
T-SQL bugs, pitfalls, and best practices – subqueries
This article is the second in a series about T-SQL bugs, pitfalls and best practices. This time I focus on classic bugs involving subqueries. Particularly, I cover substitution errors and three-valued logic troubles. Several of the topics that I cover in the series were suggested by fellow MVPs in a discussion we had on the subject. Thanks to Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man and Paul White for your suggestions!
Substitution error
To demonstrate the classic substitution error, I’ll use a simple customers-orders scenario. Run the following code to create a helper function called GetNums, and to create and populate the Customers and Orders tables:
SET NOCOUNT ON;
USE tempdb;
GO
DROP TABLE IF EXISTS dbo.Orders;
DROP TABLE IF EXISTS dbo.Customers;
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
CREATE TABLE dbo.Customers
(
custid INT NOT NULL
CONSTRAINT PK_Customers PRIMARY KEY,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100);
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
customerid INT NOT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (customerid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_customerid ON dbo.Orders(customerid);
Currently, the Customers table has 100 customers with consecutive customer IDs in the range 1 to 100. 98 of those customers have corresponding orders in the Orders table. Customers with IDs 17 and 59 did not place any orders yet and therefore have no presence in the Orders table.
You’re after only customers who placed orders, and you attempt to achieve this using the following query (call it Query 1):
SET NOCOUNT OFF;
SELECT custid, companyname
FROM dbo.Customers
WHERE custid IN (SELECT custid FROM dbo.Orders);
You’re supposed to get 98 customers back, but instead you get all 100 customers, including those with IDs 17 and 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 17 Cust 17 18 Cust 18 ... 58 Cust 58 59 Cust 59 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (100 rows affected)
Can you figure out what’s wrong?
To add to the confusion, examine the plan for Query 1 as shown in Figure 1.
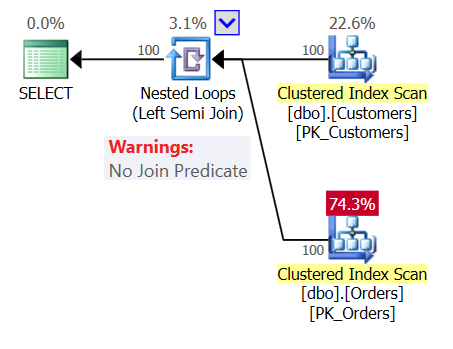 Figure 1: Plan for Query 1
Figure 1: Plan for Query 1
The plan shows a Nested Loops (Left Semi Join) operator with no join predicate, meaning that the only condition for returning a customer is to have a nonempty Orders table, as if the query that you wrote was the following:
SELECT custid, companyname
FROM dbo.Customers
WHERE EXISTS (SELECT * FROM dbo.Orders);
You probably expected a plan similar to the one shown in Figure 2.
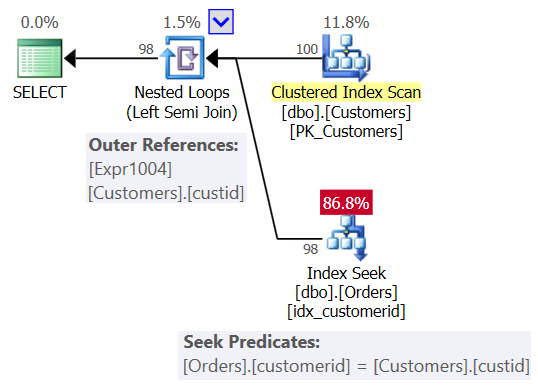 Figure 2: Expected plan for Query 1
Figure 2: Expected plan for Query 1
In this plan you see a Nested Loops (Left Semi Join) operator, with a scan of the clustered index on Customers as the outer input and a seek in the index on the customerid column in the Orders as the inner input. You also see an outer reference (correlated parameter) based on the custid column in Customers, and the seek predicate Orders.customerid = Customers.custid.
So why are you getting the plan in Figure 1 and not the one in Figure 2? If you haven’t figured it out yet, look closely at the definitions of both tables—specifically the column names—and at the column names used in the query. You will notice that the Customers table holds customer IDs in a column called custid, and that the Orders table holds customer IDs in a column called customerid. However, the code uses custid in both the outer and inner queries. Since the reference to custid in the inner query is unqualified, SQL Server has to resolve which table the column is coming from. According to the SQL standard, SQL Server is supposed to look for the column in the table that is queried in the same scope first, but since there’s no column called custid in Orders, it’s then supposed to look for it in the table in the outer scope, and this time there is a match. So unintentionally, the reference to custid becomes implicitly a correlated reference, as if you wrote the following query:
SELECT custid, companyname
FROM dbo.Customers
WHERE custid IN (SELECT Customers.custid FROM dbo.Orders);
Provided that Orders isn’t empty, and that the outer custid value isn’t NULL (can’t be in our case since the column is defined as NOT NULL), you’ll always get a match because you compare the value to itself. So Query 1 becomes the equivalent of:
SELECT custid, companyname
FROM dbo.Customers
WHERE EXISTS (SELECT * FROM dbo.Orders);
If the outer table supported NULLs in the custid column, Query 1 would have been equivalent to:
SELECT custid, companyname
FROM dbo.Customers
WHERE EXISTS (SELECT * FROM dbo.Orders)
AND custid IS NOT NULL;
Now you understand why Query 1 was optimized with the plan in Figure 1, and why you got all 100 customers back.
Some time ago I visited a customer who had a similar bug, but unfortunately with a DELETE statement. Think for a moment what this means. All table rows got wiped out and not just the ones that they originally intended to delete!
As for best practices that can help you avoid such bugs, there are two main ones. First, as much as you can control it, make sure you use consistent column names across tables for attributes that represent the same thing. Second, make sure that you table qualify column references in subqueries, including in self-contained ones where this is not a common practice. Of course, you can use table alias if you’d rather not use full table names. Applying this practice to our query, suppose that your initial attempt used the following code:
SELECT custid, companyname
FROM dbo.Customers
WHERE custid IN (SELECT O.custid FROM dbo.Orders AS O);
Here you’re not allowing implicit column name resolution and therefore SQL Server generates the following error:
Msg 207, Level 16, State 1, Line 108 Invalid column name 'custid'.
You go and check the metadata for the Orders table, realize that you used the wrong column name, and fix the query (call this Query 2), like so:
SELECT custid, companyname
FROM dbo.Customers
WHERE custid IN (SELECT O.customerid FROM dbo.Orders AS O);
This time you get the right output with 98 customers, excluding the customers with IDs 17 and 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 18 Cust 18 .. 58 Cust 58 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (98 rows affected)
You also get the expected plan shown earlier in Figure 2.
As an aside, it’s clear why Customers.custid is an outer reference (correlated parameter) in the Nested Loops (Left Semi Join) operator in Figure 2. What’s less obvious is why Expr1004 appears in the plan as an outer reference as well. Fellow SQL Server MVP Paul White theorizes that it could be related to using information from the outer input’s leaf to hint the storage engine to avoid duplicated effort by the read-ahead mechanisms. You can find the details here.
Three-valued logic trouble
A common bug involving subqueries has to do with cases where the outer query uses the NOT IN predicate and the subquery can potentially return NULLs among its values. For example, suppose that you need to be able to store orders in our Orders table with a NULL as the customer ID. Such a case would represent an order that is not associated with any customer; for instance, an order that compensates for inconsistencies between actual product counts and counts recorded in the database.
Use the following code to recreate the Orders table with the custid column allowing NULLs, and for now populate it with the same sample data like before (with orders by customer IDs 1 to 100, excluding 17 and 59):
DROP TABLE IF EXISTS dbo.Orders;
GO
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
custid INT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (custid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_custid ON dbo.Orders(custid);
Notice that while we’re at it, I followed the best practice discussed in the previous section to use consistent column names across tables for the same attributes, and named the column in the Orders table custid just like in the Customers table.
Suppose that you need to write a query that returns customers who didn’t place orders. You come up with the following simplistic solution using the NOT IN predicate (call it Query 3, first execution):
SELECT custid, companyname
FROM dbo.Customers
WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
This query returns the expected output with customers 17 and 59:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
An inventory is done in the company’s warehouse, and an inconsistency is found between the actual quantity of some product and the quantity recorded in the database. So, you add a dummy compensating order to account for the inconsistency. Since there’s no actual customer associated with the order, you use a NULL as the customer ID. Run the following code to add such an order header:
INSERT INTO dbo.Orders(custid) VALUES(NULL);
Run Query 3 for the second time:
SELECT custid, companyname
FROM dbo.Customers
WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
This time, you get an empty result:
custid companyname ------- ------------ (0 rows affected)
Clearly, something’s wrong. You know that customers 17 and 59 didn’t place any orders, and indeed they appear in the Customers table but not in the Orders table. Yet the query result claims that there’s no customer who did not place any orders. Can you figure out where’s the bug and how to fix it?
The bug has to do with the NULL in the Orders table, of course. To SQL a NULL is a marker for a missing value that could represent an applicable customer. SQL doesn’t know that to us the NULL represents a missing and inapplicable (irrelevant) customer. For all customers in the Customers table that are present in the Orders table, the IN predicate finds a match yielding TRUE and the NOT IN part makes it a FALSE, therefore the customer row is discarded. So far, so good. But for customers 17 and 59, the IN predicate yields UNKNOWN since all comparisons with non-NULL values yield FALSE, and the comparison with the NULL yields UNKNOWN. Remember, SQL assumes that the NULL could represent any applicable customer, so the logical value UNKNOWN indicates that it’s unknown whether the outer customer ID is equal to the inner NULL customer ID. FALSE OR FALSE … OR UNKNOWN is UNKNOWN. Then the NOT IN part applied to UNKNOWN still yields UNKNOWN.
In simpler English terms, you asked to return customers who didn’t place orders. So naturally, the query discards all customers from the Customers table that are present in the Orders table because it is known with certainty that they placed orders. As for the rest (17 and 59 in our case) the query discards them since to SQL, just like it’s unknown whether they placed orders, it’s just as unknown whether they didn’t place orders, and the filter needs certainty (TRUE) in order to return a row. What a pickle!
So as soon as the first NULL gets into the Orders table, from that moment you always get an empty result back from the NOT IN query. What about cases where you don’t actually have NULLs in the data, but the column allows NULLs? As you saw in the first execution of Query 3, in such a case you do get the correct result. Perhaps you’re thinking that the application will never introduce NULLs into the data, so there’s nothing for you to worry about. That’s a bad practice for a couple of reasons. For one, if a column is defined as allowing NULLs, it’s pretty much a certainty the NULLs will eventually get there even if they are not supposed to; it’s just a matter of time. It could be the result of importing bad data, a bug in the application, and other reasons. For another, even if the data doesn’t contain NULLs, if the column allows those, the optimizer has to account for the possibility that NULLs will be present when it creates the query plan, and in our NOT IN query this incurs a performance penalty. To demonstrate this, consider the plan for the first execution of Query 3 before you added the row with the NULL, as shown in Figure 3.
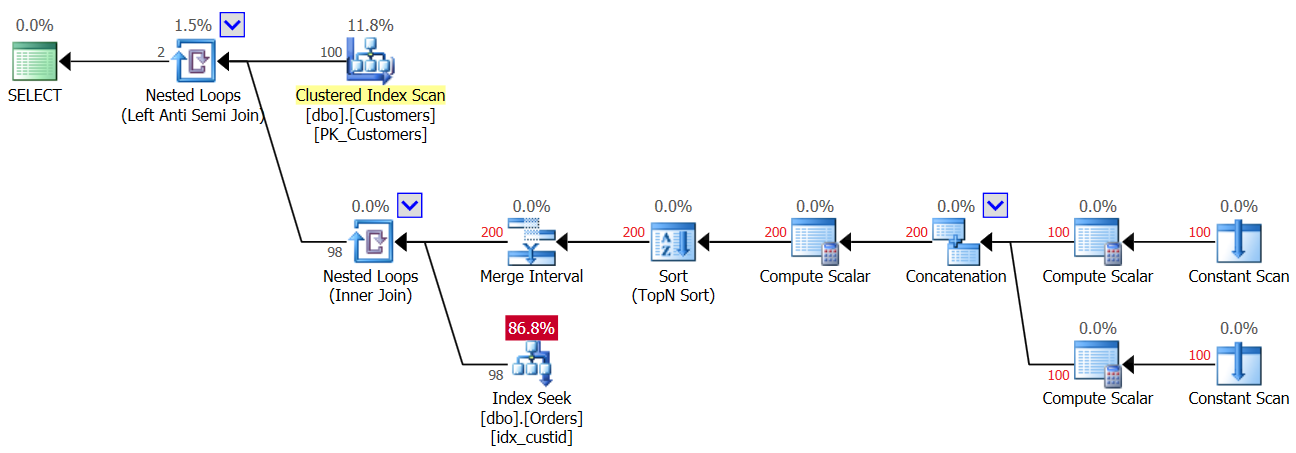 Figure 3: Plan for first execution of Query 3
Figure 3: Plan for first execution of Query 3
The top Nested Loops operator handles the Left Anti Semi Join logic. That’s essentially about identifying nonmatches, and short circuiting the inner activity as soon as a match is found. The outer part of the loop pulls all 100 customers from the Customers table, hence the inner part of the loop gets executed 100 times.
The inner part of the top loop executes a Nested Loops (Inner Join) operator. The outer part of the bottom loop creates two rows per customer—one for a NULL case and another for the current customer ID, in this order. Don’t let the Merge Interval operator confuse you. It’s normally used to merge overlapping intervals, e.g., a predicate such as col1 BETWEEN 20 AND 30 OR col1 BETWEEN 25 AND 35 gets converted to col1 BETWEEN 20 AND 35. This idea can be generalized to remove duplicates in an IN predicate. In our case, there cannot really be any duplicates. In simplified terms, as mentioned, think of the outer part of the loop as creating two rows per customer—the first for a NULL case, and the second for the current customer ID. Then the inner part of the loop first does a seek in the index idx_custid on Orders to look for a NULL. If a NULL is found, it doesn’t activate the second seek for the current customer ID (remember the short circuit handled by the top Anti Semi Join loop). In such a case, the outer customer is discarded. But if a NULL isn’t found, the bottom loop activates a second seek to look for the current customer ID in Orders. If it’s found, the outer customer is discarded. If it’s not found, the outer customer is returned. What this means is that when NULLs are not present in Orders, this plan performs two seeks per customer! This can be observed in the plan as the number of rows 200 in the outer input of the bottom loop. Consequentially, here are the I/O stats that are reported for the first execution:
Table 'Orders'. Scan count 200, logical reads 603
The plan for the second execution of Query 3, after a row with a NULL was added to the Orders table, is shown in Figure 4.
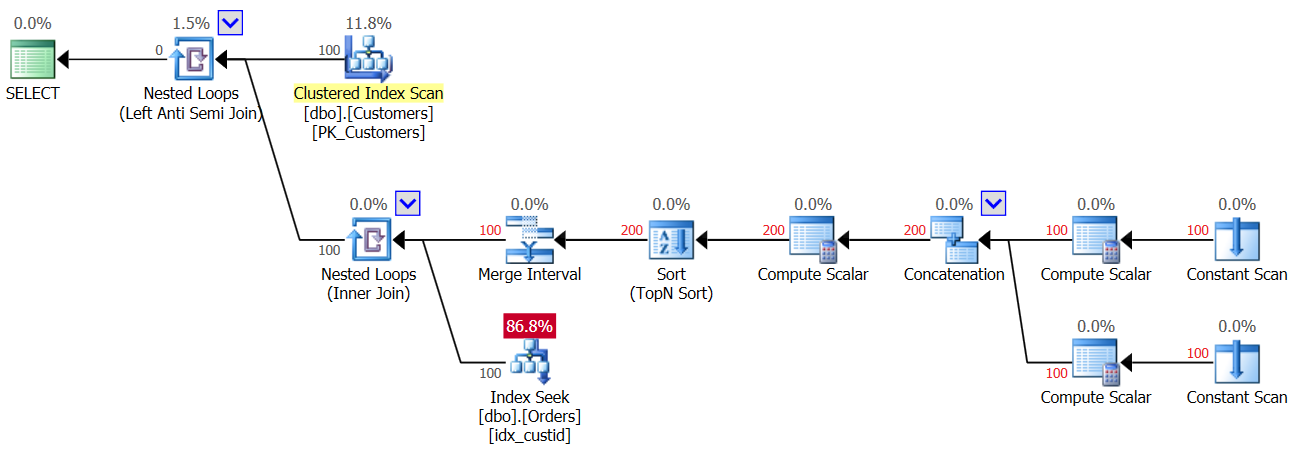 Figure 4: Plan for second execution of Query 3
Figure 4: Plan for second execution of Query 3
Since a NULL is present in the table, for all customers, the first execution of the Index Seek operator finds a match, and hence all customers get discarded. So yay, we do only one seek per customer and not two, so this time you get 100 seeks and not 200; however, at the same time this means that you’re getting back an empty result!
Here are the I/O stats that are reported for the second execution:
Table 'Orders'. Scan count 100, logical reads 300
One solution to this task when NULLs are possible among the returned values in the subquery is to simply filter those out, like so (call it Solution 1/Query 4):
SELECT custid, companyname
FROM dbo.Customers
WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O WHERE O.custid IS NOT NULL);
This code generates the expected output:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
The downside of this solution is that you need to remember to add the filter. I prefer a solution using the NOT EXISTS predicate, where the subquery has an explicit correlation comparing the order’s customer ID with the customer’s customer ID, like so (call it Solution 2/Query 5):
SELECT C.custid, C.companyname
FROM dbo.Customers AS C
WHERE NOT EXISTS (SELECT * FROM dbo.Orders AS O WHERE O.custid = C.custid);
Remember that an equality-based comparison between a NULL and anything yields UNKNOWN, and UNKNOWN gets discarded by a WHERE filter. So if NULLs exist in Orders, they get eliminated by the inner query’s filter without you needing to add explicit NULL treatment, and hence you don’t need to worry about whether NULLs do or do not exist in the data.
This query generates the expected output:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
The plans for both solutions are shown in Figure 5.
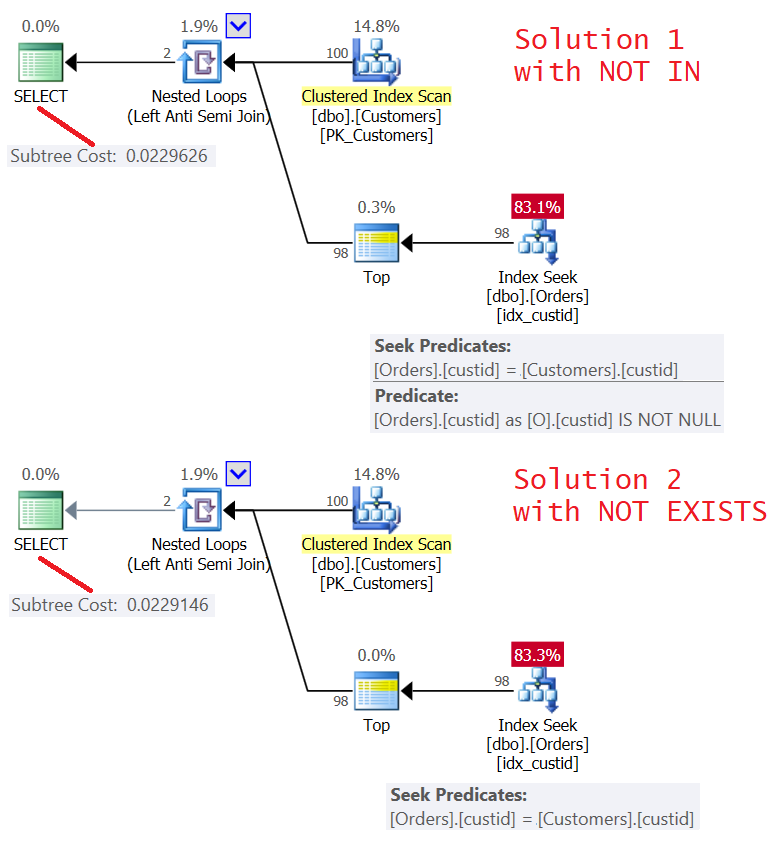 Figure 5: Plans for Query 4 (Solution 1) and Query 5 (Solution 2)
Figure 5: Plans for Query 4 (Solution 1) and Query 5 (Solution 2)
As you can see the plans are almost identical. They’re also quite efficient, using a Left Semi Join optimization with a short-circuit. Both perform only 100 seeks in the index idx_custid on Orders, and with the Top operator, apply a short circuit after one row is touched in the leaf.
The I/O stats for both queries is the same:
Table 'Orders'. Scan count 100, logical reads 348
One thing to consider though is whether there’s any chance for the outer table to have NULLs in the correlated column (custid in our case). Very unlikely to be relevant in a scenario like customers-orders, but could be relevant in other scenarios. If indeed that’s the case, both solutions handle an outer NULL incorrectly.
To demonstrate this, drop and recreate the Customers table with a NULL as one of the customer IDs by running the following code:
DROP TABLE IF EXISTS dbo.Customers;
GO
CREATE TABLE dbo.Customers
(
custid INT NULL
CONSTRAINT UNQ_Customers_custid UNIQUE CLUSTERED,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT CAST(NULL AS INT) AS custid, 'Cust NULL' AS companyname
UNION ALL
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100);
Solution 1 will not return an outer NULL irrespective of whether an inner NULL is present or not.
Solution 2 will return an outer NULL irrespective of whether an inner NULL is present or not.
If you wish to handle NULLs like you handle non-NULL values, i.e., return the NULL if present in Customers but not in Orders, and don’t return it if present in both, you need to change the solution’s logic to use a distinctness-based comparison instead of an equality-based comparison. This can be achieved by combining the EXISTS predicate and the EXCEPT set operator, like so (call this Solution 3/Query 6):
SELECT C.custid, C.companyname
FROM dbo.Customers AS C
WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Since currently there are NULLs in both Customers and Orders, this query correctly doesn’t return the NULL. Here’s the query output:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Run the following code to remove the row with the NULL from the Orders table and rerun Solution 3:
DELETE FROM dbo.Orders WHERE custid IS NULL;
SELECT C.custid, C.companyname
FROM dbo.Customers AS C
WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
This time, since a NULL is present in Customers but not in Orders, the result includes the NULL:
custid companyname ------- ------------ NULL Cust NULL 17 Cust 17 59 Cust 59 (3 rows affected)
The plan for this solution is shown in Figure 6:
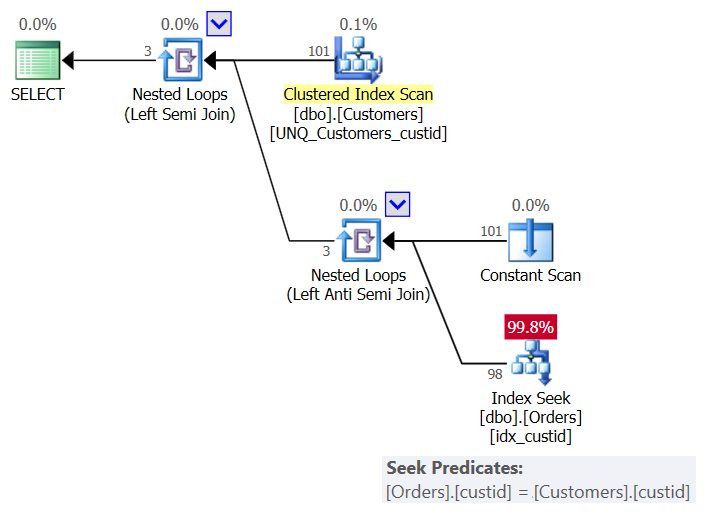 Figure 6: Plan for Query 6 (Solution 3)
Figure 6: Plan for Query 6 (Solution 3)
Per customer, the plan uses a Constant Scan operator to create a row with the current customer, and applies a single seek in the index idx_custid on Orders to check whether the customer exists in Orders. You end up with one seek per customer. Since we currently have 101 customers in the table, we get 101 seeks.
Here are the I/O stats for this query:
Table 'Orders'. Scan count 101, logical reads 415
Conclusion
This month I covered subquery-related bugs, pitfalls and best practices. I covered substitution errors and three-valued logic troubles. Remember to use consistent column names across tables, and to always table qualify columns in subqueries, even when they are self-contained ones. Also remember to enforce a NOT NULL constraint when the column isn’t supposed to allow NULLs, and to always take NULLs into account when they are possible in your data. Make sure that you include NULLs in your sample data when they are allowed so that you can more easily catch bugs in your code when testing it. Be careful with the NOT IN predicate when combined with subqueries. If NULLs are possible in the inner query’s result, the NOT EXISTS predicate is usually the preferred alternative.