
Knee-Jerk PerfMon Counters : Page Life Expectancy
All my posts this year have been about knee-jerk reactions to wait statistics, but in this post I’m deviating from that theme to talk about a particular bug bear of mine: the page life expectancy performance counter (which I’ll call PLE).
What Does PLE Mean?
There are all kinds of incorrect statements about page life expectancy out there on the Internet, and the most egregious are those that specify that the value 300 is the threshold for where you should be worried.
To understand why this statement is so misleading, you need to understand what PLE actually is.
The definition of PLE is the expected time, in seconds, that a data file page read into the buffer pool (the in-memory cache of data files pages) will remain in memory before being pushed out of memory to make room for a different data file page. Another way to think of PLE is an instantaneous measure of the pressure on the buffer pool to make free space for pages being read from disk. For both of these definitions, a higher number is better.
What’s A Good PLE Threshold?
A PLE of 300 means your entire buffer pool is being effectively flushed and re-read every five minutes. When the threshold guidance for PLE of 300 was first given by Microsoft, around 2005/2006, that number may have made more sense as the average amount of memory on a server was much lower.
Nowadays, where servers routinely have 64GB, 128GB, and higher amounts of memory, having roughly that much data being read from disk every five minutes would likely be the cause of a crippling performance issue
In reality then, by the time PLE is hovering at or below 300, your server is already in dire straits. You’d start to be worried way, way before PLE is that low.
So what’s the threshold to use for when you should be worried?
Well, that’s just the point. I can’t give you a threshold, as that number’s going to vary for everyone. If you really, really want a number to use, my colleague Jonathan Kehayias came up with a formula:
Even that number is somewhat arbitrary, and your mileage is going to vary.
I don’t like to recommend any numbers. My advice is for you to measure your PLE when performance is at the desired level – that’s the threshold that you use.
So do you start to worry as soon as PLE drops below that threshold? No. You start to worry when PLE drops below that threshold and stays below that threshold, or if it drops precipitously and you don’t know why.
This is because there are some operations that will cause a PLE drop (e.g. running DBCC CHECKDB or index rebuilds can do it sometimes) and aren’t cause for concern. But if you see a large PLE drop and you don’t know what’s causing it, that’s when you should be concerned.
You might be wondering how DBCC CHECKDB can cause a PLE drop when it does disfavoring and tries hard to avoid flushing the buffer pool with the data it uses (see this blog post for an explanation). It’s because the query execution memory grant for DBCC CHECKDB is miscalculated by the Query Optimizer and can cause a big reduction in the size of the buffer pool (the memory for the grant is stolen from the buffer pool) and a consequent drop in PLE.
How Do You Monitor PLE?
This is the tricky bit. Most people will go straight to the Buffer Manager performance object in PerfMon and monitor the Page life expectancy counter. Is this the right approach? Most likely not.
I’d say that a large majority of servers out there today are using NUMA architecture, and this has a profound effect on how you monitor PLE.
When NUMA is involved, the buffer pool is split up into buffer nodes, with one buffer node per NUMA node that SQL Server can ‘see’. Each buffer node tracks PLE separately and the Buffer Manager:Page life expectancy counter is the average of the buffer node PLEs. If you’re just monitoring the overall buffer pool PLE, then pressure on one of the buffer nodes may be masked by the averaging (I discuss this in a blog post here).
So if your server is using NUMA, you need to monitor the individual Buffer Node:Page life expectancy counters (there will be one Buffer Node performance object for each NUMA node), otherwise you’re good monitoring the Buffer Manager:Page life expectancy counter.
Even better is to use a monitoring tool like SQL Sentry Performance Advisor, which will show this counter as part of the dashboard, taking into account the NUMA nodes on the server, and allow you to easily configure alerts.
Examples of Using Performance Advisor
Below is an example portion of a screen capture from Performance Advisor for a system with a single NUMA node:
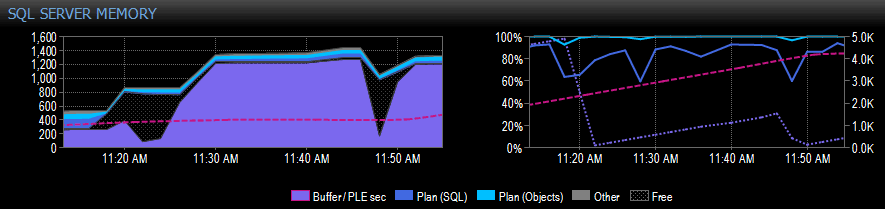
On the right-hand side of the capture, the pink-dashed line is the PLE between 10.30am and about 11.20am – it’s climbing steadily up to 5,000 or so, a really healthy number. Just before 11.20am there’s a huge drop, and then it starts to climb again until 11.45am, where it drops again.
This is typically what you would see if the buffer pool is full, with all the pages being used, and then a query runs that causes a huge amount of different data to be read from disk, displacing much of what’s already in memory and causing a precipitous drop in PLE. If you didn’t know what caused something like this, you’d want to investigate, as I describe further down.
As a second example, the screen capture below is from one of our Remote DBA clients where the server has two NUMA nodes (you can see that there are two purple PLE lines), and where we use Performance Advisor extensively:

On this client’s server, every morning at around 5am, an index maintenance and consistency checking job kicks off that cause the PLE to drop in both buffer nodes. This is expected behavior so there’s no need to investigate as long as PLE rises up again during the day.
What Can You Do About PLE Dropping?
If the cause of the PLE drop isn’t known, you can do a number of things:
- If the problem is happening now, investigate which queries are causing reads by using the
sys.dm_os_waiting_tasksDMV to see which threads that are waiting for pages to be read from disk (i.e. those waiting forPAGEIOLATCH_SH), and then fix those queries. - If the problem happened in the past, look in the sys.dm_exec_query_stats DMV for queries with high numbers of physical reads, or use a monitoring tool that can give you that information (e.g. the Top SQL view in Performance Advisor), and then fix those queries.
- Correlate the PLE drop with scheduled Agent jobs that perform database maintenance.
- Look for queries with very large query execution memory memory grants using the
sys.dm_exec_query_memory_grantsDMV, and then fix those queries.
My previous post here explains more about #1 and #2, and a script to investigate waits occurring on a server and link to their query plans is here.
The "fix those queries" is beyond the scope of this post, so I’ll leave that for another time or as an exercise for the reader ☺
Summary
Don’t fall into the trap of believing any recommended PLE threshold that you might read online. The best way to react to PLE changes is when PLE drops below whatever your comfort level is and stays there – that’s the indication of a performance problem that you should investigate.
In the next article in the series, I’ll discuss another common cause of knee-jerk performance tuning. Until then, happy troubleshooting!
19 thoughts on “Knee-Jerk PerfMon Counters : Page Life Expectancy”
Comments are closed.

Good article Paul! This is something we're working on fixing currently as well.
Nice. Paul has sql tech authoring down to an art. So simple even I can follow it. Thanks!!!
Great article Paul, always enjoy and appreicate the content you post!
I have a server, which has a strange situation where PLE foes down to 0 and then comes back gradually to 700,000 in a week. Its been happening now for months. Any thoughts?
It could be something like running a long DBCC CHECKDB or large index rebuild.
Thanks Paul. I went that route and our rebuild routine is based on % fragmentation and is pretty light weight. CHECKDB is running on Sundays and aligns with the PLE depletion except I get a one off situation on a weekday to throw the theory off. Since its not impacting performance, I am not so worried but bugs the hell out of me to not have figured it out yet. I wish there were more than 24 hours in a day.
While this is a very good article among many, about PLE, I believe still it is very unclear to how to catch the culprit causing the PLE drop. I am fine with this PLE drop during maintenance window but what about other drops during peak hours? The hunt is on….
Hi Paul
You mention overall PLE is a harmonic mean.
What about the node level PLE?
Does it take an arithmetic mean of all page lifetimes in that node (that may be impractical?)? Is it some other calculation (e.g. some kind of estimate based on number of new pages)?
Secondly do queries ever span NUMA nodes or is memory only allocated within a NUMA node (i.e. if you see pressure on one NUMA node it will because a query is asking for pages not in that NUMA node or not in any NUMA node (remote access)). If a query asks for memory does it always displace pages in the NUMA node it is running or cab it displace remote pages?
Hopefully my questions are clear.
Hi Jacob,
1) Node-level PLE is just straight PLE for that portion of the buffer pool
2) Yes, queries can span NUMA nodes depending on how many processor cores are used by parallel zones in the query plan
3) A page only resides in one portion of the buffer pool – NUMA node memory pressure is because threads on that node are reading pages locally (i.e. they only displace local pages)
Thanks
Hi Paul
Thanks for the reply.
Just to clarify two points
"Straight PLE" – by that do you mean if I have 100 pages in a node, straight PLE is just the arithmetic mean of those 100 page's lifetimes?
"Local Pages" – what I was trying to get at here was let's say I'm a thread running on a NUMA node and I request a page. That page is not in my NUMA node memory but it does exist in a remote node. You seem to imply I grab that page from the remote node (makes sense)? Is there any point where it makes sense to migrate that page to my local node?
Thanks
No – PLE is an instantaneous measure of the expected lifetime of a page read into memory at that point in time – see the first paragraph of the post.
Yes – the thread will do a 'foreign memory access' to get the page from the memory of the other NUMA node.
The page will never migrate to the local node. It may be aged out from the buffer pool partition on a remote node and then subsequently read into memory on the local node, but those are not related actions (if you see what I mean).
Thanks Paul
I recently read the LRU-K paper by O'Neil, O'Neil and Welkum to understand a little more your comment about PLE being an instantaneous measure of the expected lifetime of a page read into memory at that point in time”.
It seems to me this makes PLE drops somewhat misleading, which is why I was pressing the point as to exactly how this instantaneous measure is arrived at.
If I have a buffer pool of 100 pages and if we assume LRU-2 is used, and we read in a page, this will require this displacement of one of the 100 pages, which using LRU-2 will choose the page with the largest backward-k distance (and if that happens to be infinity some kind of tiebreaker will be used).
Using this information how would this affect PLE?
If PLE is rising at 1 per second for example, does this mean 0 new pages are being read into the buffer cache?
How does PLE drop when 1 new page is read in?
How does PLE drop when n new pages are read in?
How does PLE take into account things like correlated references and correlated reference periods etc.?
Ultimately the question becomes if I see a large drop in PLE does this really mean a large amount of new pages have been read in or can this be simulated by a short activity burst etc.?
100-page question: one of the pages will be displaced only if the buffer pool has no more space for pages, or the free list is getting too low, in which case the lazy writer will be asked to remove some pages and PLE will drop.
PLE rising 1 per second means no new pressure on the buffer pool to make space.
Large PLE drop means a large burst of read activity that's causing a lot of pages to be dropped out of the buffer pool.
Other questions – not simple answers and I'd be basically explaining how all the code works, which is beyond the scope of this article.
Thanks
Thanks Paul.
I'd be interested in the detail if you ever get time to post about it.
I imagine it is based on new pages read in and essentially says something like "if new pages were read in at this rate consistently a page can expect to stay in the buffer unreferenced for x seconds". Which would be based on things like correlated reference periods and retained information period etc.
It seems only sustained periods of low PLE are significant, as sharp drops are merely indicative of new pages being read in at that time.
Hello Paul ,
I 've one quick question.
i.e if i am doing some heavy deletions in my big fat table and I know it will update my clustered index as well so does that brings PLE drop because I 've seen this behavior when we run deletion we get PLE dropped on only 1 numa node out of 4 though which doesn't lead to any problem because other numa nodes are not in pressure but it raised the curiosity and would like to confirm with you.
Please let me know know how deleting rows would update CI and can drop ple or refer me any article.
Thank you so much!!
That sounds like normal behavior to me, if the delete is touching a large number of pages that aren't already in the buffer pool, so forcing free pages to be created by the lazy writer.
Thanks , That's quite normal to observe ple drops when big fat indexes are updated !!