
Comparing string splitting / concatenation methods
Earlier this month, I published a tip about something we probably all wish we didn't have to do: sort or remove duplicates from delimited strings, typically involving user-defined functions (UDFs). Sometimes you need to reassemble the list (without the duplicates) in alphabetical order, and sometimes you may need to maintain the original order (it could be the list of key columns in a bad index, for example).
For my solution, which addresses both scenarios, I used a numbers table, along with a pair of user-defined functions (UDFs) – one to split the string, the other to reassemble it. You can see that tip here:
Of course, there are multiple ways to solve this problem; I was merely providing one method to try if you're stuck with that structure data. Red-Gate's @Phil_Factor followed up with a quick post showing his approach, which avoids the functions and the numbers table, opting instead for inline XML manipulation. He says he prefers having single-statement queries and avoiding both functions and row-by-row processing:
Then a reader, Steve Mangiameli, posted a looping solution as a comment on the tip. His reasoning was that the use of a numbers table seemed over-engineered to him.
The three of us all failed to address an aspect of this that is usually going to be quite important if you're performing the task often enough or at any level of scale: performance.
Testing
Curious to see how well the inline XML and looping approaches would perform compared to my numbers table-based solution, I constructed a fictitious table to perform some tests; my goal was 5,000 rows, with an average string length of greater than 250 characters, and at least 10 elements in each string. With a very short cycle of experiments, I was able to achieve something very close to this with the following code:
CREATE TABLE dbo.SourceTable
(
[RowID] int IDENTITY(1,1) PRIMARY KEY CLUSTERED,
DelimitedString varchar(8000)
);
GO
;WITH s(s) AS
(
SELECT TOP (250) o.name + REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(
(
SELECT N'/column_' + c.name
FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY NEWID()
FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'
),
-- make fake duplicates using 5 most common column names:
N'/column_name/', N'/name/name/foo/name/name/id/name/'),
N'/column_status/', N'/id/status/blat/status/foo/status/name/'),
N'/column_type/', N'/type/id/name/type/id/name/status/id/type/'),
N'/column_object_id/', N'/object_id/blat/object_id/status/type/name/'),
N'/column_pdw_node_id/', N'/pdw_node_id/name/pdw_node_id/name/type/name/')
FROM sys.all_objects AS o
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
)
ORDER BY NEWID()
)
INSERT dbo.SourceTable(DelimitedString)
SELECT s FROM s;
GO 20
This produced a table with sample rows looking like this (values truncated):
RowID DelimitedString
----- ---------------
1 master_files/column_redo_target_fork_guid/.../column_differential_base_lsn/...
2 allocation_units/column_used_pages/.../column_data_space_id/type/id/name/type/...
3 foreign_key_columns/column_parent_object_id/column_constraint_object_id/...
The data as a whole had the following profile, which should be good enough to uncover any potential performance issues:
;WITH cte([Length], ElementCount) AS
(
SELECT 1.0*LEN(DelimitedString),
1.0*LEN(REPLACE(DelimitedString,'/',''))
FROM dbo.SourceTable
)
SELECT row_count = COUNT(*),
avg_size = AVG([Length]),
max_size = MAX([Length]),
avg_elements = AVG(1 + [Length]-[ElementCount]),
sum_elements = SUM(1 + [Length]-[ElementCount])
FROM cte;
EXEC sys.sp_spaceused N'dbo.SourceTable';
/* results (numbers may vary slightly, depending on SQL Server version the user objects in your database):
row_count avg_size max_size avg_elements sum_elements
--------- ---------- -------- ------------ ------------
5000 299.559000 2905.0 17.650000 88250.0
reserved data index_size unused
-------- ------- ---------- ------
1672 KB 1648 KB 16 KB 8 KB
*/
Note that I switched to varchar here from nvarchar in the original article, because the samples Phil and Steve supplied assumed varchar, strings capping out at only 255 or 8000 characters, single-character delimiters, etc. I've learned my lesson the hard way, that if you're going to take someone's function and include it in performance comparisons, you change as little as possible – ideally nothing. In reality I would always use nvarchar and not assume anything about the longest string possible. In this case I knew I wasn't losing any data because the longest string is only 2,905 characters, and in this database I don't have any tables or columns that use Unicode characters.
Next, I created my functions (which require a numbers table). A reader spotted an issue in the function in my tip, where I assumed that the delimiter would always be a single character, and corrected that here. I also converted just about everything to varchar(8000) to level the playing field in terms of string types and lengths.
DECLARE @UpperLimit INT = 1000000;
;WITH n(rn) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
SELECT [Number] = rn
INTO dbo.Numbers FROM n
WHERE rn <= @UpperLimit;
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers([Number]);
GO
CREATE FUNCTION [dbo].[SplitString] -- inline TVF
(
@List varchar(8000),
@Delim varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT
rn,
vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn),
[Value]
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS x
);
GO
CREATE FUNCTION [dbo].[ReassembleString] -- scalar UDF
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS varchar(8000)
WITH SCHEMABINDING
AS
BEGIN
RETURN
(
SELECT newval = STUFF((
SELECT @Delim + x.[Value]
FROM dbo.SplitString(@List, @Delim) AS x
WHERE (x.vn = 1) -- filter out duplicates
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(SQL_VARIANT, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
END
GO
Next, I created a single, inline table-valued function that combined the two functions above, something I now wish I had done in the original article, in order to avoid the scalar function altogether. (While true that not all scalar functions are terrible at scale, there are very few exceptions.)
CREATE FUNCTION [dbo].[RebuildString]
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT [Output] = STUFF((
SELECT @Delim + x.[Value]
FROM
(
SELECT rn, [Value], vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn)
FROM
(
SELECT rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS y
) AS x
WHERE (x.vn = 1)
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(sql_variant, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
GO
I also created separate versions of the inline TVF that were dedicated to each of the two sorting choices, in order to avoid the volatility of the CASE expression, but it turned out to not have a dramatic impact at all.
Then I created Steve's two functions:
CREATE FUNCTION [dbo].[gfn_ParseList] -- multi-statement TVF
(@strToPars VARCHAR(8000), @parseChar CHAR(1))
RETURNS @parsedIDs TABLE
(ParsedValue VARCHAR(255), PositionID INT IDENTITY)
AS
BEGIN
DECLARE
@startPos INT = 0
, @strLen INT = 0
WHILE LEN(@strToPars) >= @startPos
BEGIN
IF (SELECT CHARINDEX(@parseChar,@strToPars,(@startPos+1))) > @startPos
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
ELSE
BEGIN
SET @strLen = LEN(@strToPars) - (@startPos -1)
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
BREAK
END
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
SET @startPos = @startPos+@strLen+1
END
RETURN
END
GO
CREATE FUNCTION [dbo].[ufn_DedupeString] -- scalar UDF
(
@dupeStr VARCHAR(MAX), @strDelimiter CHAR(1), @maintainOrder BIT
)
-- can't possibly return nvarchar, but I'm not touching it
RETURNS NVARCHAR(MAX)
AS
BEGIN
DECLARE @tblStr2Tbl TABLE (ParsedValue VARCHAR(255), PositionID INT);
DECLARE @tblDeDupeMe TABLE (ParsedValue VARCHAR(255), PositionID INT);
INSERT @tblStr2Tbl
SELECT DISTINCT ParsedValue, PositionID FROM dbo.gfn_ParseList(@dupeStr,@strDelimiter);
WITH cteUniqueValues
AS
(
SELECT DISTINCT ParsedValue
FROM @tblStr2Tbl
)
INSERT @tblDeDupeMe
SELECT d.ParsedValue
, CASE @maintainOrder
WHEN 1 THEN MIN(d.PositionID)
ELSE ROW_NUMBER() OVER (ORDER BY d.ParsedValue)
END AS PositionID
FROM cteUniqueValues u
JOIN @tblStr2Tbl d ON d.ParsedValue=u.ParsedValue
GROUP BY d.ParsedValue
ORDER BY d.ParsedValue
DECLARE
@valCount INT
, @curValue VARCHAR(255) =''
, @posValue INT=0
, @dedupedStr VARCHAR(4000)='';
SELECT @valCount = COUNT(1) FROM @tblDeDupeMe;
WHILE @valCount > 0
BEGIN
SELECT @posValue=a.minPos, @curValue=d.ParsedValue
FROM (SELECT MIN(PositionID) minPos FROM @tblDeDupeMe WHERE PositionID > @posValue) a
JOIN @tblDeDupeMe d ON d.PositionID=a.minPos;
SET @dedupedStr+=@curValue;
SET @valCount-=1;
IF @valCount > 0
SET @dedupedStr+='/';
END
RETURN @dedupedStr;
END
GO
Then I put Phil's direct queries into my test rig (note that his queries encode < as < to protect them from XML parsing errors, but they don't encode > or & - I've added placeholders in case you need to guard against strings that can potentially contain those problematic characters):
-- Phil's query for maintaining original order
SELECT /*the re-assembled list*/
stuff(
(SELECT '/'+TheValue FROM
(SELECT x.y.value('.','varchar(20)') AS Thevalue,
row_number() OVER (ORDER BY (SELECT 1)) AS TheOrder
FROM XMLList.nodes('/list/i/text()') AS x ( y )
)Nodes(Thevalue,TheOrder)
GROUP BY TheValue
ORDER BY min(TheOrder)
FOR XML PATH('')
),1,1,'')
as Deduplicated
FROM (/*XML version of the original list*/
SELECT convert(XML,''
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','')+'
')
FROM (SELECT DelimitedString FROM dbo.SourceTable
)XMLlist(AsciiList)
)lists(XMLlist);
-- Phil's query for alpha
SELECT
stuff( (SELECT DISTINCT '/'+x.y.value('.','varchar(20)')
FROM XMLList.nodes('/list/i/text()') AS x ( y )
FOR XML PATH('')),1,1,'') as Deduplicated
FROM (
SELECT convert(XML,''
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','')+'
')
FROM (SELECT AsciiList FROM
(SELECT DelimitedString FROM dbo.SourceTable)ListsWithDuplicates(AsciiList)
)XMLlist(AsciiList)
)lists(XMLlist);
The test rig was basically those two queries, and also the following function calls. Once I validated that they all returned the same data, I interspersed the script with DATEDIFF output and logged it to a table:
-- Maintain original order
-- My UDF/TVF pair from the original article
SELECT UDF_Original = dbo.ReassembleString(DelimitedString, '/', 'OriginalOrder')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Original = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'OriginalOrder') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Original = dbo.ufn_DedupeString(DelimitedString, '/', 1)
FROM dbo.SourceTable;
-- Phil's first query from above
-- Reassemble in alphabetical order
-- My UDF/TVF pair from the original article
SELECT UDF_Alpha = dbo.ReassembleString(DelimitedString, '/', 'Alphabetical')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Alpha = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'Alphabetical') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Alpha = dbo.ufn_DedupeString(DelimitedString, '/', 0)
FROM dbo.SourceTable;
-- Phil's second query from above
And then I ran performance tests on two different systems (one quad core with 8GB, and one 8-core VM with 32GB), and in each case, on both SQL Server 2012 and SQL Server 2016 CTP 3.2 (13.0.900.73).
Results
The results I observed are summarized in the following chart, which shows duration in milliseconds of each type of query, averaged over alphabetical and original order, the four server/version combinations, and a series of 15 executions for each permutation. Click to enlarge:
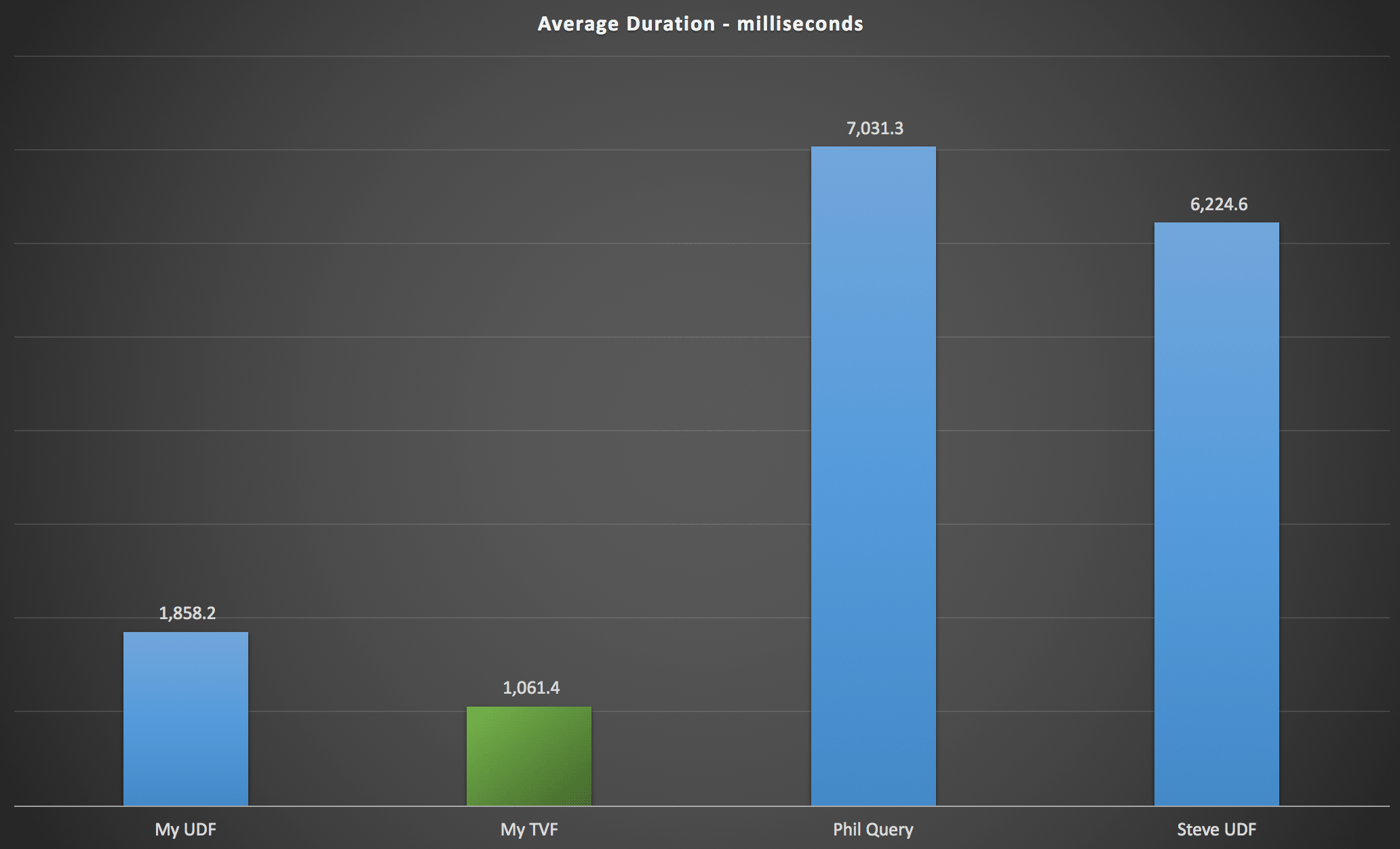
This shows that the numbers table, while deemed over-engineered, actually yielded the most efficient solution (at least in terms of duration). This was better, of course, with the single TVF that I implemented more recently than with the nested functions from the original article, but both solutions run circles around the two alternatives.
To get into more detail, here are the breakdowns for each machine, version, and query type, for maintaining original order:
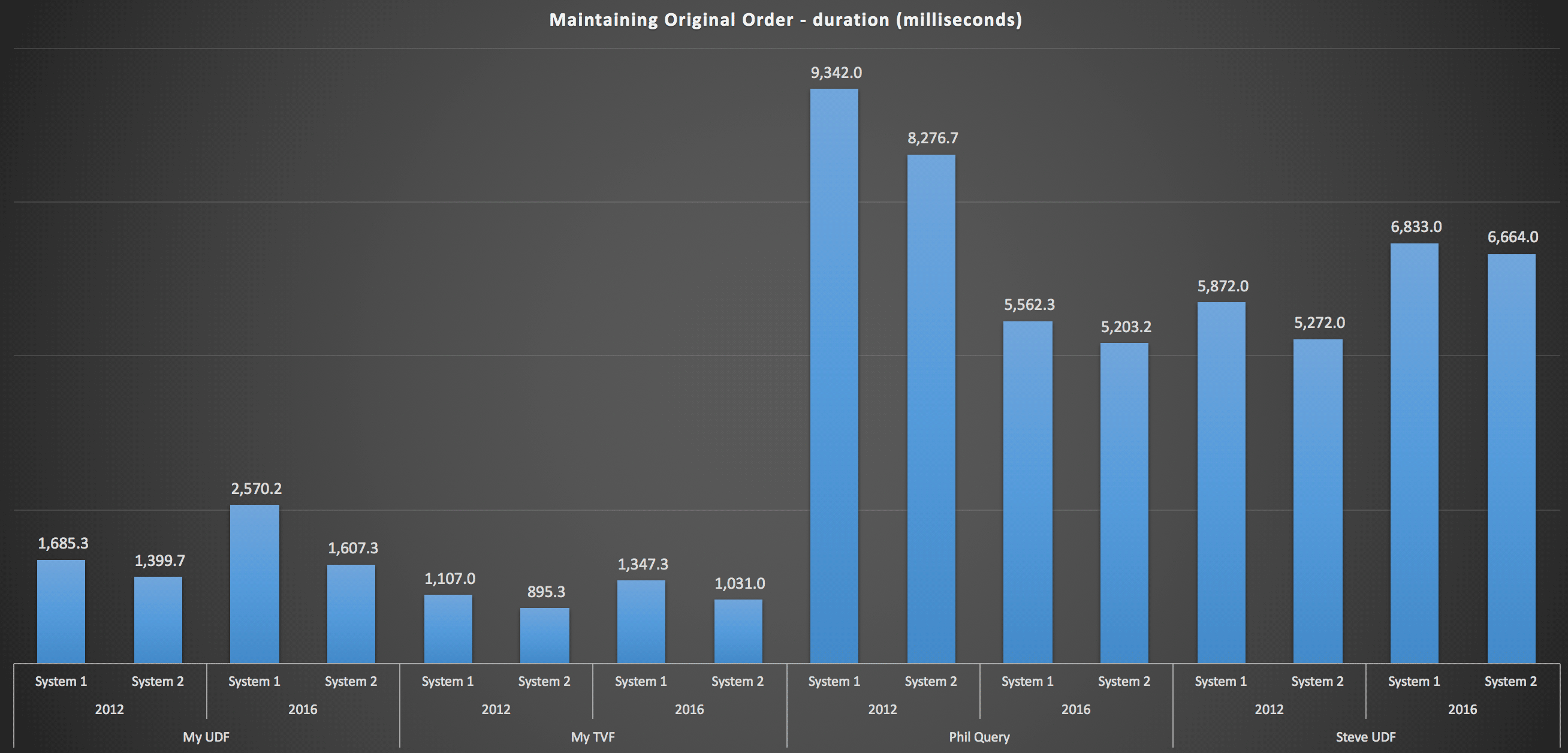
...and for reassembling the list in alphabetical order:
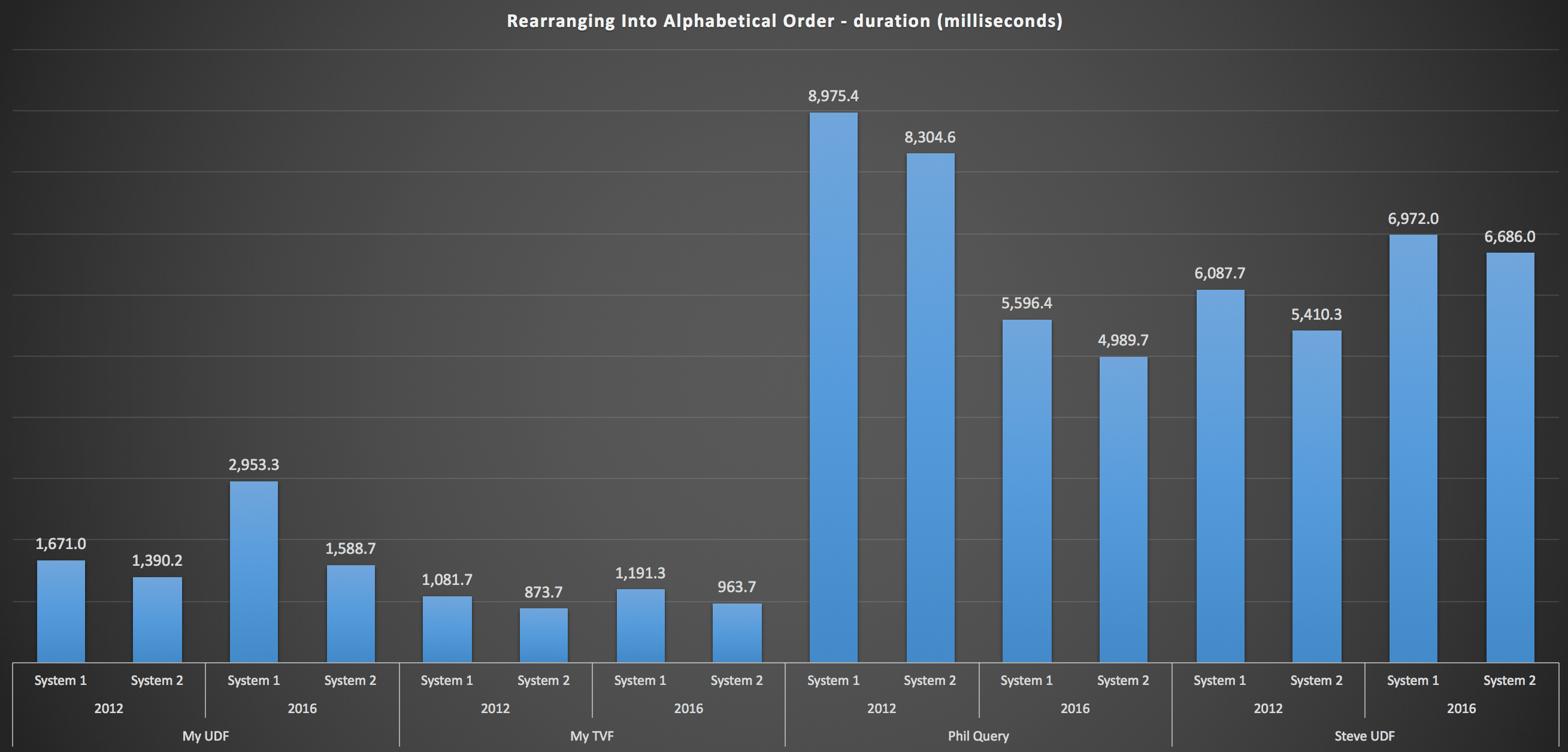
These show that the sorting choice had little impact on the outcome - both charts are virtually identical. And that makes sense because, given the form of the input data, there is no index I can envision that would make the sorting more efficient - it's an iterative approach no matter how you slice it or how you return the data. But it's clear that some iterative approaches can be generally worse than others, and it's not necessarily the use of a UDF (or a table of numbers) that makes them that way.
Conclusion
Until we have native split and concatenation functionality in SQL Server, we are going to use all kinds of unintuitive methods to get the job done, including user-defined functions. If you're handling a single string at a time, you're not going to see much difference. But as your data scales up, it will be worth your while to test various approaches (and I am by no means suggesting that the methods above are the best you'll find - I didn't even look at CLR, for example, or other T-SQL approaches from this series).
14 thoughts on “Comparing string splitting / concatenation methods”
Comments are closed.

Cor. Thanks for spotting the fact I'd clean forgotten to put in all the necessary XML character encodings. That's a bug. I'll alter the original code.
Nice work on the comparisons. I hadn't considered scale even though you mentioned it in the previous post. Looping has been a "go-to" mechanism but it is readily apparent that I need to look deeper into approaches that aren't necessarily intuitive at first blush. Thanks for the lesson.
Nice article as always Aaron!!
Borrowing Jeff Moden's awesome Delimited8KSplit code I crafted the following:
CREATE FUNCTION [dbo].[RebuildString_KGB]
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
WITH E1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), –10E+1 or 10 rows
E2(N) AS (SELECT 1 FROM E1 a, E1 b), –10E+2 or 100 rows
E4(N) AS (SELECT 1 FROM E2 a, E2 b), –10E+4 or 10,000 rows max
cteTally(N) AS (–==== This provides the "base" CTE and limits the number of rows right up front
— for both a performance gain and prevention of accidental "overruns"
SELECT TOP (ISNULL(DATALENGTH(@List),0)) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4
),
cteStart(N1) AS (–==== This returns N+1 (starting position of each "element" just once for each delimiter)
SELECT 1 UNION ALL
SELECT t.N+1 FROM cteTally t WHERE SUBSTRING(@List,t.N,1) = @Delim
),
cteLen(N1,L1) AS(–==== Return start and length (for use in substring)
SELECT s.N1,
ISNULL(NULLIF(CHARINDEX(@Delim,@List,s.N1),0)-s.N1,8000)
FROM cteStart s
)
SELECT [Output] = STUFF((
SELECT @Delim + x.[Value]
FROM
(
SELECT rn, [Value], vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn)
FROM
(
–===== Do the actual split. The ISNULL/NULLIF combo handles the length for the final element when no delimiter is found.
SELECT rn = ROW_NUMBER() OVER(ORDER BY l.N1),
[Value] = SUBSTRING(@List, l.N1, l.L1)
FROM cteLen l
) AS y
) AS x
WHERE (x.vn = 1)
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(sql_variant, NULL) END
FOR XML PATH, TYPE).value(N'.[1]',N'varchar(8000)'),1,LEN(@Delim),")
);
GO
Since we truly want to just know the server's execution performance, I tested shoving the output into a variable, which avoids the overhead of bundling the rows up and sending them to SSMS and rehydrating them there:
SET NOCOUNT ON
go
DECLARE @tvf_original varchar(8000), @start datetime = getdate()
SELECT @tvf_original = f.[Output]
FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'OriginalOrder') AS f
ORDER BY t.RowID;
SELECT DATEDIFF(ms, @start, GETDATE())
GO 10
For OriginalOrder, testing your iTVF version got 891.7ms average for 10 runs on my system (2012). The KGB version was 798.4ms, which is about a 10.5% improvement. Alphabetical ordering showed the KGB version to be almost 6% faster.
It can be see here in the really nice SQLServerCentral.com article (http://www.sqlservercentral.com/articles/Tally+Table/72993/, which has an AMAZING thread of 785 posts in the article discussion!!) that CLR is the most efficient string splitting mechanism but the Delimited8KSplit is really very close!
I hadn't realised that performance was quite so important for your application – I only use it to pass lists to functions. Here is a version that goes over twice the speed of my GROUP BY version on my very brief timings. (I haven't had time to construct your test harness which could give quite different results). Because fn:distinct-values doesn't take a collation, it will only do a case-sensitive comparison. As far as I can see, the work of escaping and unescaping with the REPLACE function takes a quite a proportion of time. flwor is really another way of doing RBAR, but faster!
SELECT replace(replace(replace( stuff(replace(convert(VARCHAR(MAX), xmllist.query(' for $x in distinct-values((data(/list/y/@i))) return (concat("/",$x)) ')), ' /','/') ,1,1,'') ,'<',''),'&','&') AS result FROM (/*XML version of the original list*/ SELECT convert(XML,'<y i="'+ replace(replace(replace(ASCIIList,'&','&') ,'') FROM (VALUES ('Hickory/Dickory/Dock/Dock'), ('Bravo/Alpha/Bravo/Tango/Delta/Bravo/Alpha/Delta'), ('One/Two/Three/Three/Three/Four'), ('<some/awkward&/bits'), ('Baa/Baa/Black/Sheep') )XMLlist(AsciiList) )lists(XMLlist);He ha Phil! I've never had a customer or forum user tell me that performance was not important.
Thanks Kevin, I wasn't trying to prove that the Numbers table is the fastest way to do it (in fact in previous articles on the topic I acknowledged that it wasn't). I was merely showing that the mere use of a function did not necessarily add additional overhead that made it worse than non-function approaches, and only because I was suggested that these other approaches were better in some way. I don't find them simpler nor do I find them faster (but again, this wasn't intended to seek out the fastest way to split strings – I would start with not splitting in the first place, e.g. TVPs, then I would move to CLR).
Hi Aaron,
I enjoyed the post and accept that you are not trying to get the fastest string splitter etc.
Nevertheless, I just wanted to suggest a few tweaks that can improve the speed of your iTVF by approximately 15%.
I only suggest these for the purpose of further discussion, not because I think you need them.
Firstly, and most importantly – the use of "text()" in shredding xml is always worth striving for and in this case, you can replace this line:
FOR XML PATH, TYPE).value(N'.[1]',N'varchar(8000)'),1,LEN(@Delim),")
With this:
FOR XML PATH("), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),")
Next, the use of row_number() to populate the column [rn] is not necessary, I believe. You can achieve the same ordering by replacing this line:
SELECT rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
With this:
SELECT rn = Number,
And finally, a tiny change, is to remove the implicit conversion to sql_variant from the ORDER BY, replacing this:
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(sql_variant, NULL) END
With this:
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(sql_variant, x.rn)
WHEN 'Alphabetical' THEN CONVERT(sql_variant, x.[Value])
ELSE CONVERT(sql_variant, NULL) END
These changes all gave me a slight improvement in performance compared to the original code and combined to take the average execution time from about 1300ms down to about 1100ms.
I hope you find these suggestion interesting, if nothing else.
I think your comments and suggestions are more than interesting, Magoo!
I don't have the ability to test it out right now, but I wonder if making sprocs dedicated to the desired order could make things a tad faster by avoiding the CASE in the ORDER BY altogether.
Some great ideas by Mr Magoo. I liked Kevin's method too. We've now (xcelsius mostly) worked out an even faster and cleaner way of doing this using 'distinct-values'. It would be interesting to see how it stacks up with yours, performance-wise. (though ours is doing a case-sensitive sort only)
Select @time=GetDate()
select replace(Replace(Replace(Replace(cast(d.query('distinct-values(/i/text())') as varchar(50)),'&','&'),'<','<'),' ','/'),' ',' ') as Deduplicated
— select *
from(
SELECT cast(''+replace(replace(Replace(replace(AsciiList,' ',' '),'&','&'),'<','<'),'/','')+'' as xml) as d
FROM (VALUES
('Hickory/Dickory/Dock/dock'),
('Bra vo/Alpha/Bra vo/Tango/Delta/Bravo/Alpha/Delta'),
('One/Two/Three/Three/Three/Four'),
('Baa/Baa/Black/Sheep'),
('<some/awkward&/bits'),
('Case/Dickory/case')
)XMLlist(AsciiList)
)lists;
I just read a post yesterday that indicated SQL Server 2016 RC0 has a built in function called STRING_SPLIT. That post demonstrated how to use it but did no performance comparisons to other solutions.
Yes, I mentioned it last week briefly here, under the RC0 section. Functionality is limited, but yeah, it's fast. I'll be posting about it soon.
Here is the faster solution (under half a second) and with a cleaner code than all complex functions used but however, require SQL CLR enabled.
Using Eval-SQL.NET, you can use C# Syntax and all it's advantage in SQL including Regex and LINQ!
Here is an example of splitting with a regular expression, taking distinct values, ordering by name and including the array index!
DECLARE @sqlnet SQLNET = SQLNET::New('
Regex.Split(input, "/")
.Distinct()
.OrderBy(x => x)
.Select((x, i) => new { i, x }')
— Temporary table is used to allow parallel split
SELECT RowID, CAST(Value_1 AS INT) AS Ordinal, Value_2
INTO #test
FROM SourceTable
CROSS APPLY dbo.SQLNET_EvalTVF_2(@sqlnet.ValueString('input', DelimitedString))
SELECT * FROM #test
ORDER BY RowID, Ordinal
DROP TABLE #test
Disclaimer: I'm the owner of the project Eval-SQL.NET (http://eval-sql.net/)
Someone asked me by email how to reassemble the string using my library, so here is the answer using "string.Join" (Take less than 200 ms):
DECLARE @sqlnet SQLNET = SQLNET::New('string.Join("/",
Regex.Split(input, "/").Distinct().OrderBy(x => x)')
SELECT RowID, @sqlnet.ValueString('input', DelimitedString).EvalString()
FROM SourceTable
Aaron, how did you measure Average Duration? I'm experimenting and want to duplicate testing.