
Finding Performance Benefits with Partitioning
Partitioning is a SQL Server feature often implemented to alleviate challenges related to manageability, maintenance tasks, or locking and blocking. Administration of large tables can become easier with partitioning, and it can improve scalability and availability. In addition, a by-product of partitioning can be improved query performance. It's not a guarantee or a given, and it’s not the driving reason to implement partitioning, but it is something worth reviewing when you partition a large table.
Background
As a quick review, the SQL Server partitioning feature is only available in Enterprise and Developer Editions. Partitioning can be implemented during initial database design, or it can be put into place after a table already has data in it. Understand that changing an existing table with data to a partitioned table is not always fast and simple, but it’s quite feasible with good planning and the benefits can be quickly realized.
A partitioned table is one where the data is separated into smaller physical structures based on the value for a specific column (called the partitioning column, which is defined in the partition function). If you want to separate data by year, you might use a column called DateSold as the partitioning column, and all data for 2013 would reside in one structure, all data for 2012 would reside in a different structure, etc. These separate sets of data allow for focused maintenance (you can rebuild just a partition of an index, rather than the entire index) and permit data to be quickly added and removed because it can be staged in advance of actually being added to, or removed from, the table.
The Setup
To examine the differences in query performance for a partitioned versus a non-partitioned table, I created two copies of the Sales.SalesOrderHeader table from the AdventureWorks2012 database. The non-partitioned table was created with only a clustered index on SalesOrderID, the traditional primary key for the table. The second table was partitioned on OrderDate, with OrderDate and SalesOrderID as the clustering key, and had no additional indexes. Note that there are numerous factors to consider when deciding what column to use for partitioning. Partitioning often, but certainly not always, uses a date field to define the partition boundaries. As such, OrderDate was selected for this example, and sample queries were used to simulate typical activity against the SalesOrderHeader table. The statements to create and populate both tables can be downloaded here.
After creating the tables and adding data, the existing indexes were verified and then statistics updated with FULLSCAN:
EXEC sp_helpindex 'Sales.Big_SalesOrderHeader';
GO
EXEC sp_helpindex 'Sales.Part_SalesOrderHeader';
GO
UPDATE STATISTICS [Sales].[Big_SalesOrderHeader] WITH FULLSCAN;
GO
UPDATE STATISTICS [Sales].[Part_SalesOrderHeader] WITH FULLSCAN;
GO
SELECT
sch.name + '.' + so.name AS [Table],
ss.name AS [Statistic],
sp.last_updated AS [Stats Last Updated],
sp.rows AS [Rows],
sp.rows_sampled AS [Rows Sampled],
sp.modification_counter AS [Row Modifications]
FROM sys.stats AS ss
INNER JOIN sys.objects AS so ON ss.[object_id] = so.[object_id]
INNER JOIN sys.schemas AS sch ON so.[schema_id] = sch.[schema_id]
OUTER APPLY sys.dm_db_stats_properties(so.[object_id], ss.stats_id) AS sp
WHERE so.[object_id] IN (OBJECT_ID(N'Sales.Big_SalesOrderHeader'), OBJECT_ID(N'Sales.Part_SalesOrderHeader'))
AND ss.stats_id = 1;
In addition, both tables have the exact same distribution of data and minimal fragmentation.
Performance for a Simple Query
Before any additional indexes were added, a basic query was executed against both tables to calculate totals earned by sales person for orders placed in December 2012:
SELECT [SalesPersonID], SUM([TotalDue])
FROM [Sales].[Big_SalesOrderHeader]
WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31'
GROUP BY [SalesPersonID];
GO
SELECT [SalesPersonID], SUM([TotalDue])
FROM [Sales].[Part_SalesOrderHeader]
WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31'
GROUP BY [SalesPersonID];
GO
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Big_SalesOrderHeader'. Scan count 9, logical reads 2710440, physical reads 2226, read-ahead reads 2658769, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Part_SalesOrderHeader'. Scan count 9, logical reads 248128, physical reads 3, read-ahead reads 245030, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.

Totals by Sales Person for December – Non-Partitioned Table
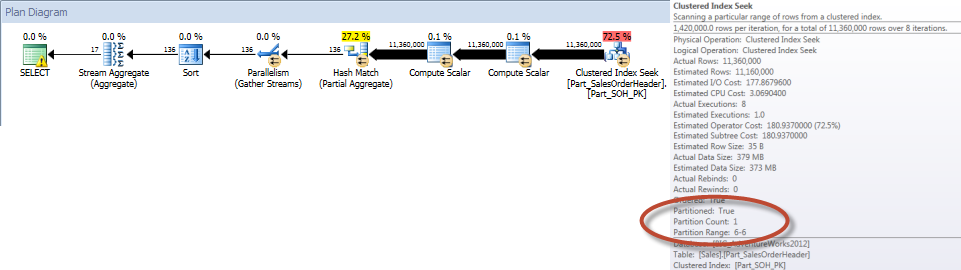
Totals by Sales Person for December – Partitioned Table
As expected, the query against the non-partitioned table had to perform a full scan of the table as there was no index to support it. In contrast, the query against the partitioned table only needed to access one partition of the table.
To be fair, if this was a query repeatedly executed with different date ranges, the appropriate nonclustered index would exist. For example:
CREATE NONCLUSTERED INDEX [Big_SalesOrderHeader_SalesPersonID]
ON [Sales].[Big_SalesOrderHeader] ([OrderDate]) INCLUDE ([SalesPersonID], [TotalDue]);
With this index created, when the query is re-executed, the I/O statistics drop and the plan changes to use the nonclustered index:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Big_SalesOrderHeader'. Scan count 9, logical reads 42901, physical reads 3, read-ahead reads 42346, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.

Totals by Sales Person for December – NCI on Non-Partitioned Table
With a supporting index, the query against Sales.Big_SalesOrderHeader requires significantly fewer reads than the clustered index scan against Sales.Part_SalesOrderHeader, which is not unexpected since the clustered index is much wider. If we create a comparable nonclustered index for Sales.Part_SalesOrderHeader, we see similar I/O numbers:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_SalesPersonID]
ON [Sales].[Part_SalesOrderHeader]([SalesPersonID]) INCLUDE ([TotalDue]);
Table 'Part_SalesOrderHeader'. Scan count 9, logical reads 42894, physical reads 1, read-ahead reads 42378, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
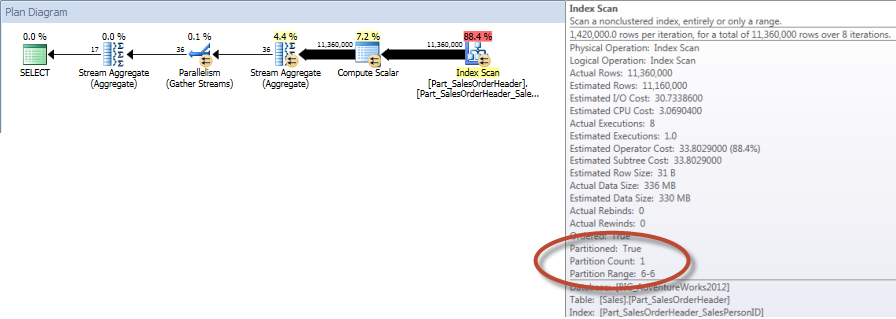
Totals by Sales Person for December – NCI on Partitioned Table with Elimination
And if we look at the properties of the nonclustered Index Scan, we can verify that the engine accessed only one partition (6).
As stated originally, partitioning is not typically implemented to improve performance. In the example shown above, the query against the partitioned table doesn’t perform significantly better as long as the appropriate nonclustered index exists.
Performance for an Ad-Hoc Query
A query against the partitioned table can outperform the same query against the non-partitioned table in some cases, for example when the query has to use the clustered index. While it’s ideal to have the majority of queries supported by nonclustered indexes, some systems allow ad-hoc queries from users, and others have queries that may run so infrequently they don’t warrant supporting indexes. Against the SalesOrderHeader table, a user might run the following query to find orders from December 2012 that needed to ship by the end of the year but didn’t, for a particular set of customers and with a TotalDue greater than $1000:
SELECT
[SalesOrderID],
[OrderDate],
[DueDate],
[ShipDate],
[AccountNumber],
[CustomerID],
[SalesPersonID],
[SubTotal],
[TotalDue]
FROM [Sales].[Big_SalesOrderHeader]
WHERE [TotalDue] > 1000
AND [CustomerID] BETWEEN 10000 AND 20000
AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31'
AND [DueDate] < '2012-12-31'
AND [ShipDate] > '2012-12-31';
GO
SELECT
[SalesOrderID],
[OrderDate],
[DueDate],
[ShipDate],
[AccountNumber],
[CustomerID],
[SalesPersonID],
[SubTotal],
[TotalDue]
FROM [Sales].[Part_SalesOrderHeader]
WHERE [TotalDue] > 1000
AND [CustomerID] BETWEEN 10000 AND 20000
AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31'
AND [DueDate] < '2012-12-31'
AND [ShipDate] > '2012-12-31';
GO
Table 'Big_SalesOrderHeader'. Scan count 9, logical reads 2711220, physical reads 8386, read-ahead reads 2662400, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Part_SalesOrderHeader'. Scan count 9, logical reads 248128, physical reads 0, read-ahead reads 243792, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
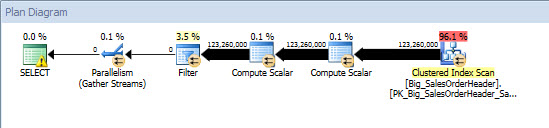
Ad-Hoc Query – Non-Partitioned Table
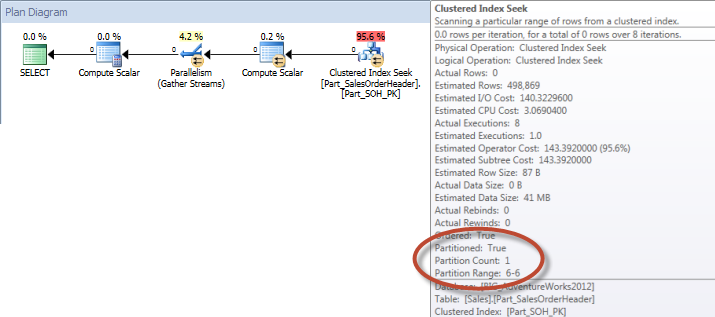
Ad-Hoc Query – Partitioned Table
Against the non-partitioned table the query required a full scan against the clustered index, but against the partitioned table, the query performed an index seek of the clustered index, as the engine used partition elimination and only read the data it absolutely needed. In this example, it’s a significant difference in terms of I/O, and depending on the hardware, could be a dramatic difference in execution time. The query could be optimized by adding the appropriate index, but it’s typically not feasible to index for every single query. In particular, for solutions that allow ad-hoc queries, it’s fair to say that you never know what users are going to do. A query may run once and never run again, and creating an index after the fact is futile. Therefore, when changing from a non-partitioned table to a partitioned table, it’s important to apply the same effort and approach as regular index tuning; you want to verify that the appropriate indexes exist to support the majority of queries.
Performance and Index Alignment
An additional factor to consider when creating indexes for a partitioned table is whether to align the index or not. Indexes must be aligned with the table if you’re planning to switch data in and out of partitions. Creating a nonclustered index on a partitioned table creates an aligned index by default, where the partitioning column is added as an included column to the index.
A non-aligned index is created by specifying a different partition scheme or a different filegroup. The partitioning column can be part of the index as a key column or an included column, but if the table’s partition scheme is not used, or a different filegroup is used, the index will not be aligned.
An aligned index is partitioned just like the table – the data will exist in separate structures – and therefore partition elimination can occur. An unaligned index exists as one physical structure, and may not provide the expected benefit for a query, depending on the predicate. Consider a query that does count of sales by account number, grouped by month:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber])
FROM [Sales].[Part_SalesOrderHeader]
WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31'
GROUP BY DATEPART(MONTH,[OrderDate])
ORDER BY DATEPART(MONTH,[OrderDate]);
If you’re not that familiar with partitioning, you might create an index like this to support the query (note that the PRIMARY filegroup is specified):
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_NotAL]
ON [Sales].[Part_SalesOrderHeader]([AccountNumber])
ON [PRIMARY];
This index is not aligned, even though it includes OrderDate because it’s part of the primary key. The columns are also included if we create an aligned index, but note the difference in syntax:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_AL]
ON [Sales].[Part_SalesOrderHeader]([AccountNumber]);
We can verify what columns exist in the index using Kimberly Tripp’s sp_helpindex:
EXEC sp_SQLskills_SQL2008_helpindex 'Sales.Part_SalesOrderHeader’;

sp_helpindex for Sales.Part_SalesOrderHeader
When we run our query and force it to use the non-aligned index, the entire index is scanned. Even though OrderDate is part of the index, it is not the leading column so the engine has to check the OrderDate value for every AccountNumber to see if it falls between January 1, 2013 and July 31, 2013:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber])
FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_NotAL]))
WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31'
GROUP BY DATEPART(MONTH,[OrderDate])
ORDER BY DATEPART(MONTH,[OrderDate]);
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Part_SalesOrderHeader'. Scan count 9, logical reads 786861, physical reads 1, read-ahead reads 770929, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
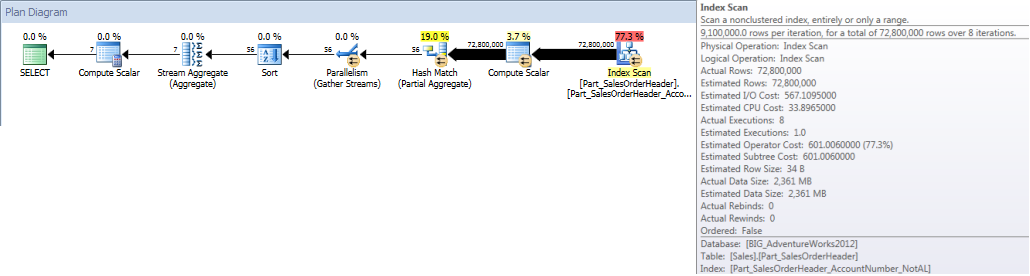
Account Totals by Month (January – July 2013) Using Non-Aligned NCI (forced)
In contrast, when the query is forced to use the aligned index, partition elimination can be used, and fewer I/Os are required, even though OrderDate is not a leading column in the index.
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber])
FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_AL]))
WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31'
GROUP BY DATEPART(MONTH,[OrderDate])
ORDER BY DATEPART(MONTH,[OrderDate]);
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Part_SalesOrderHeader'. Scan count 9, logical reads 456258, physical reads 16, read-ahead reads 453241, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
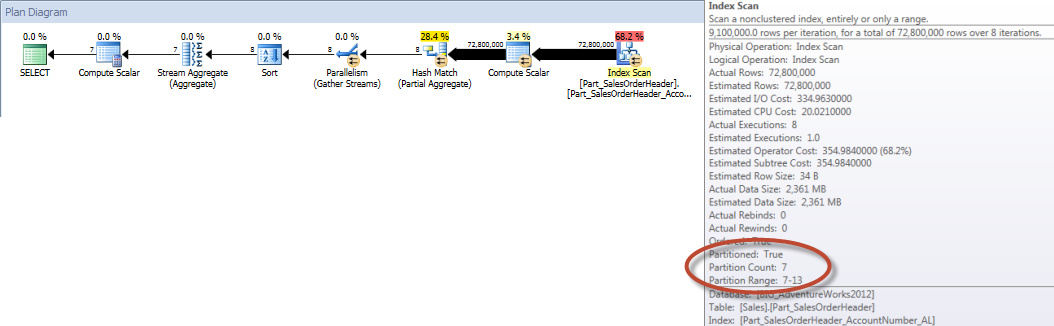
Account Totals by Month (January – July 2013) Using Aligned NCI (forced)
Summary
The decision to implement partitioning is one which requires due consideration and planning. Ease of management, improved scalability and availability, and a reduction in blocking are common reasons to partition tables. Improving query performance is not a reason to employ partitioning, though it can be a beneficial side-effect in some cases. In terms of performance, it is important to ensure that your implementation plan includes a review of query performance. Confirm that your indexes continue to appropriately support your queries after the table is partitioned, and verify that queries using the clustered and nonclustered indexes benefit from partition elimination where applicable.
1 thought on “Finding Performance Benefits with Partitioning”
Comments are closed.

Your clustered indexes are different and that is the reason for the different execution plans at the outset: it is not due to the partitioning. The first table [Big_SalesOrderHeader] is clustered by [SalesOrderID] but the second table [Part_SalesOrderHeader] is clustered by ([OrderDate], [SalesOrderID]). It is normal that the first plan must perform a scan operation in order to find all of the OrderDates scattered throughout the table in order to fulfill the predicate, but the second plan can perform a seek operation since the table is already sorted by OrderDate and the records are clustered together.
Your partitioning code in the download was helpful…