
How expensive are column-side Implicit Conversions?
In the last month I’ve engaged with numerous customers that have had column-side implicit conversion issues associated with their OLTP workloads. On two occasions, the accumulated effect of the column-side implicit conversions was the underlying cause of the overall performance problem for the SQL Server being reviewed, and unfortunately there isn’t a magic setting or configuration option that we can tweak to improve the situation when this is the case. While we can offer suggestions to fix other, lower-hanging fruit that might be affecting performance overall, the effect of the column-side implicit conversions is something that requires either a schema design change to fix, or a code change to prevent the column-side conversion from occurring against the current database schema completely.
Implicit conversions are the result of the database engine comparing values of differing data types during query execution. A list of the possible implicit conversions that could occur inside of the database engine can be found in the Books Online topic Data Type Conversion (Database Engine). Implicit conversions always occur based on the data type precedence for the data types that are being compared during the operation. The data type precedence order can be found in the Books Online topic Data Type Precedence (Transact-SQL). I recently blogged about the implicit conversions that result in an index scan, and provided charts that can be used to determine the most problematic implicit conversions as well.
Setting up the Tests
To demonstrate the performance overhead associated with column-side implicit conversions that result in an index scan, I’ve run a series of different tests against the AdventureWorks2012 database using the Sales.SalesOrderDetail table to build test tables and data sets. The most common column-side implicit conversion that I see as a consultant occurs when the column type is char or varchar, and the application code passes a parameter that is nchar or nvarchar and filters on the char or varchar column. To simulate this type of scenario, I created a copy of the SalesOrderDetail table (named SalesOrderDetail_ASCII) and changed the CarrierTrackingNumber column from nvarchar to varchar. Additionally, I added a nonclustered index on the CarrierTrackingNumber column to the original SalesOrderDetail table, as well as the new SalesOrderDetail_ASCII table.
USE [AdventureWorks2012]
GO
-- Add CarrierTrackingNumber index to original Sales.SalesOrderDetail table
IF NOT EXISTS
(
SELECT 1 FROM sys.indexes
WHERE [object_id] = OBJECT_ID(N'Sales.SalesOrderDetail')
AND name=N'IX_SalesOrderDetail_CarrierTrackingNumber'
)
BEGIN
CREATE INDEX IX_SalesOrderDetail_CarrierTrackingNumber
ON Sales.SalesOrderDetail (CarrierTrackingNumber);
END
GO
IF OBJECT_ID('Sales.SalesOrderDetail_ASCII') IS NOT NULL
BEGIN
DROP TABLE Sales.SalesOrderDetail_ASCII;
END
GO
CREATE TABLE Sales.SalesOrderDetail_ASCII
(
SalesOrderID int NOT NULL,
SalesOrderDetailID int NOT NULL IDENTITY (1, 1),
CarrierTrackingNumber varchar(25) NULL,
OrderQty smallint NOT NULL,
ProductID int NOT NULL,
SpecialOfferID int NOT NULL,
UnitPrice money NOT NULL,
UnitPriceDiscount money NOT NULL,
LineTotal AS (isnull(([UnitPrice]*((1.0)-[UnitPriceDiscount]))*[OrderQty],(0.0))),
rowguid uniqueidentifier NOT NULL ROWGUIDCOL,
ModifiedDate datetime NOT NULL
);
GO
SET IDENTITY_INSERT Sales.SalesOrderDetail_ASCII ON;
GO
INSERT INTO Sales.SalesOrderDetail_ASCII
(
SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber,
OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount, rowguid, ModifiedDate
)
SELECT
SalesOrderID, SalesOrderDetailID, CONVERT(varchar(25), CarrierTrackingNumber),
OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount, rowguid, ModifiedDate
FROM Sales.SalesOrderDetail WITH (HOLDLOCK TABLOCKX);
GO
SET IDENTITY_INSERT Sales.SalesOrderDetail_ASCII OFF;
GO
ALTER TABLE Sales.SalesOrderDetail_ASCII ADD CONSTRAINT
PK_SalesOrderDetail_ASCII_SalesOrderID_SalesOrderDetailID
PRIMARY KEY CLUSTERED (SalesOrderID, SalesOrderDetailID);
CREATE UNIQUE NONCLUSTERED INDEX AK_SalesOrderDetail_ASCII_rowguid
ON Sales.SalesOrderDetail_ASCII (rowguid);
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_ASCII_ProductID
ON Sales.SalesOrderDetail_ASCII (ProductID);
CREATE INDEX IX_SalesOrderDetail_ASCII_CarrierTrackingNumber
ON Sales.SalesOrderDetail_ASCII (CarrierTrackingNumber);
GO
The new SalesOrderDetail_ASCII table has 121,317 rows and is 17.5MB in size, and will be used to evaluate the overhead of a small table. I also created a table that is ten times larger, using a modified version of the Enlarging the AdventureWorks Sample Databases script from my blog, that contains 1,334,487 rows and is 190MB in size. The test server for this is the same 4 vCPU VM with 4GB RAM, running Windows Server 2008 R2 and SQL Server 2012, with Service Pack 1 and Cumulative Update 3, that I have used in previous articles, so the tables will fit entirely in memory, eliminating disk I/O overhead from affecting the tests being run.
The test workload was generated using a series of PowerShell scripts which select the list of CarrierTrackingNumbers from the SalesOrderDetail table building an ArrayList, and then randomly select a CarrierTrackingNumber from the ArrayList to query the SalesOrderDetail_ASCII table using a varchar parameter and then an nvarchar parameter, and then to query the SalesOrderDetail table using an nvarchar parameter to provide a comparison for where the column and parameter both are nvarchar. Each of the individual tests runs the statement 10,000 times to allow measuring the performance overhead over a sustained workload.
#No Implicit Conversions
$loop = 10000;
Write-Host "Small table no conversion start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail_ASCII "
"WHERE CarrierTrackingNumber = @CTNumber;";
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::VarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table no conversion end time:"
[DateTime]::Now
Sleep -Seconds 10;
#Small table implicit conversions
$loop = 10000;
Write-Host "Small table implicit conversions start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail_ASCII "
"WHERE CarrierTrackingNumber = @CTNumber;";
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::NVarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table implicit conversions end time:"
[DateTime]::Now
Sleep -Seconds 10;
#Small table unicode no implicit conversions
$loop = 10000;
Write-Host "Small table unicode no implicit conversion start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail "
"WHERE CarrierTrackingNumber = @CTNumber;"
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::NVarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table unicode no implicit conversion end time:"
[DateTime]::Now
A second set of tests were run against the SalesOrderDetailEnlarged_ASCII and SalesOrderDetailEnlarged tables using the same parameterization as the first set of tests to show the overhead difference as the size of the data stored in the table increases over time. A final set of tests was also run against the SalesOrderDetail table using the ProductID column as a filter column with parameter types of int, bigint, and then smallint to provide a comparison of the overhead of implicit conversions that don’t result in an index scan for comparision.
Note: All of the scripts are attached to this article to allow reproduction of the implicit conversion tests for further evaluation and comparison.
Test Results
During each of the test executions, Performance Monitor was configured to run a Data Collector Set that included the Processor\% Processor Time and SQL Server:SQLStatisitics\Batch Requests/sec counters to track the performance overhead for each of the tests. Additionally, Extended Events has been configured to track the rpc_completed event to allow tracking the average duration, cpu_time, and logical reads for each of the tests.
Small Table CarrierTrackingNumber Results
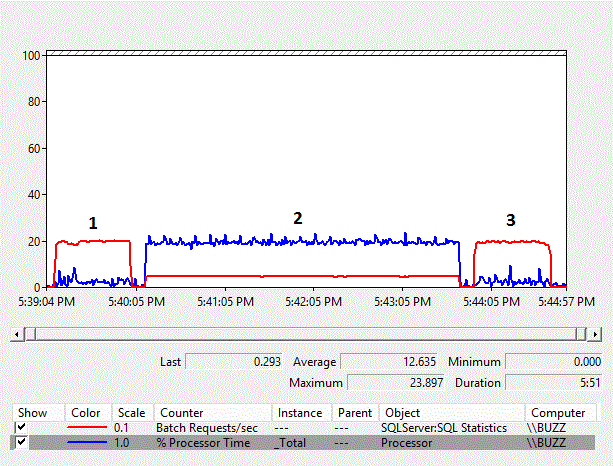
Figure 1 – Performance Monitor Chart of counters
| TestID | Column Data Type | Parameter Data Type | Avg % Processor Time | Avg Batch Requests/sec | Duration h:mm:ss |
|---|---|---|---|---|---|
| 1 | Varchar | Varchar | 2.5 | 192.3 | 0:00:51 |
| 2 | Varchar | Nvarchar | 19.4 | 46.7 | 0:03:33 |
| 3 | Nvarchar | Nvarchar | 2.6 | 192.3 | 0:00:51 |
Table 2 – Performance Monitor data averages
From the results, we can see that the column-side implicit conversion from varchar to nvarchar and the resulting index scan has a significant impact on the performance of the workload. The average % Processor Time for the column-side implicit conversion test (TestID = 2) is nearly ten times as much as the other tests where the column-side implicit conversion, resulting in an index scan, did not occur. Additionally, the average Batch Requests/sec for the column-side implicit conversion test was just under 25% of the other tests. The duration of the tests where implicit conversions did not occur both took 51 seconds, even though the data was stored as nvarchar in test number 3 using an nvarchar data type, requiring twice the storage space. This is expected because the table is still smaller than the buffer pool.
| TestID | Avg cpu_time (µs) | Avg duration (µs) | Avg logical_reads |
|---|---|---|---|
| 1 | 40.7 | 154.9 | 51.6 |
| 2 | 15,640.8 | 15,760.0 | 385.6 |
| 3 | 45.3 | 169.7 | 52.7 |
Table 3 – Extended Events averages
The data collected by the rpc_completed event in Extended Events shows that the average cpu_time, duration, and logical reads associated with the queries that do not perform a column-side implicit conversion are roughly equivalent, where the column-side implicit conversion incurs a significant CPU overhead, as well as a longer average duration with significantly more logical reads.
Enlarged Table CarrierTrackingNumber Results
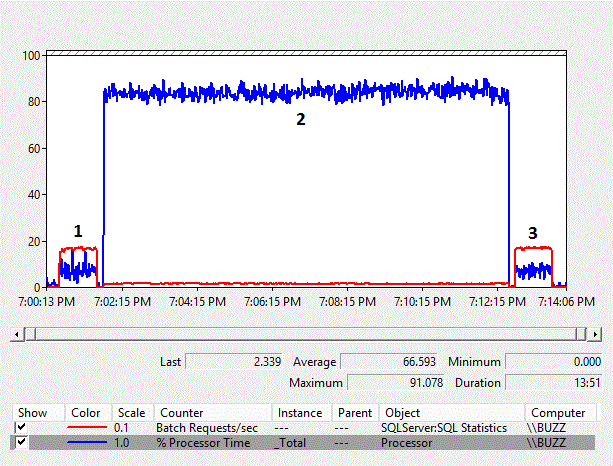
Figure 4 – Performance Monitor Chart of counters
| TestID | Column Data Type | Parameter Data Type | Avg % Processor Time | Avg Batch Requests/sec | Duration h:mm:ss |
|---|---|---|---|---|---|
| 1 | Varchar | Varchar | 7.2 | 164.0 | 0:01:00 |
| 2 | Varchar | Nvarchar | 83.8 | 15.4 | 0:10:49 |
| 3 | Nvarchar | Nvarchar | 7.0 | 166.7 | 0:01:00 |
Table 5 – Performance Monitor data averages
As the size of the data increases, the performance overhead of the column-side implicit conversion also increases. The average % Processor Time for the column-side implicit conversion test (TestID = 2) is, again, nearly ten times as much as the other tests where the column-side implicit conversion resulting in an index scan, did not occur. Additionally, the average Batch Requests/sec for the column-side implicit conversion test was just under 10% of the other tests. The duration of the tests where implicit conversions did not occur both took one minute, whereas the column-side implicit conversion test required close to eleven minutes to execute.
| TestID | Avg cpu_time (µs) | Avg duration (µs) | Avg logical_reads |
|---|---|---|---|
| 1 | 728.5 | 1,036.5 | 569.6 |
| 2 | 214,174.6 | 59,519.1 | 4,358.2 |
| 3 | 821.5 | 1,032.4 | 553.5 |
Table 6 – Extended Events averages
The Extended Events results really begin to show the performance overhead caused by the column-side implicit conversions for the workload. The average cpu_time per execution jumps to over 214ms and is over 200 times the cpu_time for the statements that do not have the column-side implicit conversions. The duration is also nearly 60 times that of the statements that do not have the column-side implicit conversions.
Summary
As the size of the data continues to increase, the overhead associated with column-side implicit conversions that result in an index scan for the workload will also continue to grow, and the important thing to remember is that at some point, no amount of hardware will be able to cope with the performance overhead. Implicit conversions are an easy thing to prevent when a good database schema design exists, and developers follow good application coding techniques. In situations where the application coding practices result in parameterization that leverages nvarchar parameterization, it is better to match the database schema design to the query parameterization than to use varchar columns in the database design and incur the performance overhead from the column-side implicit conversion.
Download the demo scripts: Implicit_Conversion_Tests.zip (5 KB)
7 thoughts on “How expensive are column-side Implicit Conversions?”
Comments are closed.

We had the same issue. Our 24 processor machine was clocking around 80% CPU usage just because of this. The query was being executed around 4-5 times per second. Fixing this, brought CPU usage to 1-2%. After that I had created a script to find all the index scan due to convert and function usage on the column using dm_exec-query_plan DMV. Thus I have fixed other issues which we causing them. Good thing was that other queries were being executed infrequently thus CPU spike was never there.
Would you mind sharing the script?
Mark, the article has two links to a zip file containing all of the demo scripts.
Thanks Aaron
I was referring to Gulli.meel1's post: "After that I had created a script to find all the index scan due to convert and function usage on the column using dm_exec-query_plan DMV"
Regards
mark
Very good explanation, Thank you.