
The Case of the Cardinality Estimate Red Herring
You are working with a developer who is reporting slow performance for the following stored procedure call:
EXEC [dbo].[charge_by_date] '2/28/2013';You ask what issue the developer is seeing, but the only additional information you hear back is that it is "running slowly." So you jump on the SQL Server instance and take a look at the actual execution plan. You do this because you are interested in not only what the execution plan looks like but also what the estimated versus actual number of rows are for the plan:
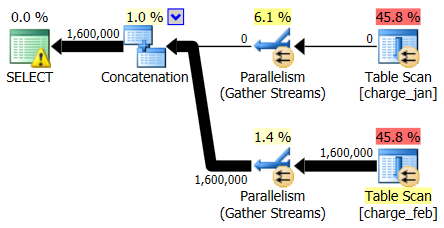
Looking first just at the plan operators, you can see a few noteworthy details:
- There is a warning in the root operator
- There is a table scan for both tables referenced at the leaf level (charge_jan and charge_feb) and you wonder why these are both still heaps and don’t have clustered indexes
- You see that there are only rows flowing through the charge_feb table and not the charge_jan table
- You see parallel zones in the plan
As for the warning in the root iterator, you hover over it and see that there are missing index warnings with a recommendation for the following indexes:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>]
ON [dbo].[charge_feb] ([charge_dt])
INCLUDE ([charge_no])
GO
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>]
ON [dbo].[charge_jan] ([charge_dt])
INCLUDE ([charge_no])
GOYou ask the original database developer why there isn’t a clustered index, and the reply is “I don’t know.”
Continuing the investigation before making any changes, you look at the Plan Tree tab in SQL Sentry Plan Explorer and you do indeed see that there are significant skews between the estimated versus actual rows for one of the tables:
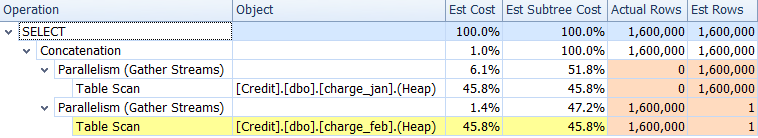
There seems to be two issues:
- An under-estimate for rows in the charge_jan table scan
- An over-estimate for rows in the charge_feb table scan
So the cardinality estimates are skewed, and you wonder if this is related to parameter sniffing. You decide to check the parameter compiled value and compare it to the parameter runtime value, which you can see on the Parameters tab:

Indeed there are differences between the runtime value and the compiled value. You copy over the database to a prod-like testing environment and then test execution of the stored procedure with the runtime value of 2/28/2013 first and then 1/31/2013 afterwards.
The 2/28/2013 and 1/31/2013 plans have identical shapes but different actual data flows. The 2/28/2013 plan and cardinality estimates were as follows:
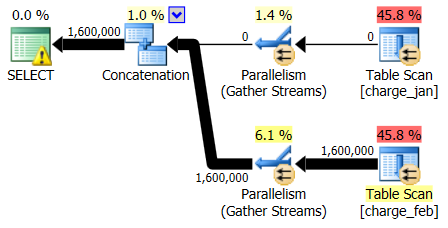

And while the 2/28/2013 plan shows no cardinality estimation issue, the 1/31/2013 plan does:
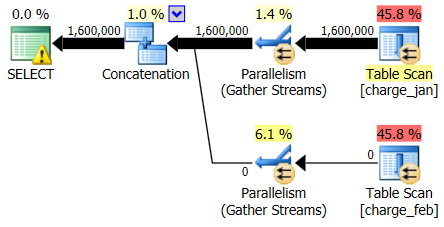
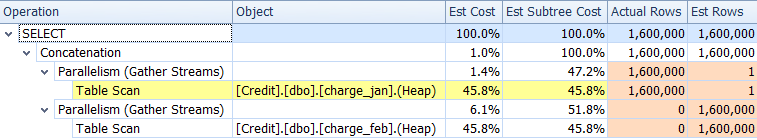
So the second plan shows the same over and under-estimates, just reversed from the original plan you looked at.
You decide to add the suggested indexes to the prod-like test environment for both the charge_jan and charge_feb tables and see if that helps at all. Executing the stored procedures in January / February order, you see the following new plan shapes and associated cardinality estimates:
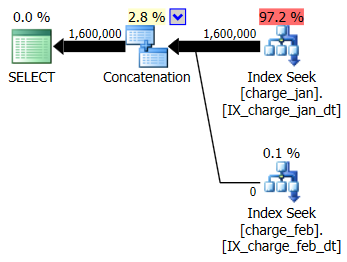

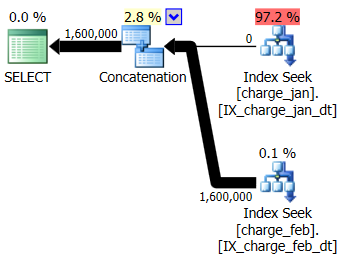

The new plan uses an Index Seek operation from each table, but you still see zero rows flowing from one table and not the other, and you still see cardinality estimate skews based on parameter sniffing when the runtime value is in a different month from the compile time value.
Your team has a policy of not adding indexes without proof of sufficient benefit and associated regression testing. You decide, for the time being, to remove the nonclustered indexes you just created. While you don’t immediately address the missing clustered index, you decide you’ll take care of it later.
At this point you realize you need to look further into the stored procedure definition, which is as follows:
CREATE PROCEDURE dbo.charge_by_date
@charge_dt datetime
AS
SELECT charge_no
FROM dbo.charge_view
WHERE charge_dt = @charge_dt
GONext you look at the charge_view object definition:
CREATE VIEW charge_view
AS
SELECT *
FROM [charge_jan]
UNION ALL
SELECT *
FROM [charge_feb]
GOThe view references charge data that is separated into different tables by date. And then you wonder if the second query execution plan skew can be prevented through changing the stored procedure definition.
Perhaps if the optimizer knows at runtime what the value is, the cardinality estimate issue will go away and improve overall performance?
You go ahead and redefine the stored procedure call as follows, adding a RECOMPILE hint (knowing that you’ve also heard that this can increase CPU usage, but since this is a test environment, you feel safe giving it a try):
ALTER PROCEDURE charge_by_date
@charge_dt datetime
AS
SELECT charge_no
FROM dbo.charge_view
WHERE charge_dt = @charge_dt
OPTION (RECOMPILE);
GOYou then re-execute the stored procedure using the 1/31/2013 value and then the 2/28/2013 value.
The plan shape stays the same, but now the cardinality estimate issue is removed.
The 1/31/2013 cardinality estimate data shows:

And the 2/28/2013 cardinality estimate data shows:
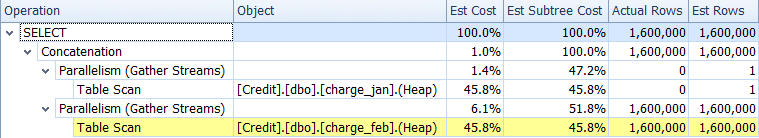
That makes you happy for a moment, but then you realize the duration of the overall query execution seems relatively the same as it was before. You begin to have doubt that the developer will be happy with your results. You’ve solved the cardinality estimate skew, but without the expected performance boost, you’re unsure if you’ve helped in any meaningful way.
It’s at this point that you realize that the query execution plan is just a subset of the information you might need, and so you expand your exploration further by looking at the Table I/O tab. You see the following output for the 1/31/2013 execution:

And for the 2/28/2013 execution you see similar data:

It’s at that point that you wonder if the data access operations for both tables are necessary in each plan. If the optimizer knows you only need January rows, why access February at all, and vice versa? You also remember that the query optimizer has no guarantees that there aren’t actual rows from the other months in the “wrong” table unless such guarantees were made explicitly via constraints on the table itself.
You check the table definitions via sp_help for each table and you don’t see any constraints defined for either table.
So as a test, you add the following two constraints:
ALTER TABLE [dbo].[charge_jan]
ADD CONSTRAINT charge_jan_chk CHECK
(charge_dt >= '1/1/2013' AND charge_dt < '2/1/2013');
GO
ALTER TABLE [dbo].[charge_feb]
ADD CONSTRAINT charge_feb_chk CHECK
(charge_dt >= '2/1/2013' AND charge_dt < '3/1/2013');
GOYou re-execute the stored procedures and see the following plan shapes and cardinality estimates.
1/31/2013 execution:
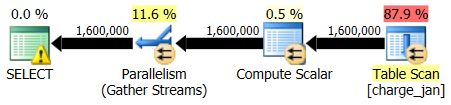

2/28/2013 execution:


Looking at Table I/O again, you see the following output for the 1/31/2013 execution:

And for the 2/28/2013 execution you see similar data, but for the charge_feb table:

Remembering that you have the RECOMPILE still in the stored procedure definition, you try removing it and seeing if you see the same effect. After doing this, you see the two-table access return, but with no actual logical reads for the table that has no rows in it (compared to the original plan without the constraints). For example, the 1/31/2013 execution showed the following Table I/O output:

You decide to move forward with load-testing the new CHECK constraints and RECOMPILE solution, removing the table access entirely from the plan (and the associated plan operators). You also prepare yourself for a debate about the clustered index key and a suitable supporting nonclustered index that will accommodate a broader set of workloads that currently access the associated tables.
5 thoughts on “The Case of the Cardinality Estimate Red Herring”
Comments are closed.

I thought you were about to show the final plan with Filters that use Startup Expression Predicates, and Actual Number Of Executions = 0 on the Scans, demonstrating the effect of the constraint predicates within the plan.
Nice post either way, of course…
Thanks Rob!
For the final example – where we're executing the stored procedure with the statement RECOMPILE and have the associated constraints, there is no StartupExpression attribute in the plan. For a February execution, the plan has no reference to the January table itself.
Thanks for the walkthrough Joe. Very well explained. I like the second-person narrative.
I never thought to consider using check constraints while troubleshooting a performance issue!
If I were in the shoes of the developer I might have leaned harder on proper indexing.
Thanks Michael!
And agreed – the indexing + constraint approach would ultimately be something to push for.