
Compression and its Effects on Performance
One of the many new features introduced back in SQL Server 2008 was Data Compression. Compression at either the row or page level provides an opportunity to save disk space, with the trade off of requiring a bit more CPU to compress and decompress the data. It's frequently argued that the majority of systems are IO-bound, not CPU-bound, so the trade off is worth it. The catch? You had to be on Enterprise Edition to use Data Compression. With the release of SQL Server 2016 SP1, that has changed! If you're running Standard Edition of SQL Server 2016 SP1 and higher, you can now use Data Compression. There's also a new built-in function for compression, COMPRESS (and its counterpart DECOMPRESS). Data Compression does not work on off-row data, so if you have a column like NVARCHAR(MAX) in your table with values typically more than 8000 bytes in size, that data won't be compressed (thanks Adam Machanic for that reminder). The COMPRESS function solves this problem, and compresses data up to 2GB in size. Moreover, while I'd argue that the function should only be used for large, off-row data, I thought comparing it directly against row and page compression was a worthwhile experiment.
SETUP
For test data, I'm working from a script Aaron Bertrand has used previously, but I've made some tweaks. I created a separate database for testing but you can use tempdb or another sample database, and then I started with a Customers table that has three NVARCHAR columns. I considered creating larger columns and populating them with strings of repeating letters, but using readable text gives a sample that's more realistic and thus provides greater accuracy.
Note: If you're interested in implementing compression and want to know how it will affect storage and performance in your environment, I HIGHLY RECOMMEND THAT YOU TEST IT. I'm giving you the methodology with sample data; implementing this in your environment shouldn't involve additional work.
You'll note below that after creating the database we're enabling Query Store. Why create a separate table to try and track our performance metrics when we can just use functionality built-in to SQL Server?!
USE [master];
GO
CREATE DATABASE [CustomerDB]
CONTAINMENT = NONE
ON PRIMARY
(
NAME = N'CustomerDB', FILENAME = N'C:\Databases\CustomerDB.mdf' ,
SIZE = 4096MB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB
)
LOG ON
(
NAME = N'CustomerDB_log', FILENAME = N'C:\Databases\CustomerDB_log.ldf' ,
SIZE = 2048MB , MAXSIZE = UNLIMITED , FILEGROWTH = 65536KB
);
GO
ALTER DATABASE [CustomerDB] SET COMPATIBILITY_LEVEL = 130;
GO
ALTER DATABASE [CustomerDB] SET RECOVERY SIMPLE;
GO
ALTER DATABASE [CustomerDB] SET QUERY_STORE = ON;
GO
ALTER DATABASE [CustomerDB] SET QUERY_STORE
(
OPERATION_MODE = READ_WRITE,
CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30),
DATA_FLUSH_INTERVAL_SECONDS = 60,
INTERVAL_LENGTH_MINUTES = 5,
MAX_STORAGE_SIZE_MB = 256,
QUERY_CAPTURE_MODE = ALL,
SIZE_BASED_CLEANUP_MODE = AUTO,
MAX_PLANS_PER_QUERY = 200
);
GO
Now we'll set up some things inside the database:
USE [CustomerDB];
GO
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0;
GO
-- note: I removed the unique index on [Email] that was in Aaron's version
CREATE TABLE [dbo].[Customers]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID])
);
GO
CREATE NONCLUSTERED INDEX [Active_Customers]
ON [dbo].[Customers]([FirstName],[LastName],[EMail])
WHERE ([Active]=1);
GO
CREATE NONCLUSTERED INDEX [PhoneBook_Customers]
ON [dbo].[Customers]([LastName],[FirstName])
INCLUDE ([EMail]);
With the table created, we'll add some data, but we're adding 5 million rows instead of 1 million. This takes about eight minutes to run on my laptop.
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (5000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (20000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name + c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn;
GO
Now we'll create three more tables: one for row compression, one for page compression, and one for the COMPRESS function. Note that with the COMPRESS function, you must create the columns as VARBINARY data types. As a result, there are no nonclustered indexes on the table (as you cannot create an index key on a varbinary column).
CREATE TABLE [dbo].[Customers_Page]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_Customers_Page] PRIMARY KEY CLUSTERED ([CustomerID])
);
GO
CREATE NONCLUSTERED INDEX [Active_Customers_Page]
ON [dbo].[Customers_Page]([FirstName],[LastName],[EMail])
WHERE ([Active]=1);
GO
CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Page]
ON [dbo].[Customers_Page]([LastName],[FirstName])
INCLUDE ([EMail]);
GO
CREATE TABLE [dbo].[Customers_Row]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_Customers_Row] PRIMARY KEY CLUSTERED ([CustomerID])
);
GO
CREATE NONCLUSTERED INDEX [Active_Customers_Row]
ON [dbo].[Customers_Row]([FirstName],[LastName],[EMail])
WHERE ([Active]=1);
GO
CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Row]
ON [dbo].[Customers_Row]([LastName],[FirstName])
INCLUDE ([EMail]);
GO
CREATE TABLE [dbo].[Customers_Compress]
(
[CustomerID] [int] NOT NULL,
[FirstName] [varbinary](max) NOT NULL,
[LastName] [varbinary](max) NOT NULL,
[EMail] [varbinary](max) NOT NULL,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_Customers_Compress] PRIMARY KEY CLUSTERED ([CustomerID])
);
GO
Next we'll copy the data from [dbo].[Customers] to the other three tables. This is a straight INSERT for our page and row tables and takes about two to three minutes for each INSERT, but there's a scalability issue with the COMPRESS function: trying to insert 5 million rows in one fell swoop just isn't reasonable. The script below inserts rows in batches of 50,000, and only inserts 1 million rows instead of 5 million. I know, that means we're not truly apples-to-apples here for comparison, but I'm ok with that. Inserting 1 million rows takes 10 minutes on my machine; feel free to tweak the script and insert 5 million rows for your own tests.
INSERT dbo.Customers_Page WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT CustomerID, FirstName, LastName, EMail, [Active]
FROM dbo.Customers;
GO
INSERT dbo.Customers_Row WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT CustomerID, FirstName, LastName, EMail, [Active]
FROM dbo.Customers;
GO
SET NOCOUNT ON
DECLARE @StartID INT = 1
DECLARE @EndID INT = 50000
DECLARE @Increment INT = 50000
DECLARE @IDMax INT = 1000000
WHILE @StartID < @IDMax
BEGIN
INSERT dbo.Customers_Compress WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active])
SELECT top 100000 CustomerID, COMPRESS(FirstName), COMPRESS(LastName), COMPRESS(EMail), [Active]
FROM dbo.Customers
WHERE [CustomerID] BETWEEN @StartID AND @EndID;
SET @StartID = @StartID + @Increment;
SET @EndID = @EndID + @Increment;
END
With all our tables populated, we can do a check of size. At this point, we have not implemented ROW or PAGE compression, but the COMPRESS function has been used:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows],
(8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc]
FROM [sys].[allocation_units] [au]
JOIN [sys].[partitions] [p]
ON [au].[container_id] = [p].[partition_id]
JOIN [sys].[objects] [o]
ON [p].[object_id] = [o].[object_id]
JOIN [sys].[indexes] [i]
ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id]
WHERE [o].[is_ms_shipped] = 0
GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc]
ORDER BY [o].[name], [i].[index_id];
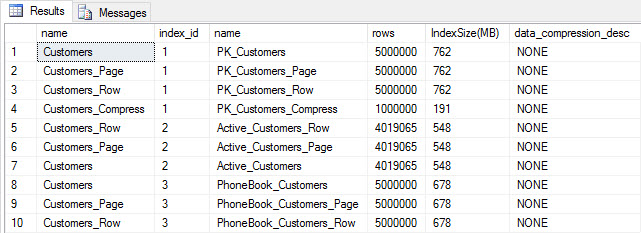 Table and index size after insert
Table and index size after insert
As expected, all tables except Customers_Compress are about the same size. Now we'll rebuild indexes on all tables, implementing row and page compression on Customers_Row and Customers_Page, respectively.
ALTER INDEX ALL ON dbo.Customers REBUILD;
GO
ALTER INDEX ALL ON dbo.Customers_Page REBUILD WITH (DATA_COMPRESSION = PAGE);
GO
ALTER INDEX ALL ON dbo.Customers_Row REBUILD WITH (DATA_COMPRESSION = ROW);
GO
ALTER INDEX ALL ON dbo.Customers_Compress REBUILD;
If we check table size after compression, now we can see our disk space savings:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows],
(8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc]
FROM [sys].[allocation_units] [au]
JOIN [sys].[partitions] [p]
ON [au].[container_id] = [p].[partition_id]
JOIN [sys].[objects] [o]
ON [p].[object_id] = [o].[object_id]
JOIN [sys].[indexes] [i]
ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id]
WHERE [o].[is_ms_shipped] = 0
GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc]
ORDER BY [i].[index_id], [IndexSize(MB)] DESC;
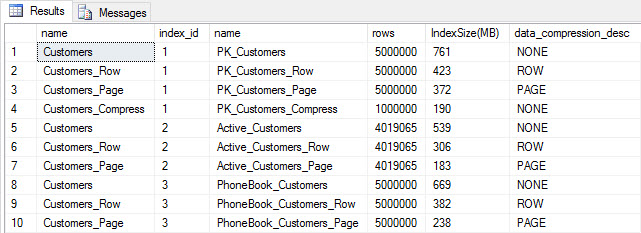
 Index size after compression
Index size after compression
As expected, the row and page compression significantly decreases the size of the table and its indexes. The COMPRESS function saved us the most space - the clustered index is one quarter the size of the original table.
EXAMINING QUERY PERFORMANCE
Before we test query performance, note that we can use Query Store to look at INSERT and REBUILD performance:
SELECT [q].[query_id], [qt].[query_sql_text],
SUM([rs].[count_executions]) [ExecutionCount], AVG([rs].[avg_duration])/1000 [AvgDuration_ms],
AVG([rs].[avg_cpu_time]) [AvgCPU], AVG([rs].[avg_logical_io_reads]) [AvgLogicalReads],
AVG([rs].[avg_physical_io_reads]) [AvgPhysicalReads]
FROM [sys].[query_store_query] [q]
JOIN [sys].[query_store_query_text] [qt]
ON [q].[query_text_id] = [qt].[query_text_id]
LEFT OUTER JOIN [sys].[objects] [o]
ON [q].[object_id] = [o].[object_id]
JOIN [sys].[query_store_plan] [p]
ON [q].[query_id] = [p].[query_id]
JOIN [sys].[query_store_runtime_stats] [rs]
ON [p].[plan_id] = [rs].[plan_id]
WHERE [qt].[query_sql_text] LIKE '%INSERT%'
OR [qt].[query_sql_text] LIKE '%ALTER%'
GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id]
ORDER BY [q].[query_id];
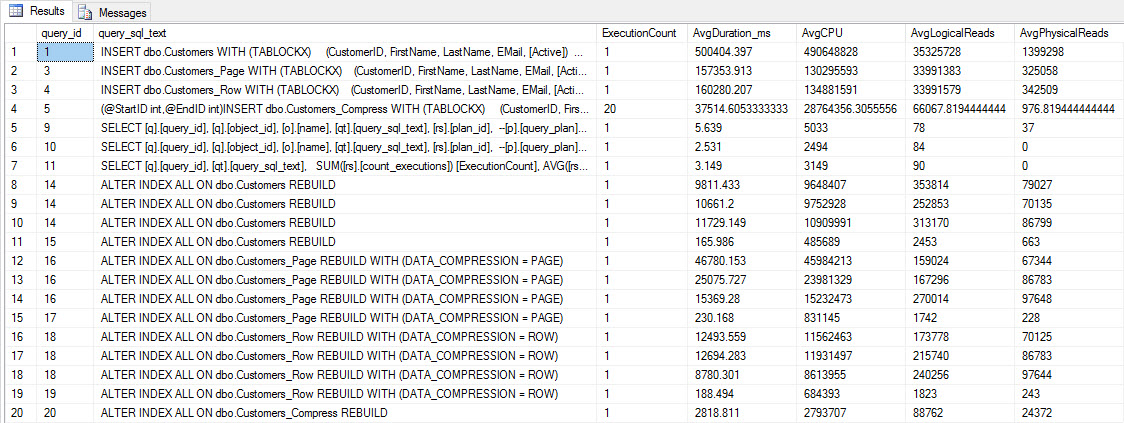 INSERT and REBUILD performance metrics
INSERT and REBUILD performance metrics
While this data is interesting, I'm more curious about how compression affects my everyday SELECT queries. I have a set of three stored procedures that each have one SELECT query, so that each index is used. I created these procedures for each table, and then wrote a script to pull values for first and last names to use for testing. Here is the script to create the procedures.
Once we have the stored procedures created, we can run the script below to call them. Kick this off and then wait a couple minutes...
SET NOCOUNT ON;
GO
DECLARE @RowNum INT = 1;
DECLARE @Round INT = 1;
DECLARE @ID INT = 1;
DECLARE @FN NVARCHAR(64);
DECLARE @LN NVARCHAR(64);
DECLARE @SQLstring NVARCHAR(MAX);
DROP TABLE IF EXISTS #FirstNames, #LastNames;
SELECT DISTINCT [FirstName],
DENSE_RANK() OVER (ORDER BY [FirstName]) AS RowNum
INTO #FirstNames
FROM [dbo].[Customers]
SELECT DISTINCT [LastName],
DENSE_RANK() OVER (ORDER BY [LastName]) AS RowNum
INTO #LastNames
FROM [dbo].[Customers]
WHILE 1=1
BEGIN
SELECT @FN = (
SELECT [FirstName]
FROM #FirstNames
WHERE RowNum = @RowNum)
SELECT @LN = (
SELECT [LastName]
FROM #LastNames
WHERE RowNum = @RowNum)
SET @FN = SUBSTRING(@FN, 1, 5) + '%'
SET @LN = SUBSTRING(@LN, 1, 5) + '%'
EXEC [dbo].[usp_FindActiveCustomer_C] @FN;
EXEC [dbo].[usp_FindAnyCustomer_C] @LN;
EXEC [dbo].[usp_FindSpecificCustomer_C] @ID;
EXEC [dbo].[usp_FindActiveCustomer_P] @FN;
EXEC [dbo].[usp_FindAnyCustomer_P] @LN;
EXEC [dbo].[usp_FindSpecificCustomer_P] @ID;
EXEC [dbo].[usp_FindActiveCustomer_R] @FN;
EXEC [dbo].[usp_FindAnyCustomer_R] @LN;
EXEC [dbo].[usp_FindSpecificCustomer_R] @ID;
EXEC [dbo].[usp_FindActiveCustomer_CS] @FN;
EXEC [dbo].[usp_FindAnyCustomer_CS] @LN;
EXEC [dbo].[usp_FindSpecificCustomer_CS] @ID;
IF @ID < 5000000
BEGIN
SET @ID = @ID + @Round
END
ELSE
BEGIN
SET @ID = 2
END
IF @Round < 26
BEGIN
SET @Round = @Round + 1
END
ELSE
BEGIN
IF @RowNum < 2260
BEGIN
SET @RowNum = @RowNum + 1
SET @Round = 1
END
ELSE
BEGIN
SET @RowNum = 1
SET @Round = 1
END
END
END
GO
After a few minutes, peek at what's in Query Store:
SELECT [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text],
SUM([rs].[count_executions]) [ExecutionCount], CAST(AVG([rs].[avg_duration])/1000 AS DECIMAL(10,2)) [AvgDuration_ms],
CAST(AVG([rs].[avg_cpu_time]) AS DECIMAL(10,2)) [AvgCPU], CAST(AVG([rs].[avg_logical_io_reads]) AS DECIMAL(10,2)) [AvgLogicalReads],
CAST(AVG([rs].[avg_physical_io_reads]) AS DECIMAL(10,2)) [AvgPhysicalReads]
FROM [sys].[query_store_query] [q]
JOIN [sys].[query_store_query_text] [qt]
ON [q].[query_text_id] = [qt].[query_text_id]
JOIN [sys].[objects] [o]
ON [q].[object_id] = [o].[object_id]
JOIN [sys].[query_store_plan] [p]
ON [q].[query_id] = [p].[query_id]
JOIN [sys].[query_store_runtime_stats] [rs]
ON [p].[plan_id] = [rs].[plan_id]
WHERE [q].[object_id] <> 0
GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id]
ORDER BY [o].[name];
You'll see that most stored procedures have executed only 20 times because two procedures against [dbo].[Customers_Compress] are really slow. This is not a surprise; neither [FirstName] nor [LastName] is indexed, so any query will have to scan the table. I don't want those two queries to slow down my testing, so I'm going to modify the workload and comment out EXEC [dbo].[usp_FindActiveCustomer_CS] and EXEC [dbo].[usp_FindAnyCustomer_CS] and then start it again. This time, I'll let it run for about 10 minutes, and when I look at the Query Store output again, now I have some good data. Raw numbers are below, with the manager-favorite graphs below.
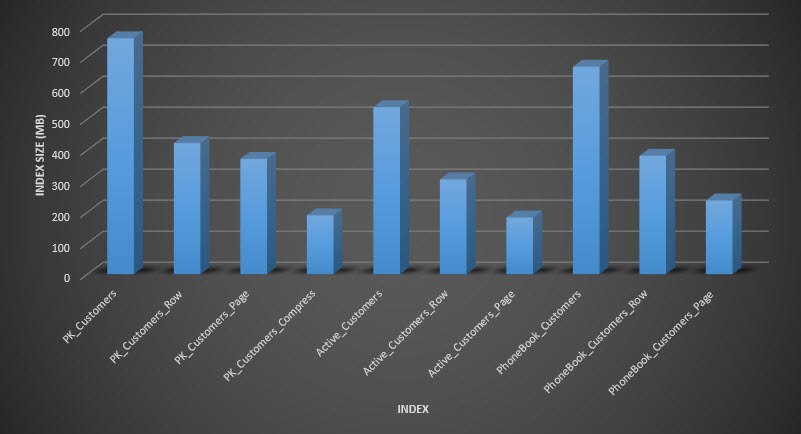
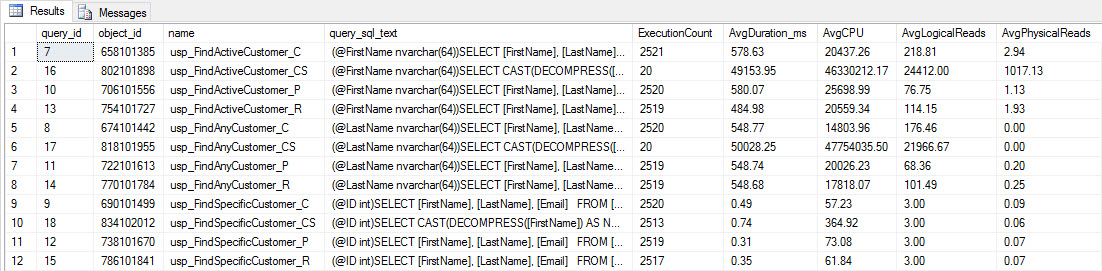 Performance data from Query Store
Performance data from Query Store
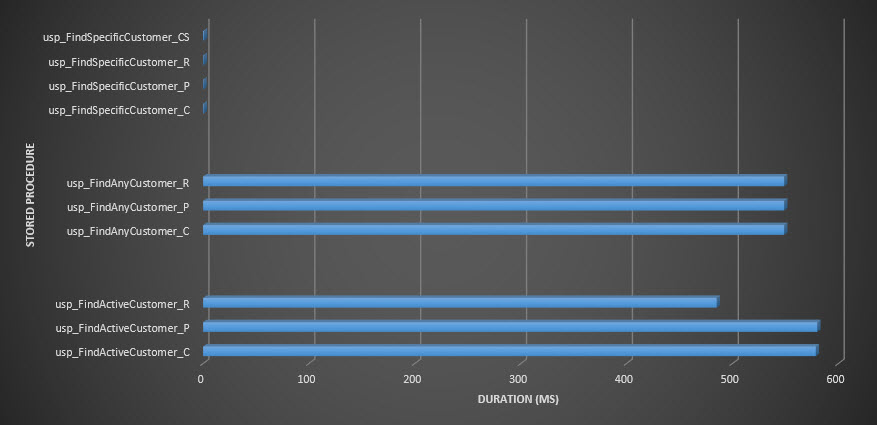 Stored procedure duration
Stored procedure duration
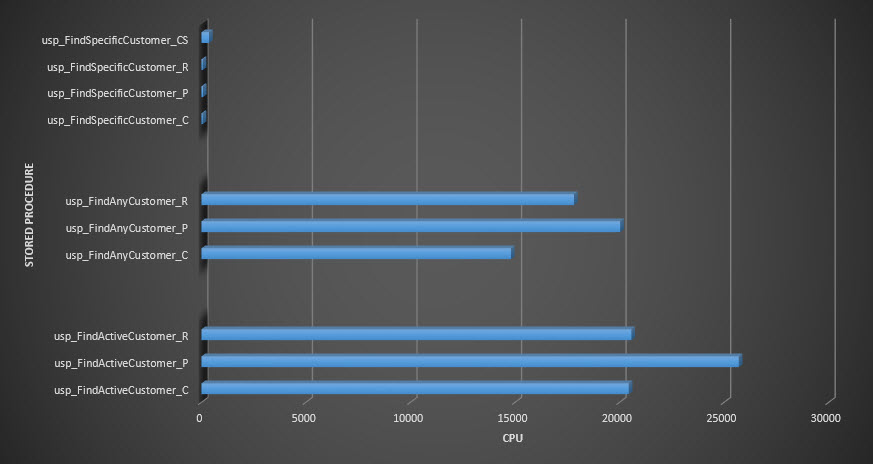 Stored procedure CPU
Stored procedure CPU
Reminder: All stored procedures that end with _C are from the non-compressed table. The procedures ending with _R are the row compressed table, those ending with _P are page compressed, and the one with _CS uses the COMPRESS function (I removed the results for said table for usp_FindAnyCustomer_CS and usp_FindActiveCustomer_CS as they skewed the graph so much we lost the differences in the rest of the data). The usp_FindAnyCustomer_* and usp_FindActiveCustomer_* procedures used nonclustered indexes and returned thousands of rows for each execution.
I expected duration to be higher for the usp_FindAnyCustomer_* and usp_FindActiveCustomer_* procedures against row and page compressed tables, compared to the non-compressed table, because of the overhead of decompressing the data. The Query Store data does not support my expectation - the duration for those two stored procedures is roughly the same (or less in one case!) across those three tables. The logical IO for the queries was nearly the same across the non-compressed and page and row compressed tables.
In terms of CPU, in the usp_FindActiveCustomer and usp_FindAnyCustomer stored procedures it was always higher for the compressed tables. CPU was comparable for the usp_FindSpecificCustomer procedure, which was always a singleton lookup against the clustered index. Note the high CPU (but relatively low duration) for the usp_FindSpecificCustomer procedure against the [dbo].[Customer_Compress] table, which required the DECOMPRESS function to display data in readable format.
SUMMARY
The additional CPU required to retrieve compressed data exists and can be measured using Query Store or traditional baselining methods. Based on this initial testing, CPU is comparable for singleton lookups, but increases with more data. I wanted to force SQL Server to decompress more than just 10 pages - I wanted 100 at least. I executed variations of this script, where tens of thousands of rows were returned, and findings were consistent with what you see here. My expectation is that to see significant differences in duration due to the time to decompress the data, queries would need to return hundreds of thousands, or millions of rows. If you're in an OLTP system, you don't want to return that many rows, so the tests here should give you an idea of how compression may affect performance. If you're in a data warehouse, then you will probably see higher duration along with the higher CPU when returning large data sets. While the COMPRESS function provides significant space savings compared to page and row compression, the performance hit in terms of CPU, and the inability to index the compressed columns due to their data type, make it viable only for large volumes of data that will not be searched.
15 thoughts on “Compression and its Effects on Performance”
Comments are closed.

Hi Erin,
I actually requested this feature years ago (https://connect.microsoft.com/SQLServer/Feedback/Details/769667), but it was closed as "Won't Fix". Interestingly, my use-case was around Azure SQL Database and gathering performance metrics. I had hundreds of sharded databases, and at the time CLR functions were not allowed, nor any form of compression, so pulling query text and plans from so many databases was a large overhead. A compression function suited me perfectly, as I could minimise the payload and network traffic before combining and consolidating the results for analysis.
It's great to see that Microsoft actually decided to implement the feature though, and also great to see your side-by-side comparisons against the other compression options. As you mention, I do think the functions should be used differently to row and page compression. It's another useful tool though, particularly with the prevalence of Azure and cloud technology in general, and the resultant increased network traffic.
"I thought comparing it directly against row and page compression was a worthwhile experiment."
I think that is where you went wrong.
In your introduction, you indicate correctly that the COMPRESS function solves the problem of compressing off-row data. Given that row and page compression are available in Standard Edition now, it doesn't make sense to position COMPRESS as a competitor to those, and yet that's exactly what you did.
A much better use of your time would have been to test how well COMPRESS solves the problem it was obviously designed for: storage and retrieval of off-row data.
First I want to thank you for pointing out that the row & page compressions are now available in standard edition as that should open it up to more people to use. Your results in that area are consistent with what we have seen at our company, and we needed to take full advantage of the space savings.
The first two comments I think highlight where the new COMPRESS function would be best used.
I did want to highlight one probable error in your article. You mention that the row and page compression save significant space and then go on to say "The COMPRESS function saved us the most space – the clustered index is one quarter the size of the original table." I don't think this is really true because you test of the table using COMPRESS had only 20% of the rows. So it's likely that the COMPRESS is on par with the row & page sizes and possibly even worse. Here again I would point out that the intended use of the function and what it can offer are still very valuable.
Rob – great point about the fact that the table using the COMPRESS function had fewer rows to begin with, and you may be correct, it may not be smaller in the end. You could test that if really interested – I just ran into time issues and errors when trying to load it, so I made a choice. And as I said in the beginning, the COMPRESS function is for off-row data, so while I wasn't comparing apples to apples, I still thought it interesting to compare the effects.
Hey Steve-
Thanks for your comment. It was a worthwhile experiment in my mind to examine the differences between native compression and the COMPRESS function, not in terms of competition, but just for comparison's sake. As a data person, I find that sometimes just capturing and looking at the data can be interesting – hence, worthwhile. Feel free to test how well COMPRESS addresses issues with off-row data and report back – I'd love to see those results!
Erin
Mike – glad that they finally added your request! :) And yes, having more tools at our disposal is great – then it comes down to knowing what to use when. Thanks for the feedback,
Erin
So I recently listened to a SQL Pass session on compression from 2012(?) and the instructor stated that non-clustered indexes can only be row compressed. Even if you make it page compressed it will only be row.
I can't find any documentation on this and I am wondering how true this is, or if it is just for older versions of SQL. I recently page compressed a non-clustered index and examined the page structure with DBCC PAGE and it appears to be page compressed, but I'm no expert. What am I missing?
Thanks
PS. Enjoyed your 2017 PreCon
Hey Robbie-
That information is incorrect (perhaps it used to be true?), you can definitely use page (or row) compression for nonclustered indexes.
Thanks for attending the pre-con! :)
Erin
If you want to see if page compression is working, you can query sys.dm_db_index_physical_stats. the compressed_page_count column can be compared to the page_count column to see how many pages are page compressed.
Note that on *any* index, if page compression doesn't save space in compressing that page, it may fall back to row compression. It's easiest to see this with indexes on uniqueidentifier columns.
———————————————–
CREATE TABLE CompressionTest (id int identity(1,1) primary key clustered,
foo int);
GO
INSERT INTO CompressionTest (foo)
SELECT top 10 object_id
FROM sys.objects
ORDER BY name;
GO 1000
CREATE NONCLUSTERED INDEX ix_foo ON CompressionTest (foo) WITH (DATA_COMPRESSION=NONE);
SELECT page_count, compressed_page_count, *
FROM sys.dm_db_index_physical_stats (db_id(),object_id('CompressionTest'),2,NULL,'DETAILED');
CREATE NONCLUSTERED INDEX ix_foo ON CompressionTest (foo) WITH (DATA_COMPRESSION=PAGE, DROP_EXISTING=ON);
SELECT page_count, compressed_page_count, *
FROM sys.dm_db_index_physical_stats (db_id(),object_id('CompressionTest'),2,NULL,'DETAILED');
I didn't have time to read every post so this observation might be a duplication.
It has been my experience on more than a few servers that the most important value of page level data compression is the increased number of database pages resident in RAM commensurate with the reduced number of physical disk reads this condition entails for logical reads.
I've seen data compression reduce the sizes of indexes and tables by anywhere from 40 to 70%, depending on the composition of the underlying data. I've taken servers with hopelessly poor data and software implementations and made them appear to be expertly implemented, just by compressing the tables and indexes.
When all databases are RAM resident all the time, servers become really fast.
A somewhat related question: what is the most efficient way to determine whether row or page compression (or none) would be most effective for each object in an Azure SQL Database?
I am guessing that you're asking because the sp_estimate_data_compression_savings SP isn't supported in Azure SQL DB? If so, Kalen Delaney rolled her own and shared it here: https://www.sqlserverinternals.com/blog/2018/6/6/creating-my-own-spestimatedatacompressionsavings
Thanks Erin, that will get me over the big hurdle.
Now I just have to run it in a cursor and consolidate the results.
This is a great discussion! I am looking to impose a standard requirement to use data compression on our tables and indexes, but am struggling on how to make this happen. I do not want to use alter statements to do the compression "after the fact", but rather have compression occur whenever the table or index is created. Any thoughts on how to implement this?
You could potentially use a DDL trigger on create table/index, but this would just be an automatic apply of an alter, rather than a manual. And for simple forms of the commands it should be easy, but can get more complicated. You could also just check in the trigger and roll back and raise an error if compression isn't detected. I guess it depends on how you balance the tolerance for manual work and the tolerance for making people angry. :-)