
Bucketizing date and time data
Bucketizing date and time data involves organizing data in groups representing fixed intervals of time for analytical purposes. Often the input is time series data stored in a table where the rows represent measurements taken at regular time intervals. For example, the measurements could be temperature and humidity readings taken every 5 minutes, and you want to group the data using hourly buckets and compute aggregates like average per hour. Even though time series data is a common source for bucket-based analysis, the concept is just as relevant to any data that involves date and time attributes and associated measures. For example, you might want to organize sales data in fiscal year buckets and compute aggregates like the total sales value per fiscal year. In this article, I cover two methods for bucketizing date and time data. One is using a function called DATE_BUCKET, which at the time of writing is only available in Azure SQL Edge. Another is using a custom calculation that emulates the DATE_BUCKET function, which you can use in any version, edition, and flavor of SQL Server and Azure SQL Database.
In my examples, I’ll use the sample database TSQLV5. You can find the script that creates and populates TSQLV5 here and its ER diagram here.
DATE_BUCKET
As mentioned, the DATE_BUCKET function is currently available only in Azure SQL Edge. SQL Server Management Studio already has IntelliSense support, as shown in Figure 1:
 Figure 1: Intellisence support for DATE_BUCKET in SSMS
Figure 1: Intellisence support for DATE_BUCKET in SSMS
The function’s syntax is as follows:
The input origin represents an anchor point on the arrow of time. It can be of any of the supported date and time data types. If unspecified, the default is 1900, January 1st, midnight. You can then imagine the timeline as being divided into discrete intervals starting with the origin point, where the length of each interval is based on the inputs bucket width and date part. The former is the quantity and the latter is the unit. For example, to organize the timeline in 2-month units, you would specify 2 as the bucket width input and month as the date part input.
The input timestamp is an arbitrary point in time that needs to be associated with its containing bucket. Its data type needs to match the data type of the input origin. The input timestamp is the date and time value associated with the measures you’re capturing.
The output of the function is then the starting point of the containing bucket. The data type of the output is that of the input timestamp.
If it wasn’t obvious already, usually you would use the DATE_BUCKET function as a grouping set element in the query’s GROUP BY clause and naturally return it in the SELECT list as well, along with aggregated measures.
Still a bit confused about the function, its inputs, and its output? Maybe a specific example with a visual depiction of the function’s logic would help. I’ll start with an example that uses input variables and later in the article demonstrate the more typical way you would use it as part of a query against an input table.
Consider the following example:
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210115 00:00:00';
SELECT DATE_BUCKET(month, @bucketwidth, @timestamp, @origin);
You can find a visual depiction of the function’s logic in Figure 2.
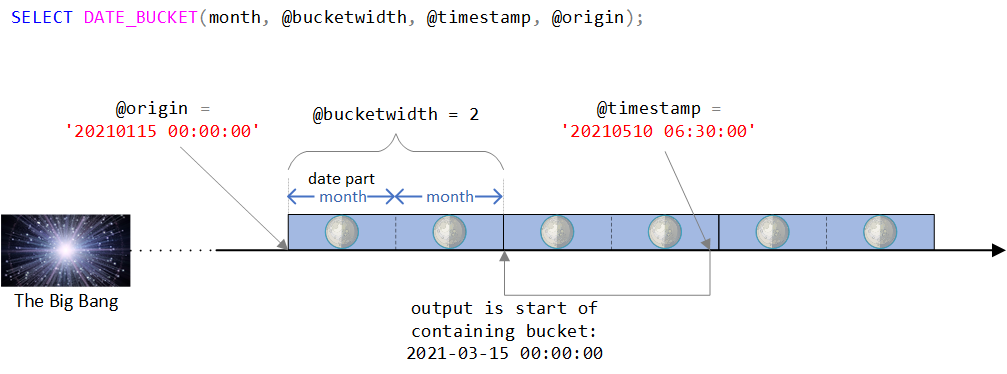 Figure 2: Visual depiction of the DATE_BUCKET function’s logic
Figure 2: Visual depiction of the DATE_BUCKET function’s logic
As you can see in Figure 2, the origin point is the DATETIME2 value January 15th, 2021, midnight. If this origin point seems a bit odd, you’d be right in intuitively sensing that normally you would use a more natural one like the beginning of some year, or the beginning of some day. In fact, you’d often be satisfied with the default, which as you recall is January 1st, 1900 at midnight. I intentionally wanted to use a less trivial origin point to be able to discuss certain complexities that might not be relevant when using a more natural one. More on this shortly.
The timeline is then divided into discrete 2-month intervals starting with the origin point. The input timestamp is the DATETIME2 value May 10th, 2021, 6:30 AM.
Observe that the input timestamp is part of the bucket that starts on March 15th, 2021, midnight. Indeed, the function returns this value as a DATETIME2-typed value:
--------------------------- 2021-03-15 00:00:00.0000000
Emulating DATE_BUCKET
Unless you’re using Azure SQL Edge, if you want to bucketize date and time data, for the time being you would need to create your own custom solution to emulate what the DATE_BUCKET function does. Doing so is not overly complex, but it’s not too simple either. Dealing with date and time data often involves tricky logic and pitfalls that you need to be careful about.
I’ll build the calculation in steps and use the same inputs I used with the DATE_BUCKET example I showed earlier:
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210115 00:00:00';
Make sure you include this part before each of the code samples I’ll show if you actually want to run the code.
In Step 1, you use the DATEDIFF function to compute the difference in date part units between origin and timestamp. I’ll refer to this difference as diff1. This is done with the following code:
SELECT DATEDIFF(month, @origin, @timestamp) AS diff1;
With our sample inputs, this expression returns 4.
The tricky part here is that you need to compute how many whole units of date part exist between origin and timestamp. With our sample inputs, there are 3 whole months between the two and not 4. The reason the DATEDIFF function reports 4 is that, when it computes the difference, it only looks at the requested part of the inputs and higher parts but not lower parts. So, when you ask for the difference in months, the function only cares about the year and month parts of the inputs and not about the parts below the month (day, hour, minute, second, etc.). Indeed, there are 4 months between January 2021 and May 2021, yet only 3 whole months between the full inputs.
The purpose of Step 2 then is to compute how many whole units of date part exist between origin and timestamp. I’ll refer to this difference as diff2. To achieve this, you can add diff1 units of date part to origin. If the result is greater than timestamp, you subtract 1 from diff1 to compute diff2, otherwise subtract 0 and therefore use diff1 as diff2. This can be done using a CASE expression, like so:
SELECT
DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END AS diff2;
This expression returns 3, which is the number of whole months between the two inputs.
Recall that earlier I mentioned that in my example I intentionally used an origin point that is not a natural one like a round beginning of a period so that I can discuss certain complexities that then might be relevant. For instance, if you use month as the date part, and the exact beginning of some month (1st of some month at midnight) as the origin, you can safely skip Step 2 and use diff1 as diff2. That’s because origin + diff1 can never be > timestamp in such a case. However, my goal is to provide a logically equivalent alternative to the DATE_BUCKET function that would work correctly for any origin point, common or not. So, I'll include the logic for Step 2 in my examples, but just remember when you identify cases where this step isn’t relevant, you can safely remove the part where you subtract the output of the CASE expression.
In Step 3 you identify how many units of date part there are in whole buckets that exist between origin and timestamp. I’ll refer to this value as diff3. This can be done with the following formula:
diff3 = diff2 / *
The trick here is that when using the division operator / in T-SQL with integer operands, you get integer division. For instance, 3 / 2 in T-SQL is 1 and not 1.5. The expression diff2 / <bucket width> gives you the number of whole buckets that exist between origin and timestamp (1 in our case). Multiplying the result by bucket width then gives you the number of units of date part that exist within those whole buckets (2 in our case). This formula translates to the following expression in T-SQL:
SELECT
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth AS diff3;
This expression returns 2, which is the number of months in the whole 2-month buckets that exist between the two inputs.
In Step 4, which is the final step, you add diff3 units of date part to origin to compute the start of the containing bucket. Here’s the code to achieve this:
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin);
This code generates the following output:
--------------------------- 2021-03-15 00:00:00.0000000
As you recall, this is the same output produced by the DATE_BUCKET function for the same inputs.
I suggest that you try this expression with various inputs and parts. I’ll show a few examples here, but feel free to try your own.
Here’s an example where origin is just slightly ahead of timestamp in the month:
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:01';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin);
This code generates the following output:
--------------------------- 2021-03-10 06:30:01.0000000
Notice that the start of the containing bucket is in March.
Here’s an example where origin is at the same point within the month as timestamp:
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:00';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin);
This code generates the following output:
--------------------------- 2021-05-10 06:30:00.0000000
Notice that this time the start of the containing bucket is in May.
Here’s an example with 4-week buckets:
DECLARE
@timestamp AS DATETIME2 = '20210303 21:22:11',
@bucketwidth AS INT = 4,
@origin AS DATETIME2 = '20210115';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
week,
( DATEDIFF(week, @origin, @timestamp)
- CASE
WHEN DATEADD(
week,
DATEDIFF(week, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin);
Notice that the code uses the week part this time.
This code generates the following output:
--------------------------- 2021-02-12 00:00:00.0000000
Here’s an example with 15-minute buckets:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF(minute, @origin, @timestamp)
- CASE
WHEN DATEADD(
minute,
DATEDIFF(minute, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin);
This code generates the following output:
--------------------------- 2021-02-03 21:15:00.0000000
Notice that the part is minute. In this example, you want to use 15-minute buckets starting at the bottom of the hour, so an origin point that is the bottom of any hour would work. In fact, an origin point that has a minute unit of 00, 15, 30 or 45 with zeros in lower parts, with any date and hour would work. So the default that the DATE_BUCKET function uses for the input origin would work. Of course, when using the custom expression, you have to be explicit about the origin point. So, to sympathize with the DATE_BUCKET function, you could use the base date at midnight like I do in the above example.
Incidentally, can you see why this would be a good example where it is perfectly safe to skip Step 2 in the solution? If you indeed chose to skip Step 2, you get the following code:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF( minute, @origin, @timestamp ) ) / @bucketwidth * @bucketwidth,
@origin
);
Clearly, the code becomes significantly simpler when Step 2 is not needed.
Grouping and aggregating data by date and time buckets
There are cases where you need to bucketize date and time data that don’t require sophisticated functions or unwieldy expressions. For example, suppose you want to query the Sales.OrderValues view in the TSQLV5 database, group the data yearly, and compute total order counts and values per year. Clearly, it’s enough to use the YEAR(orderdate) function as the grouping set element, like so:
USE TSQLV5;
SELECT
YEAR(orderdate) AS orderyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
GROUP BY YEAR(orderdate)
ORDER BY orderyear;
This code generates the following output:
orderyear numorders totalvalue ----------- ----------- ----------- 2017 152 208083.99 2018 408 617085.30 2019 270 440623.93
But what if you wanted to bucketize the data by your organization’s fiscal year? Some organizations use a fiscal year for accounting, budget, and financial reporting purposes, not aligned with the calendar year. Say, for instance, that your organization’s fiscal year operates on a fiscal calendar of October to September, and is denoted by the calendar year in which the fiscal year ends. So an event that took place on October 3rd , 2018 belongs to the fiscal year that started on October 1st, 2018, ended on September 30th, 2019, and is denoted by the year 2019.
This is quite easy to achieve with the DATE_BUCKET function, like so:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATE = '19001001'; -- this is Oct 1 of some year
SELECT
YEAR(startofbucket) + 1 AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket;
And here’s the code using the custom logical equivalent of the DATE_BUCKET function:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATE = '19001001'; -- this is Oct 1 of some year
SELECT
YEAR(startofbucket) + 1 AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket;
This code generates the following output:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2017 70 79728.58 2018 370 563759.24 2019 390 622305.40
I used variables here for the bucket width and the origin point to make the code more generalized, but you can replace those with constants if you’re always using the same ones, and then simplify the computation as appropriate.
As a slight variation of the above, suppose your fiscal year runs from July 15th of one calendar year to July 14th of the next calendar year, and is denoted by the calendar year that the beginning of the fiscal year belongs to. So an event that took place on July 18th, 2018 belongs to fiscal year 2018. An event that took place on July 14th, 2018 belongs to fiscal year 2017. Using the DATE_BUCKET function, you would achieve this like so:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATE = '19000715'; -- July 15 marks start of fiscal year
SELECT
YEAR(startofbucket) AS fiscalyear, -- no need to add 1 here
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket;
You can see the changes compared to the previous example in the comments.
And here’s the code using the custom logical equivalent to the DATE_BUCKET function:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATE = '19000715';
SELECT
YEAR(startofbucket) AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket;
This code generates the following output:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2016 8 12599.88 2017 343 495118.14 2018 479 758075.20
Obviously, there are alternative methods you could use in specific cases. Take the example before the last, where the fiscal year runs from October to September and denoted by the calendar year in which the fiscal year ends. In such a case you could use the following, much simpler, expression:
YEAR(orderdate) + CASE WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1 ELSE 0 END
And then your query would look like this:
SELECT
fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
YEAR(orderdate)
+ CASE
WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1
ELSE 0
END ) ) AS A(fiscalyear)
GROUP BY fiscalyear
ORDER BY fiscalyear;
However, if you want a generalized solution that would work in many more cases, and that you could parameterize, you would naturally want to use the more general form. If you have access to the DATE_BUCKET function, that’s great. If you don’t, you can use the custom logical equivalent.
Conclusion
The DATE_BUCKET function is quite a handy function that enables you to bucketize date and time data. It’s useful for handling time series data, but also for bucketizing any data that involves date and time attributes. In this article I explained how the DATE_BUCKET function works and provided a custom logical equivalent in case the platform you’re using doesn’t support it.

{kind=link}
Thanks for this Itzik, I wasn't yet aware of this function. I was, however, a bit surprised not to see any mention or consideration of standard data warehouse date (and time) dimensions (a la Kimball & Ross) – an incredibly common approach to bucketizing.
Hi Stuart, sure, this would be a great topic for an article in its own right. Here I mainly wanted to point out this specific function to give it some exposure, and to explain how to emulate it with a custom solution. The hope is to see it available some day in the more commonly used flavors of SQL Server. :)
Another great article. Emulations are always appreciated to help those that don't necessarily have the 'latest and greatest' tech. Thanks again.
Thanks John!
One frustration I often have with date/time data is that even though an index on datetime[2] is also ordered by hour, day, month etc a GROUP BY cannot leverage this in a stream aggregate without an unneeded sort.
Wonder if the DATE_BUCKET function is optimised to take advantage of any index here?
Hi Martin,
I hear you. I got a similar comment from Rob Farley.
I don't have access to an Azure SQL Edge instance to check, but frankly if much simpler date and time functions like YEAR are not optimized as order-preserving functions, I doubt that DATE_BUCKET is.
To add to the grouping frustration, it also pops up in window functions and classic gaps-and-islands. Made all the more painful by the fact that the compiler actually *has* a "Merge Interval" operator (takes a sorted input and merges overlapping or abutting ranges), but we can't use it explicitly.
This is not just an issue with dates, it also comes up in any kind of bucketing analysis.
Microsoft recently released the first public preview of SQL Server 2022, and it includes support for the DATE_BUCKET function. All examples with the DATE_BUCKET function in this article run successfully against SQL Server 2022 public preview (CTP 2.0).
Moreover, the optimization of this function can rely on index order where relevant. For example, when grouping by this function the optimizer can leverage a Stream Aggregate operator that relies on index order without the need for explicit sorting. This addresses Martin Smith's question on the matter. That's truly a pleasant surprise.