
Splitting Strings : A Follow-Up
There were a lot of comments following my post last week about string splitting. I think the point of the article was not as obvious as it could have been: that spending a lot of time and effort trying to "perfect" an inherently slow splitting function based on T-SQL would not be beneficial. I have since collected the most recent version of Jeff Moden's string splitting function, and put it up against the others:
ALTER FUNCTION [dbo].[DelimitedSplitN4K]
(@pString NVARCHAR(4000), @pDelimiter NCHAR(1))
RETURNS TABLE WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
cteTally(N) AS (SELECT TOP (ISNULL(DATALENGTH(@pString)/2,0))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4),
cteStart(N1) AS (SELECT 1 UNION ALL
SELECT t.N+1 FROM cteTally t WHERE SUBSTRING(@pString,t.N,1) = @pDelimiter
),
cteLen(N1,L1) AS(SELECT s.N1,
ISNULL(NULLIF(CHARINDEX(@pDelimiter,@pString,s.N1),0)-s.N1,4000)
FROM cteStart s
)
SELECT ItemNumber = ROW_NUMBER() OVER(ORDER BY l.N1),
Item = SUBSTRING(@pString, l.N1, l.L1)
FROM cteLen l;
GO
(The only changes I've made: I've formatted it for display, and I've removed the comments. You can retrieve the original source here.)
I had to make a couple of adjustments to my tests to fairly represent Jeff's function. Most importantly: I had to discard all samples that involved any strings > 4,000 characters. So I changed the 5,000-character strings in the dbo.strings table to be 4,000 characters instead, and focused only on the first three non-MAX scenarios (keeping the previous results for the first two, and running the third tests again for the new 4,000-character string lengths). I also dropped the Numbers table from all but one of the tests, because it was clear that the performance there was always worse by a factor of at least 10. The following chart shows the performance of the functions in each of the four tests, again averaged over 10 runs and always with a cold cache and clean buffers.
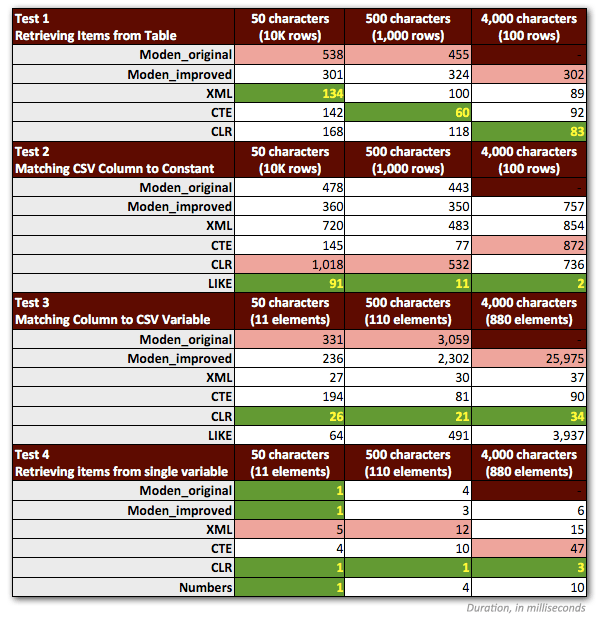
So here are my slightly revised preferred methods, for each type of task:
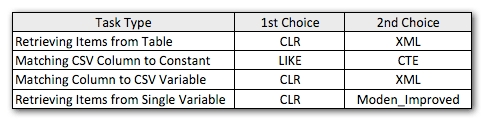
You'll notice that CLR has remained my method of choice, except in the one case where splitting doesn't make sense. And in cases where CLR is not an option, the XML and CTE methods are generally more efficient, except in the case of single variable splitting, where Jeff's function may very well be the best option. But given that I might need to support more than 4,000 characters, the Numbers table solution just might make it back onto my list in specific situations where I'm not allowed to use CLR.
I promise that my next post involving lists will not talk about splitting at all, via T-SQL or CLR, and will demonstrate how to simplify this problem regardless of data type.
http://web.archive.org/web/20150411042510/http://sqlserver2000.databases.aspfaq.com/why-should-i-consider-using-an-auxiliary-numbers-table.html
That article was written by me in 2004. So whoever added the comment to the function, you're welcome. :-)
2 thoughts on “Splitting Strings : A Follow-Up”
Comments are closed.

Thanks for doing this. It is nice to have detailed performance test results, since setting them up and analyzing them can be so time-consuming.
I particularly like how you did real-world actions with the results rather than just testing the whole-task-completion-time.
Aaron said,
>>That article was written by me in 2004. So whoever added the comment to the function, you’re welcome.
In that case, thank you, Aaron. It was I that added that comment. I always wondered who wrote it.