
Mitigating Index Fragmentation

This isn't good fragmentation, either
Last month I wrote about unexpected clustered index fragmentation so, this time, I'd like to discuss some of the things you can do to avoid index fragmentation happening. I'll assume you've read the previous post and are familiar with the terms I defined there, and throughout the rest of this article, when I say 'fragmentation' I'm referring to both the logical fragmentation and low page density problems.
Choose a Good Cluster Key
The most expensive data structure to operate on to remove fragmentation is the clustered index of a table, because it's the biggest structure as it contains all the table data. From a fragmentation perspective, it makes sense to choose a cluster key that matches the table insert pattern, so there's no possibility of an insert happening on a page where there's no space and hence causing a page split and introducing fragmentation.
What constitutes the best cluster key for any given table is a matter of much debate, but in general you won't go wrong if your cluster key has the following simple properties:
- Narrow (i.e. as few columns as possible)
- Static (i.e. you don't ever update it)
- Unique
- Ever-increasing
It's the ever-increasing property which is the most important for fragmentation prevention, as it avoids random inserts that can cause page splits on already-full pages. Examples of such a key choice are int identity and bigint identity columns, or even a sequential GUID from the NEWSEQUENTIALID() function.
With these types of keys, new rows will have a key value guaranteed to be higher than all others in the table, and so the new row's insertion point will be at the end of the right-most page in the clustered index structure. Eventually the new rows will fill that page up and another page will be added to the right-hand side of the index, but with no damaging page split occurring.
Now, if you have a clustered index key that's not ever-increasing, it may be a very complex and unpalatable procedure to change it to an ever-increasing one, so don't worry – instead you can use a fill factor like I discuss below.
By the way, for a much deeper insight into choosing a cluster key and all the ramifications of it, check out Kimberly's Clustering Key blog category (read from the bottom up).
Don't Update Index Key Columns
Whenever a key column is updated, it's not just a simple in-place update, although many places online and in books say that it is (they're wrong). A key column cannot be updated in place as the new key value would then mean that the row is in the wrong key order for the index. Instead a key column update is translated into a full row delete plus a full row insert with the new key value. If the page where the new row will be inserted does not have enough space on it, a page split will happen, causing fragmentation.
Avoiding key column updates should be easy to do for the clustered index, as it's a poor design that calls for updating the cluster key of a table row. For nonclustered indexes though, it's unavoidable if updates to the table happen to involve columns on which there is a nonclustered index. For those cases, you'll need to use a fill factor.
Don't Update Variable-Length Columns
This one's easier said than done. If you have to use variable-length columns and it's possible that they get updated, then it's possible that they may grow and so require more space for the updated row, leading to a page split if the page is already full.
There are a few things you could do to avoid fragmentation in this case:
- Use a fill factor
- Use a fixed-length column instead, if the overhead of all the extra padding bytes is less of a problem than fragmentation or using a fill factor
- Use a placeholder value to 'reserve' space for the column – this is a trick you can use if the application enters a new row and then comes back to fill in some of the details, causing variable-length column expansion
- Perform a delete plus insert instead of an update
Use a Fill Factor
As you can see, many of the ways to avoid fragmentation are unpalatable as they involve application or schema changes, and so using a fill factor is an easy way to mitigate fragmentation.
An index fill factor is a setting for the index that specifies how much empty space to leave on each leaf-level page when the index is created, rebuilt, or reorganized. The idea is that there's enough free space on the page to allow random inserts or row growths (from a versioning tag being added or updated variable-length columns) without the page filling up and requiring a page split. However, eventually the page will fill up, and so periodically the free space needs to be refreshed by rebuilding or reorganizing the index (generally called performing index maintenance). The trick is in finding the right fill factor to use, along with the right periodicity of index maintenance.
You can read more about setting a fill factor in MSDN here. Don't fall into the trap of setting the fill factor for the entire instance (using sp_configure) as that means that all indexes will be rebuilt or reorganized using that fill factor value, even those indexes that don't have any fragmentation problems. You don't want your large clustered indexes, with nice ever-increasing keys, to all have 30% of their leaf-level space wasted preparing for random inserts that will never happen. It's much better to figure out which indexes are actually affected by fragmentation and only set a fill factor for those.
There's no right answer or magic formula I can give you for this. The generally-accepted practice is to put a fill factor of 70 (meaning leave 30% free space) in place for those indexes where fragmentation is a problem, monitor how quickly fragmentation occurs, and then modify either the fill factor or the index maintenance frequency (or both).
Yes, this means you're deliberately wasting space in the indexes to avoid fragmentation, but that's a good trade-off to make given how expensive page splits are and how detrimental fragmentation can be for performance. And yes, in spite of what some might say, this is still important even if you're using SSDs.
Summary
There are some simple things you can do to avoid fragmentation happening, but as soon as you get into nonclustered indexes, or use snapshot isolation or readable secondaries, fragmentation rears its ugly head and you need to try to prevent it.
Now don't knee-jerk and think that you should set a fill factor of 70 on all your instances – you need to choose and set them carefully, as I described above.
And don't forget about SQL Sentry Fragmentation Manager, which you can use (as an add-on to Performance Advisor) to help figure out where fragmentation problems are and then address them. For example, on the Indexes tab, you can easily sort your indexes by highest fragmentation first (and, if you like, apply a filter to the row count column, to ignore your smaller tables):
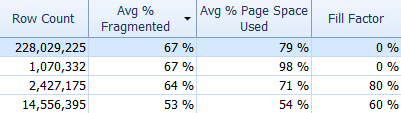
And then see if those indexes are using the default fill factor (0%), or perhaps a non-default fill factor, which might not be a good match for your data and DML patterns. I'll let you guess which ones in the above screen shot I would be most interested in investigating. Implementing more appropriate index fill factors is the simplest way to address any problems you spot.
4 thoughts on “Mitigating Index Fragmentation”
Comments are closed.
Setting a fill factor at the instance level is a similarly bad decision as using auto shrink. Or fiber mode. I wish some of these godforsaken options were finally removed.
Hi Paul,
excellent to point to so much dedicated hints to avoid fragmentation. Only from the point of fragmentation I have to agree to 100% but …
I think it is a misconception to choose an "ever increasing" clustered index always.
I have written about the drawbacks of such a strategy (unfortunately only in German) in a scenario where you have workloads with hundreds of INSERT requests at the same time (I did work in such an enterprise environment in a Bank). In this case you generate a messy hotspot at the end of the index! This will cause high PAGELATCH_EX wait stats at that point.
http://db-berater.blogspot.de/2015/04/guid-vs-intidentity-als-clustered-key.html
Furthermore such a high concurrent workload may have no benefit in terms of fragmentation anyhow because of the problem with the waiting for resource, too.
If task 1 has gotten the ID = 100 and task 2 has gotten 98 than a page split may occur IF task 1 has granted access to the resource (leaf page) before task 2
To be honest I have found scenarios where a clustered index is definitely not usefull (o.k. – pointing to the maintenance aspect it always makes sence :) ).
Have a look to the excellent post from Markus Wienand (Austria) here:
http://use-the-index-luke.com/blog/2014-01/unreasonable-defaults-primary-key-clustering-key
It's a wonderful controverse debate about usage of clustered indexes :)
Conclusion:
To avoid fragmentation an increasing clustered key makes sense. In workload scenarios with very high concurrency you won't have benefits with that strategy.
Best, Uwe
Yes, you're right – the 'insert hotspot' problem that I've mentioned on my SQLskills blog and talk about around PAGELATCH waits. That's a whole can of worms I wasn't opening in this post but I'll be covering in the next post in the series. And Kimberly's posts which I pointed out cover the whole clustered index or not debate, and key choice. Thanks
Great article. Finally someone else who points out that if you update variable width columns in a table with a clustered index you can thereby cause page splits even if the updated column(s) are not part of the key.
I was hopeful when I saw the word "mitigating" in the title rather than "eliminating". Reading the article bore out my hopes. Thank you for the reasonable approach.