
Scalar UDF Inlining in SQL Server 2019
Scalar UDFs have always been a double-edged sword – they’re great for developers, who get to abstract away tedious logic instead of repeating it all over their queries, but they’re horrible for runtime performance in production, because the optimizer doesn’t handle them nicely. Essentially what happens is the UDF executions are kept separate from the rest of the execution plan, and so they get called once for every row and can’t be optimized based on estimated or actual number of rows or folded into the rest of the plan.
Since, in spite of our best efforts since SQL Server 2000, we can’t effectively stop scalar UDFs from being used, wouldn’t it be great to make SQL Server simply handle them better?
SQL Server 2019 introduces a new feature called Scalar UDF Inlining. Instead of keeping the function separate, it is incorporated into the overall plan. This leads to a much better execution plan and, in turn, better runtime performance.
But first, to better illustrate the source of the problem, let’s start with a pair of simple tables with just a few rows, in a database running on SQL Server 2017 (or on 2019 but with a lower compatibility level):
CREATE DATABASE Whatever;
GO
ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 140;
GO
USE Whatever;
GO
CREATE TABLE dbo.Languages
(
LanguageID int PRIMARY KEY,
Name sysname
);
CREATE TABLE dbo.Employees
(
EmployeeID int PRIMARY KEY,
LanguageID int NOT NULL FOREIGN KEY REFERENCES dbo.Languages(LanguageID)
);
INSERT dbo.Languages(LanguageID, Name) VALUES(1033, N'English'), (45555, N'Klingon');
INSERT dbo.Employees(EmployeeID, LanguageID)
SELECT [object_id], CASE ABS([object_id]%2) WHEN 1 THEN 1033 ELSE 45555 END
FROM sys.all_objects;Now, we have a simple query where we want to show each employee and the name of their primary language. Let’s say this query is used in a lot of places and/or in different ways so, instead of building a join into the query, we write a scalar UDF to abstract away that join:
CREATE FUNCTION dbo.GetLanguage(@id int)
RETURNS sysname
AS
BEGIN
RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id);
ENDThen our actual query looks something like this:
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID)
FROM dbo.Employees;If we look at the execution plan for the query, something is oddly missing:
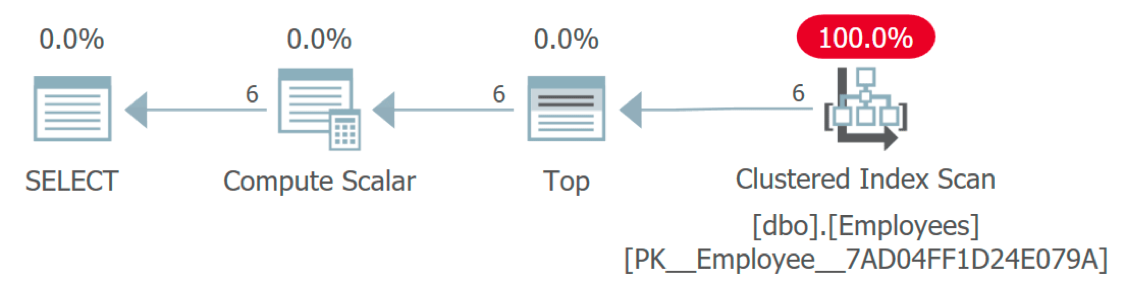 Execution plan showing access to Employees but not to Languages
Execution plan showing access to Employees but not to Languages
How is the Languages table accessed? This plan looks very efficient because – like the function itself – it is abstracting away some of the complexity involved. In fact, this graphical plan is identical to a query that just assigns a constant or variable to the Language column:
SELECT TOP (6) EmployeeID, Language = N'Sanskrit'
FROM dbo.Employees;But if you run a trace against the original query, you will see that there are actually six calls to the function (one for each row) in addition to the main query, but these plans are not returned by SQL Server.
You can also verify this by checking sys.dm_exec_function_stats, but this is not a guarantee:
SELECT [function] = OBJECT_NAME([object_id]), execution_count
FROM sys.dm_exec_function_stats
WHERE object_name(object_id) IS NOT NULL;function execution_count ----------- --------------- GetLanguage 6
SentryOne Plan Explorer will show the statements if you generate an actual plan from within the product, but we can only obtain those from trace, and there are still no plans collected or shown for the individual function calls:
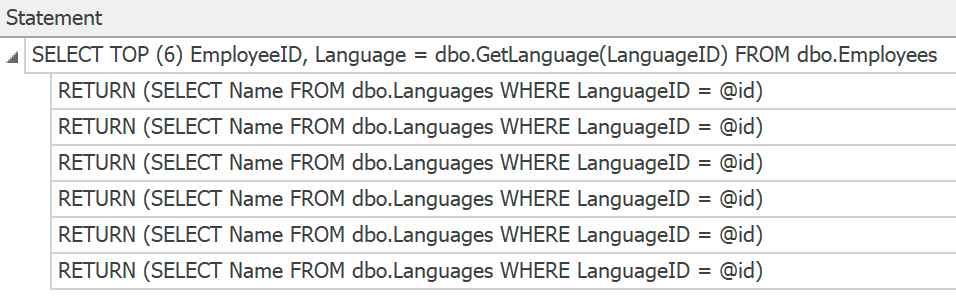 Trace statements for individual scalar UDF invocations
Trace statements for individual scalar UDF invocations
This all makes them very difficult to troubleshoot, because you have to go hunt them down, even when you already know they’re there. It can also make a real mess of performance analysis if you’re comparing two plans based on things like estimated costs, because not only are the relevant operators hiding from the physical diagram, the costs aren’t incorporated anywhere in the plan either.
Fast Forward to SQL Server 2019
After all these years of problematic behavior and obscure root causes, they’ve made it so that some functions can be optimized into the overall execution plan. Scalar UDF Inlining makes the objects they access visible for troubleshooting *and* allows them to be folded into the execution plan strategy. Now cardinality estimates (based on statistics) allow for join strategies that simply weren’t possible when the function was called once for every row.
We can use the same example as above, either create the same set of objects on a SQL Server 2019 database, or scrub the plan cache and up the compatibility level to 150:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE;
GO
ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 150;
GONow when we run our six-row query again:
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID)
FROM dbo.Employees;We get a plan that includes the Languages table and the costs associated with accessing it:
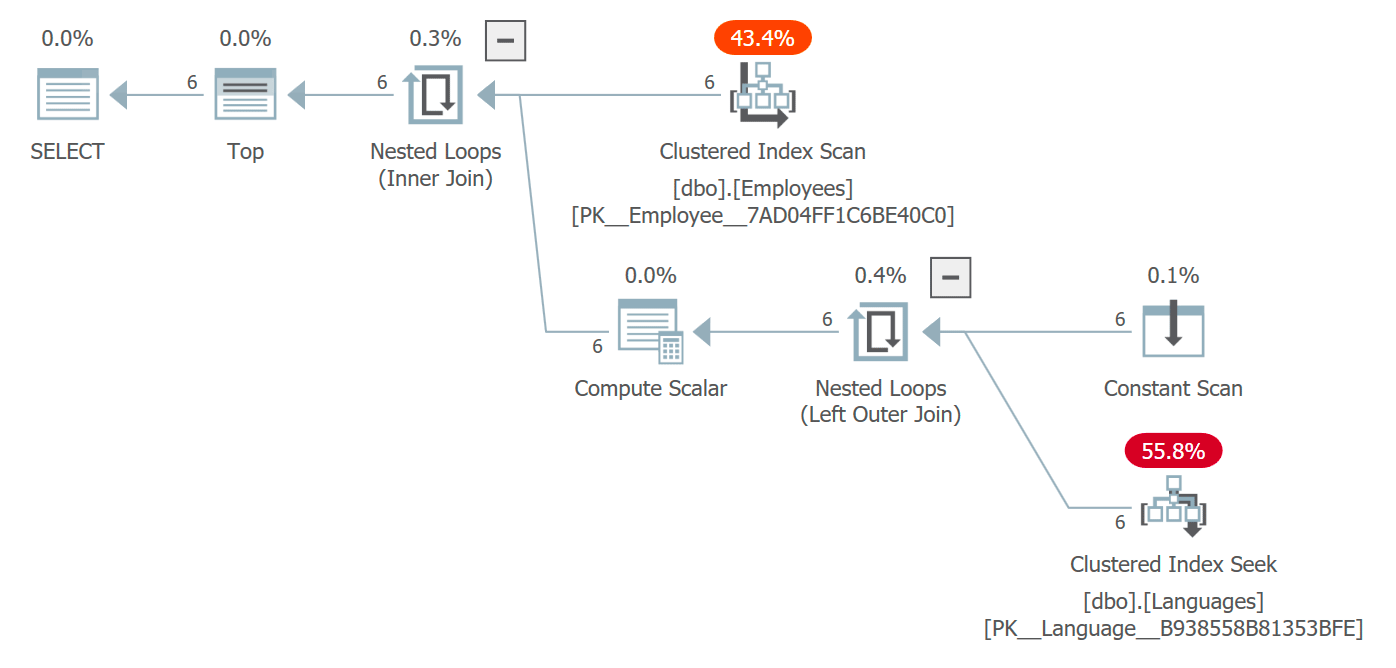 Plan that includes access to objects referenced inside scalar UDF
Plan that includes access to objects referenced inside scalar UDF
Here the optimizer chose a nested loops join but, under different circumstances, it could have chosen a different join strategy, comtemplated parallelism, and been essentially free to completely change the plan shape. You aren’t likely to see this in a query that returns 6 rows and isn’t a performance issue in any way, but at larger scales it could.
The plan reflects that the function isn’t being called per row – while the seek is actually executed six times, you can see that the function itself no longer shows up in sys.dm_exec_function_stats. One downside that you can take away is that, if you use this DMV to determine whether a function is actively being used (as we often do for procedures and indexes), that will no longer be reliable.
Caveats
Not every scalar function is inlineable and, even when a function *is* inlineable, it won’t necessarily be inlined in every scenario. This often has to do with either the complexity of the function, the complexity of the query involved, or the combination of both. You can check whether a function is inlineable in the sys.sql_modules catalog view:
SELECT OBJECT_NAME([object_id]), definition, is_inlineable
FROM sys.sql_modules;And if, for whatever reason, you don’t want a certain function (or any function in a database) to be inlined, you don’t have to rely on the compatibility level of the database to control that behavior. I’ve never liked that loose coupling, which is akin to switching rooms to watch a different television show instead of simply changing the channel. You can control this at the module level using the INLINE option:
ALTER FUNCTION dbo.GetLanguage(@id int)
RETURNS sysname
WITH INLINE = OFF
AS
BEGIN
RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id);
END
GOAnd you can control this at the database level, but separate from compatibility level:
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = OFF;Though you’d have to have a pretty good use case to swing that hammer, IMHO.
Conclusion
Now, I am not suggesting you can go and abstract every piece of logic away into a scalar UDF, and assume that now SQL Server will just take care of all cases. If you have a database with a lot of scalar UDF usage, you should download the latest SQL Server 2019 CTP, restore a backup of your database there, and check the DMV to see how many of those functions will be inlineable when the time comes. It could be a major bullet point the next time you’re arguing for an upgrade, since you'll essentially get all that performance and wasted troubleshooting time back.
In the meantime, if you are suffering from scalar UDF performance and you won't be upgrading to SQL Server 2019 any time soon, there may be other ways to help mitigate the issue(s).
Note: I wrote and queued up this article before I realized I had already posted a different piece elsewhere.
6 thoughts on “Scalar UDF Inlining in SQL Server 2019”
Comments are closed.

I've done some quick tests on my database. And I must say I'm pretty disappointed. All of my arbitrary queries took much longer on 2019 CTP 2.2, with compatibility set and testing functions that have the inline flag set to 1, than on 2017.
Not the result I hoped for.
Hugo, did you inspect the plans and confirm that the UDF was actually inlined for your query? Inlineable = 1 does not guarantee that inlining actually happens.
Currently, there is no DMV/DMF to show which scalar-UDFs are getting automatically inlined. You can query sys.dm_exec_function_stats to see which scalar UDFs are still being executed. After you switch to database compatibility level 150, the scalar UDFs that got automatically inlined will no longer show up in that DMV. It is a little unwieldy.
I have asked Microsoft to expose which scalar UDFs are getting automatically inlined to make it easier to see what is happening.
Hi Aaron,
Thanks for your answer and sorry for replying so late. I checked the notify checkbox, but I wasn't notified, or maybe the notification mail ended in my spambox.
Anyway. I think the UDF was inlined. I set statistics on and noticed all tables that the UDF is using. I'm not seeing those tables when compatibility is set to SQL Server 2017.
SQL Server 2017
scans: 1
logical reads: 305
physical reads: 2
read-ahead reads: 624
CPU time = 625 ms, elapsed time = 1242 ms.
SQL Server 2019
scans: 8,763
logical reads: 539,757
physical reads: 117
read-ahead reads: 1,539
CPU time = 17328 ms, elapsed time = 17852 ms.
I don't know, I could start guessing what's going on here, but I think you have more answers than I could stab at. The slower version of your query is worse, and it is definitely the victim of *something*, but I do not believe scalar UDF inlining that something. Did you try a recompile? Did you compare plans? Do they actually return the same number of rows? Did you try multiple times to eliminate caching and other factors? Another important point is that this is a beta – it's possible there will be enhancements in both functionality and diagnostics before we get to final release.
Hi Aaron,
This is my test query:
DBCC DROPCLEANBUFFERS ;
DBCC FREEPROCCACHE ;
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE;
GO
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
— SQL SERVER 2019
ALTER DATABASE MaxCCDev SET COMPATIBILITY_LEVEL = 150; — 140 = 2017, 150 = 2019
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = ON;
/*
*/
— SQL SERVER 2017
/*
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = OFF;
ALTER DATABASE MaxCCDev SET COMPATIBILITY_LEVEL = 140; — 140 = 2017, 150 = 2019
*/
GO
/*
SELECT OBJECT_NAME([object_id]) Name, definition, is_inlineable
FROM sys.sql_modules
WHERE OBJECT_NAME([object_id]) = 'fEmployeesWithoutCommRate';
*/
SELECT @@VERSION;
DECLARE @LicenseId UNIQUEIDENTIFIER = '9aaae80e-7d30-4afb-8669-34b7dcacc711'; — Arcencus
DECLARE @UserId UNIQUEIDENTIFIER = '14989132-2AB0-4465-9F4C-D8109A01DEE1'; — Hugo
— Complexe function
SELECT a.Title Administration, dbo.fEmployeesWithoutCommRate(a.DataObjectId, @LicenseId, @UserId, '20180101', '20181231') EmployeesWithoutCommercialRate
FROM tblAdministration a
JOIN tblDataObject do ON do.guid = a.DataObjectId
WHERE do.LicenseId = @LicenseId
ORDER BY 1
I know the tables and functions don't mean anything to you…
But the results are the same. Also, when I'm querying in 2019 compatibility mode and I switch inlining off, the query performs as fast as when querying in 2017 mode.
It's indeed very well possible it's a beta-related thing. I'll test again when there is a new CTP available.
I put the plans on my drop box:
https://www.dropbox.com/s/31kys3i20pqo24x/Plan%20Inlining%20OFF.xml?dl=0
and
https://www.dropbox.com/s/r3u5hdyz9u0q7dq/Plan%20Inlining%20ON.xml?dl=0
Although the plan with inlining OFF doesn't give much info.