
Beware misleading data from SET STATISTICS IO
My co-worker Steve Wright (blog | @SQL_Steve) prodded me with a question recently on a strange result he was seeing. In order to test some functionality in our latest tool, SQL Sentry Plan Explorer PRO, he had manufactured a wide and large table, and was running a variety of queries against it. In one case he was returning a lot of data, but STATISTICS IO was showing that very few reads were taking place. I pinged some people on #sqlhelp and, since it seemed nobody had seen this issue, I thought I would blog about it.
TL;DR Version
In short, be very aware that there are some scenarios where you can't rely on STATISTICS IO to tell you the truth. In some cases (this one involving TOP and parallelism), it will vastly under-report logical reads. This can lead you to believe you have a very I/O-friendly query when you don't. There are other more obvious cases – such as when you have a bunch of I/O hidden away by the use of scalar user-defined functions. We think Plan Explorer makes those cases more obvious; this one, however, is a little trickier.
The problem query
The table has 37 million rows, up to 250 bytes per row, about 1 million pages, and very low fragmentation (0.42% on level 0, 15% on level 1, and 0 beyond that). There are no computed columns, no UDFs in play, and no indexes except a clustered primary key on the leading INT column. A simple query returning 500,000 rows, all columns, using TOP and SELECT *:
SET STATISTICS IO ON;
SELECT TOP 500000 * FROM dbo.OrderHistory
WHERE OrderDate < (SELECT '19961029');(And yes, I realize I am violating my own rules and using SELECT * and TOP without ORDER BY, but for the sake of simplicity I am trying my best to minimize my influence on the optimizer.)
Results:
Table 'OrderHistory'. Scan count 1, logical reads 23, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
We're returning 500,000 rows, and it takes about 10 seconds. I immediately know that something is wrong with the logical reads number. Even if I didn't already know about the underlying data, I can tell from the grid results in Management Studio that this is pulling more than 23 pages of data, whether they are from memory or cache, and this should be reflected somewhere in STATISTICS IO. Looking at the plan...
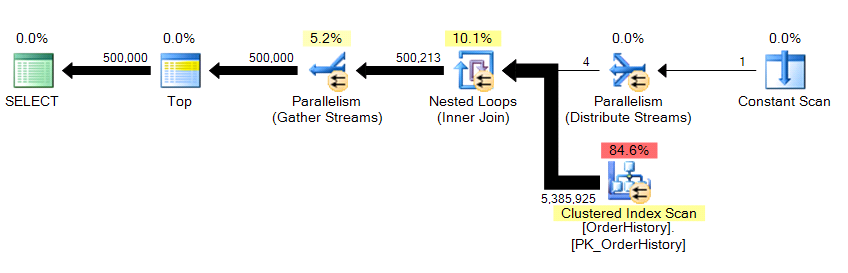
...we see parallelism is in there, and that we've scanned the entire table. So how is it possible that there are only 23 logical reads?
Another "identical" query
One of my first questions back to Steve was: "What happens if you eliminate parallelism?" So I tried it out. I took the original subquery version and added MAXDOP 1:
SET STATISTICS IO ON;
SELECT TOP 500000 * FROM dbo.OrderHistory
WHERE OrderDate < (SELECT '19961029') OPTION (MAXDOP 1);Results and plan:
Table 'OrderHistory'. Scan count 1, logical reads 149589, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
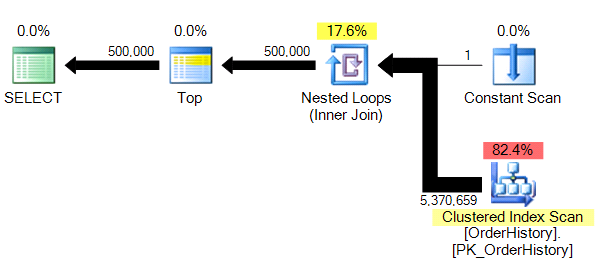
We have a slightly less complex plan, and without the parallelism (for obvious reasons), STATISTICS IO is showing us much more believable numbers for logical read counts.
What is the truth?
It's not hard to see that one of these queries is not telling the whole truth. While STATISTICS IO might not tell us the whole story, maybe trace will. If we retrieve runtime metrics by generating an actual execution plan in Plan Explorer, we see that the magical low-read query is, in fact, pulling the data from memory or disk, and not from a cloud of magic pixie dust. In fact it has *more* reads than the other version:

So it is clear that reads are happening, they're just not appearing correctly in the STATISTICS IO output.
What is the problem?
Well, I'll be quite honest: I don't know, other than the fact that parallelism is definitely playing a role, and it seems to be some kind of race condition. STATISTICS IO (and, since that's where we get the data, our Table I/O tab) shows a very misleading number of reads. It's clear that the query returns all of the data we're looking for, and it's clear from the trace results that it uses reads and not osmosis to do so. I asked Paul White (blog | @SQL_Kiwi) about it and he suggested that only some of the pre-thread I/O counts are being included in the total (and agrees that this is a bug).
If you want to try this out at home, all you need is AdventureWorks (this should repro against 2008, 2008 R2 and 2012 versions), and the following query:
SET STATISTICS IO ON;
DBCC SETCPUWEIGHT(1000) WITH NO_INFOMSGS;
GO
SELECT TOP (15000) *
FROM Sales.SalesOrderHeader
WHERE OrderDate < (SELECT '20080101');
SELECT TOP (15000) *
FROM Sales.SalesOrderHeader
WHERE OrderDate < (SELECT '20080101')
OPTION (MAXDOP 1);
DBCC SETCPUWEIGHT(1) WITH NO_INFOMSGS;(Note that SETCPUWEIGHT is only used to coax parallelism. For more info, see Paul White's blog post on Plan Costing.)
Results:
Table 'SalesOrderHeader'. Scan count 1, logical reads 333, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Paul pointed out an even simpler repro:
SET STATISTICS IO ON;
GO
SELECT TOP (15000) *
FROM Production.TransactionHistory
WHERE TransactionDate < (SELECT '20080101')
OPTION (QUERYTRACEON 8649, MAXDOP 4);
SELECT TOP (15000) *
FROM Production.TransactionHistory AS th
WHERE TransactionDate < (SELECT '20080101');Results:
Table 'TransactionHistory'. Scan count 1, logical reads 110, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
So it seems that we can easily reproduce this at will with a TOP operator and a low enough DOP. I've filed a bug:
And Paul has filed two other somewhat-related bugs involving parallelism, the first as a result of our conversation:
- Cardinality Estimation Error With Pushed Predicate on a Lookup [ related blog post ]
- Poor Performance with Parallelism and Top [ related blog post ]
(For the nostalgic, here are six other parallelism bugs I pointed out a few years ago.)
What is the lesson?
Be careful about trusting a single source. If you look solely at STATISTICS IO after changing a query like this, you may be tempted to focus on the miraculous drop in reads instead of the increase in duration. At which point you may pat yourself on the back, leave work early and enjoy your weekend, thinking you have just made a tremendous performance impact on your query. When of course nothing could be further from the truth.
11 thoughts on “Beware misleading data from SET STATISTICS IO”
Comments are closed.

Excellent post, Aaron, and very revealing. SET STATISTICS IO is one of my favorite tuning techniques. So now I know that I have to use it with a more skeptical eye.
But you also highlight another tuning axiom that I sometimes forget – true performance problems are best revealed by cross-checking the performance metrics across more than one source. Any time you rely on just one source of tuning information, you're bound to encounter a weakness at some point or another.
So it's better to use a combination of sources when tuning true important aspects of system performance.
-Kev
Great post, very interesting. What happens if you cold-start the question, do you get the same effect in the physical and read-ahead reads?
Regards Ove
Thanks Ove, I haven't tested that yet. However, I'm not sure how relevant that would be, since 99% of the time you're not running queries with a cold cache. :-)
Nice post Aaron, as usual. I have noticed eroneous statistics IO reporting when accessing column store indexes too.
Interesting post.
The bug you reference is supposedly fixed, but we're still experiencing Logical Reads being under reported when using Set Statistics IO On. (4000 reported, 12 million in SQL Sentry)
Setting the MAXDOP 1 option doesn't correct the problem by eliminating the parallelism in the execution plan.
Do you know of other issues with this feature?
Hi Darian, I don't, sorry. What is @@version?
@@version =
Microsoft SQL Server 2014 – 12.0.4422.0 (X64) Jul 27 2015 16:56:19 Copyright (c) Microsoft Corporation Enterprise Edition: Core-based Licensing (64-bit) on Windows NT 6.3 (Build 9600: )
So my suggestion would be to open a support case with Microsoft. Provided that:
1. You've validated that the actual plans from both SSMS and Plan Explorer are 100% identical. There could be differences in the plans leading to different I/O based on various things, some as simple as SET settings like ARITHABORT. If the plans are different, you can see if it's for any of these reasons and for SET settings specifically see this post from Erland Sommarskog.
2. You really, really care about the accuracy of stats I/O coming out of SSMS. I pick my clothes in the morning based mostly on the temperature, and I have multiple potential sources for that information – with varying degrees of accuracy (and hence trust). The local news meteorologist, the weather app on my phone, and the thermometer outside my window. I trust the latter most, so that's what I use.
Ditto. We are using Microsoft SQL Server 2014 – 12.0.4213.0 (X64) and my query plan points to tableX as having a 74% impact on the total, yet the io statistics does not even mention tableX.
My query is basically select .. from tableX where exists(..subquery..). Tables referred to by the subqueries are included, but tableX is MIA.
The Bug seams to be fixed in SQL 2014.
I tested your script on SQL Server 2014 12.0.4213.0 on an AdventureWorks 2014 and AdventureWorks 2012 in Compatibility Level 120 and 130.
All of them showing higher Logical Reads for the first query.
I re-tested on SQL 2012 11.0.3000.0 with the AdventureWorks 2012 and saw the bug still being open.