Update Stats Default Sampling Test. In some cases, the sample size may not be large enough to capture enough interesting information, or the right information, for the statistics histogram, as noted by Conor Cunningham in his Statistics Sample Rates post. If the default sample does not create a good histogram, DBAs can choose to update statistics with a higher sampling rate, up to a FULLSCAN (scanning all rows in the table or indexed view). But as Conor mentioned in his post, scanning more rows comes at a cost, and the DBA is challenged with deciding whether to run a FULLSCAN to try and create the “best” histogram possible, or sample a smaller percentage to minimize the performance impact of the update.
To try and understand at what point a sample takes longer than a FULLSCAN, I ran the following statements against copies of the SalesOrderDetail table that were enlarged using Jonathan Kehayias’ script:
| statement ID | UPDATE STATISTICS statement |
|---|---|
| 1 | UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged] WITH FULLSCAN; |
| 2 | UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged]; |
| 3 | UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged] WITH SAMPLE 10 PERCENT; |
| 4 | UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged] WITH SAMPLE 25 PERCENT; |
| 5 | UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged] WITH SAMPLE 50 PERCENT; |
| 6 | UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged] WITH SAMPLE 75 PERCENT; |
I had three copies of the SalesOrderDetailEnlarged table, with the following characteristics*:
| Row Count | Page Count | MAXDOP | Max Memory | Storage | Machine |
|---|---|---|---|---|---|
| 23,899,449 | 363,284 | 4 | 8GB | SSD_1 | Laptop |
| 607,312,902 | 7,757,200 | 16 | 54GB | SSD_2 | Test Server |
| 607,312,902 | 7,757,200 | 16 | 54GB | 15K | Test Server |
*Additional details about the hardware are at the end of this post.
All copies of the table had the following statistics, and none of the three index statistics had included columns:
| Statistic | Type | Columns in Key |
|---|---|---|
| PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID | Index | SalesOrderID, SalesOrderDetailID |
| AK_SalesOrderDetailEnlarged_rowguid | Index | rowguid |
| IX_SalesOrderDetailEnlarged_ProductID | Index | ProductId |
| user_CarrierTrackingNumber | Column | CarrierTrackingNumber |
I ran the above UPDATE STATISTICS statements four times each against the SalesOrderDetailEnlarged table on my laptop, and twice each against the SalesOrderDetailEnlarged tables on the TestServer. Statements were run in random order each time, and procedure cache and buffer cache were cleared before each update statement. The duration and tempdb usage for each set of statements (averaged) are in the graphs below:
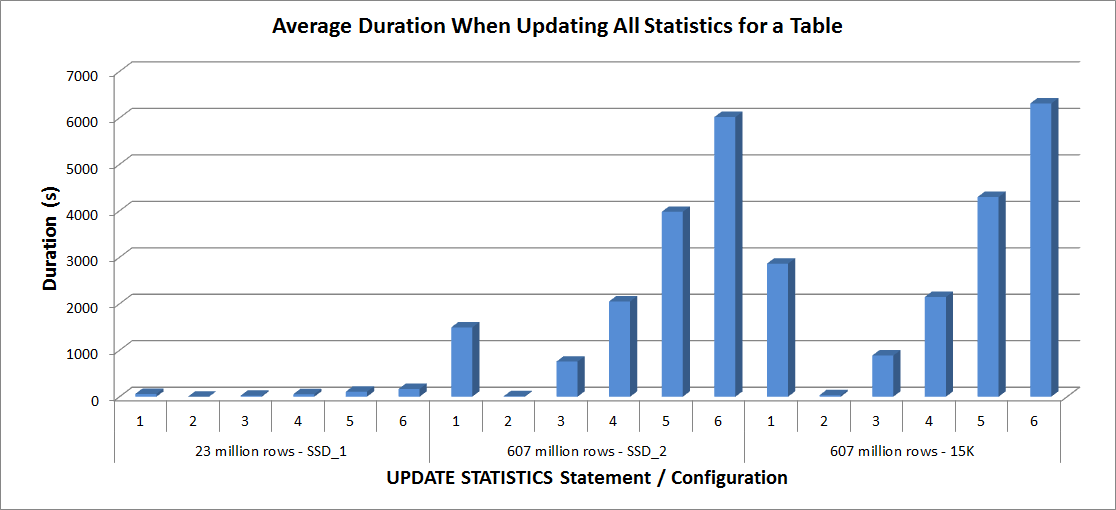
Average Duration – Update All Statistics for SalesOrderDetailEnlarged
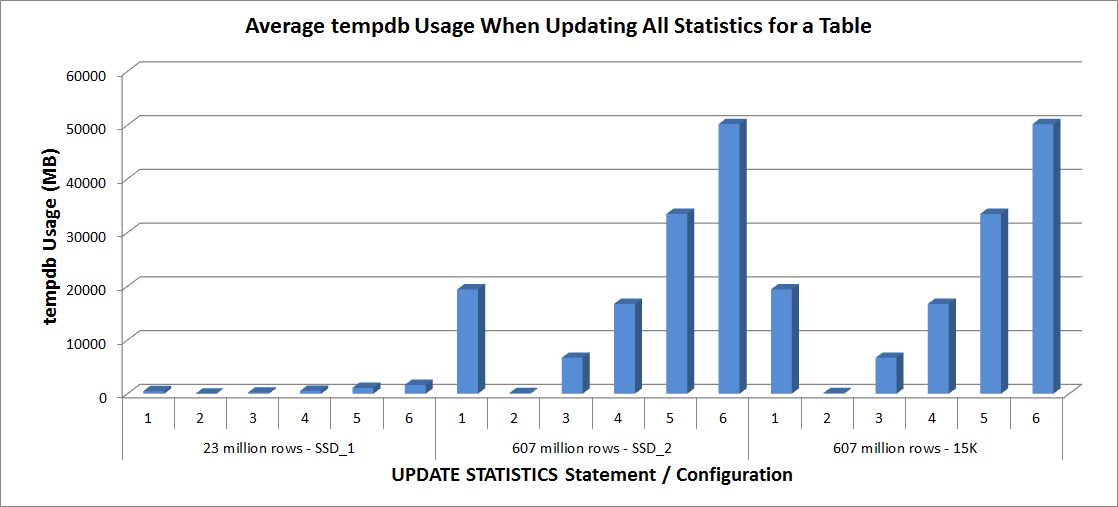
tempdb Usage – Update All Statistics for SalesOrderDetailEnlarged
The durations for the 23 million row table were all less than three minutes, and are described in more detail in the next section. For the table on the SSD_2 disks, the FULLSCAN statement took 1492 seconds (almost 25 minutes) and the update with a 25% sample took 2051 seconds (over 34 minutes). In contrast, on the 15K disks, the FULLSCAN statement took 2864 seconds (over 47 minutes) and the update with a 25% sample took 2147 seconds (almost 36 minutes) – less than time the FULLSCAN. However, the update with a 50% sample took 4296 seconds (over 71 minutes).
Tempdb usage is much more consistent, showing a steady increase as the sample size increases, and using more tempdb space than a FULLSCAN somewhere between 25% and 50%. What’s notable here is that UPDATE STATISTICS does use tempdb, which is important to remember when you’re sizing tempdb for a SQL Server environment. Tempdb usage is mentioned in the UPDATE STATISTICS BOL entry:
UPDATE STATISTICS can use tempdb to sort the sample of rows for building statistics.”
And the effect is documented in Linchi Shea’s post, Performance impact: tempdb and update statistics. However, it’s not something always mentioned during tempdb sizing discussions. If you have large tables and perform updates with FULLSCAN or high sample values, be aware of the tempdb usage.
Performance of Selective Updates
I next decided to test the UPDATE STATISTICS statements for the other statistics on the table, but limited my tests to the copy of the table with 23 million rows. The above six variations of the UPDATE STATISTICS statement were repeated four times each for the following individual statistics and then compared against the update for the entire table:
- PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID
- IX_SalesOrderDetailEnlarged_ProductID
- user_CarrierTrackingNumber
All tests were run with the aforementioned configuration on my laptop, and the results are in the graph below:
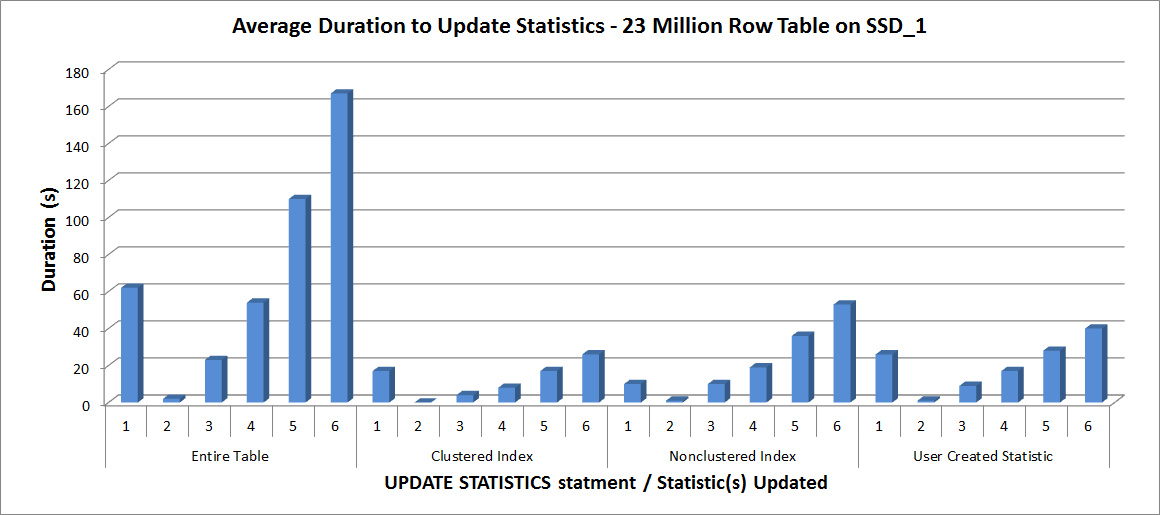
Average Duration for UPDATE STATISTICS – All Statistics vs. Selected
As expected, the updates to an individual statistic took less time than when updating all statistics for the table. The value at which the sampled updated took longer than a FULLSCAN varied:
| UPDATE statement | FULLSCAN duration (s) | First UPDATE that took longer |
|---|---|---|
| Entire Table | 62 | 50% – 110 seconds |
| Clustered Index | 17 | 75% – 26 seconds |
| Nonclustered Index | 10 | 25% – 19 seconds |
| User Created Statistic | 26 | 50% – 28 seconds |
Conclusion
Based on this data, and the FULLSCAN data from the 607 million row tables, there is no specific tipping point where a sampled update takes longer than a FULLSCAN; that point is dependent on table size and the resources available. But the data is still worthwhile as it demonstrates that there is a point where a sampled valued can take longer to capture than a FULLSCAN. It again comes down to knowing your data. This is critical to not only understand whether a table needs custom management of statistics, but also to understand the ideal sample size to create a useful histogram and also optimize resource usage.
Specifications
Test Server specifications: Dell R720, 2 Intel E5-2670 (2.6GHz 8 cores and HT is enabled so 16 logical cores per socket), 64 GB memory, Windows 2012, SQL Server 2012 SP1 (11.0.3339.0 x64), database files for one table are located on two 640GB Fusion-io Duo MLC cards, database files for the other table are on nine 15K RPM disks in a RAID5 array
8 thoughts on “Sample Size and the Duration of UPDATE STATISTICS: Does It Matter?”
Comments are closed.

Interesting figures – could it be that FULLSCAN is more likely to benefit from READ AHEAD?
Hi John-
I expect it's a combination of READ AHEAD and also parallelism. I'll be working on another post to prove that out. Thanks for reading!
Erin
Erin,
Of course! Sample stats run single-threaded, don't they!
It's interesting to see in your Avg Duration graph that the times between the SSD 2 and 15K drives don't seem that different with sampling. Is that an artifact of the graph or are the times close? The 25% sample times you list are close, which seems to indicate that disk IO isn't as much of a factor with the sampling. Is that true?
Steve-
I'm thinking you're talking about the "Average Duration When Updating All Statistics for a Table" graph. Here are the raw numbers for the SSD_2 and 15K:
The durations are close for many of the sample sizes – and I would agree that the effect of sampling (and however the engine is doing that – every Xth page) is a bigger factor than the disk itself. Again, the most interesting thing here is that sampling at 25% takes LONGER on the SSDs than a FULLSCAN (and at 50% for 15K disks), so to me that definitely suggests it's the method (algorithm) used for sampling.
E
Hi Erin, how can we determine the sampling % to use when updating statistics? Thanks
My general advice is to use the default sample until you find out that isn't providing enough detail for the optimizer, and then look at using a full scan or possibly creating filtered statistics, depending on the size of the table. You'll typically "find" that skew if you have queries that sometimes run well and sometimes do not – because the plans are parameter sensitive. It all comes down to the skew in the table. For an even distribution of data, the default sample works just fine. For data sets with non-standard distributions (skew in some places, many places), then you need a better sample of the data. See Kimberly's post on how to find data sets with lots of skew (http://www.sqlskills.com/blogs/kimberly/sqlskills-procs-analyze-data-skew-create-filtered-statistics/). Hope that helps!
Hi Erin, Thanks for your advice and also for the link that you've provided. I appreciate it. They are very useful. Thank you and keep up the great work!