


SQL Server 2014 brought many new features that DBAs and developers looked forward to testing and using in their environments, such as the updatable clustered Columnstore index, Delayed Durability, and Buffer Pool Extensions. A feature not often discussed is incremental statistics. Unless you use partitioning, this isn’t a feature you can implement. But if you do have partitioned tables in your database, incremental statistics might have been something you were eagerly anticipating.
Note: Benjamin Nevarez covered some basics related to incremental statistics in his February 2014 post, SQL Server 2014 Incremental Statistics. And while not much has changed in how this feature works since his post and the April 2014 release, it seemed a good time to dig into how enabling incremental statistics can help with maintenance performance.
Incremental statistics are sometimes called partition-level statistics, and this is because for the first time, SQL Server can automatically create statistics that are specific to a partition. One of the previous challenges with partitioning was that, even though you could have 1 to n partitions for a table, there was only one (1) statistic which represented the data distribution across all of those partitions. You could create filtered statistics for the partitioned table – one statistic for each partition – to provide the query optimizer with better information about the distribution of data. But this was a manual process, and required a script to automatically create them for each new partition.
In SQL Server 2014, you use the STATISTICS_INCREMENTAL option to have SQL Server create those partition-level statistics automatically. However, these statistics are not used as you might think.
I mentioned previously that, prior to 2014, you could create filtered statistics to give the optimizer better information about the partitions. Those incremental statistics? They aren’t currently used by the optimizer. The query optimizer still just uses the main histogram that represents the entire table. (Post to come which will demonstrate this!)
So what’s the point of incremental statistics? If you assume that only data in the most recent partition is changing, then ideally you only update statistics for that partition. You can do this now with incremental statistics – and what happens is that information is then merged back into the main histogram. The histogram for the entire table will update without having to read through the entire table to update statistics, and this can help with performance of your maintenance tasks.
Setup
We’ll start with creating a partition function and scheme, and then a new table which we will partition. Note that I created a filegroup for each partition function as you might in a production environment. You can create the partition scheme on the same filegroup (e.g. PRIMARY) if you cannot easily drop your test database. Each filegroup is also a few GB in size, as we’re going to add almost 400 million rows.
USE [AdventureWorks2014_Partition];
GO
/* add filesgroups */
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011];
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012];
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013];
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014];
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015];
/* add files */
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE
(
FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf',
NAME = N'2011', SIZE = 1024MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB
) TO FILEGROUP [FG2011];
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE
(
FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf',
NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB
) TO FILEGROUP [FG2012];
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE
(
FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf',
NAME = N'2013', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB
) TO FILEGROUP [FG2013];
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE
(
FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf',
NAME = N'2014', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB
) TO FILEGROUP [FG2014];
ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE
(
FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf',
NAME = N'2015', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB
) TO FILEGROUP [FG2015];
/* create partition function */
CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime])
AS RANGE RIGHT FOR VALUES
(
'20110101', -- everything in 2011
'20120101', -- everything in 2012
'20130101', -- everything in 2013
'20140101', -- everything in 2014
'20150101' -- everything in 2015
);
GO
/* create partition scheme */
CREATE PARTITION SCHEME [OrderDateRangePScheme]
AS PARTITION [OrderDateRangePFN] TO
([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]);
GO
/* create the table */
CREATE TABLE [dbo].[Orders]
(
[PurchaseOrderID] [int] NOT NULL,
[EmployeeID] [int] NULL,
[VendorID] [int] NULL,
[TaxAmt] [money] NULL,
[Freight] [money] NULL,
[SubTotal] [money] NULL,
[Status] [tinyint] NOT NULL,
[RevisionNumber] [tinyint] NULL,
[ModifiedDate] [datetime] NULL,
[ShipMethodID] [tinyint] NULL,
[ShipDate] [datetime] NOT NULL,
[OrderDate] [datetime] NOT NULL,
[TotalDue] [money] NULL
) ON [OrderDateRangePScheme] (OrderDate);
Before we add the data, we’ll create the clustered index, and note that the syntax includes the WITH (STATISTICS_INCREMENTAL = ON) option:
/* add the clustered index and enable incremental stats */
ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK]
PRIMARY KEY CLUSTERED
(
[OrderDate],
[PurchaseOrderID]
)
WITH (STATISTICS_INCREMENTAL = ON)
ON [OrderDateRangePScheme] ([OrderDate]);
What’s interesting to note here is that if you look at the ALTER TABLE entry in MSDN, it does not include this option. You will only find it in the ALTER INDEX entry… but this works. If you want to follow the documentation to the letter, you would run:
/* add the clustered index and enable incremental stats */
ALTER TABLE [dbo].[Orders]
ADD CONSTRAINT [OrdersPK]
PRIMARY KEY CLUSTERED
(
[OrderDate],
[PurchaseOrderID]
)
ON [OrderDateRangePScheme] ([OrderDate]);
GO
ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON);
Once the clustered index has been created for the partition scheme, we’ll load in our data and then check to see how many rows exist per partition (note this takes over 7 minutes on my laptop, you may want to add fewer rows depending on how much storage (and time) you have available):
/* load some data */
SET NOCOUNT ON;
DECLARE @Loops SMALLINT = 0;
DECLARE @Increment INT = 5000;
WHILE @Loops < 10000 -- adjust this to increase or decrease the number
-- of rows in the table, 10000 = 40 millon rows
BEGIN
INSERT [dbo].[Orders]
( [PurchaseOrderID]
,[EmployeeID]
,[VendorID]
,[TaxAmt]
,[Freight]
,[SubTotal]
,[Status]
,[RevisionNumber]
,[ModifiedDate]
,[ShipMethodID]
,[ShipDate]
,[OrderDate]
,[TotalDue]
)
SELECT
[PurchaseOrderID] + @Increment
, [EmployeeID]
, [VendorID]
, [TaxAmt]
, [Freight]
, [SubTotal]
, [Status]
, [RevisionNumber]
, [ModifiedDate]
, [ShipMethodID]
, [ShipDate]
, [OrderDate]
, [TotalDue]
FROM [Purchasing].[PurchaseOrderHeader];
CHECKPOINT;
SET @Loops = @Loops + 1;
SET @Increment = @Increment + 5000;
END
/* Check to see how much data exists per partition */
SELECT
$PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number]
, MIN([o].[OrderDate]) AS [Min_Order_Date]
, MAX([o].[OrderDate]) AS [Max_Order_Date]
, COUNT(*) AS [Rows In Partition]
FROM [dbo].[Orders] AS [o]
GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate])
ORDER BY [Partition Number];
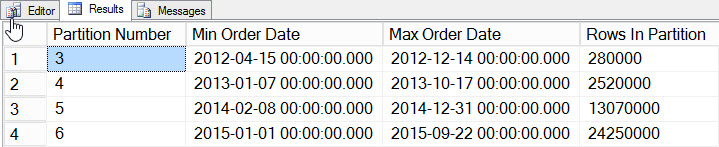 Data per partition
Data per partition
We’ve added data for 2012 through 2015, with significantly more data in 2014 and 2015. Let’s see what our statistics look like:
DBCC SHOW_STATISTICS ('dbo.Orders',[OrdersPK]);
 DBCC SHOW_STATISTICS output for dbo.Orders (click to enlarge)
DBCC SHOW_STATISTICS output for dbo.Orders (click to enlarge)
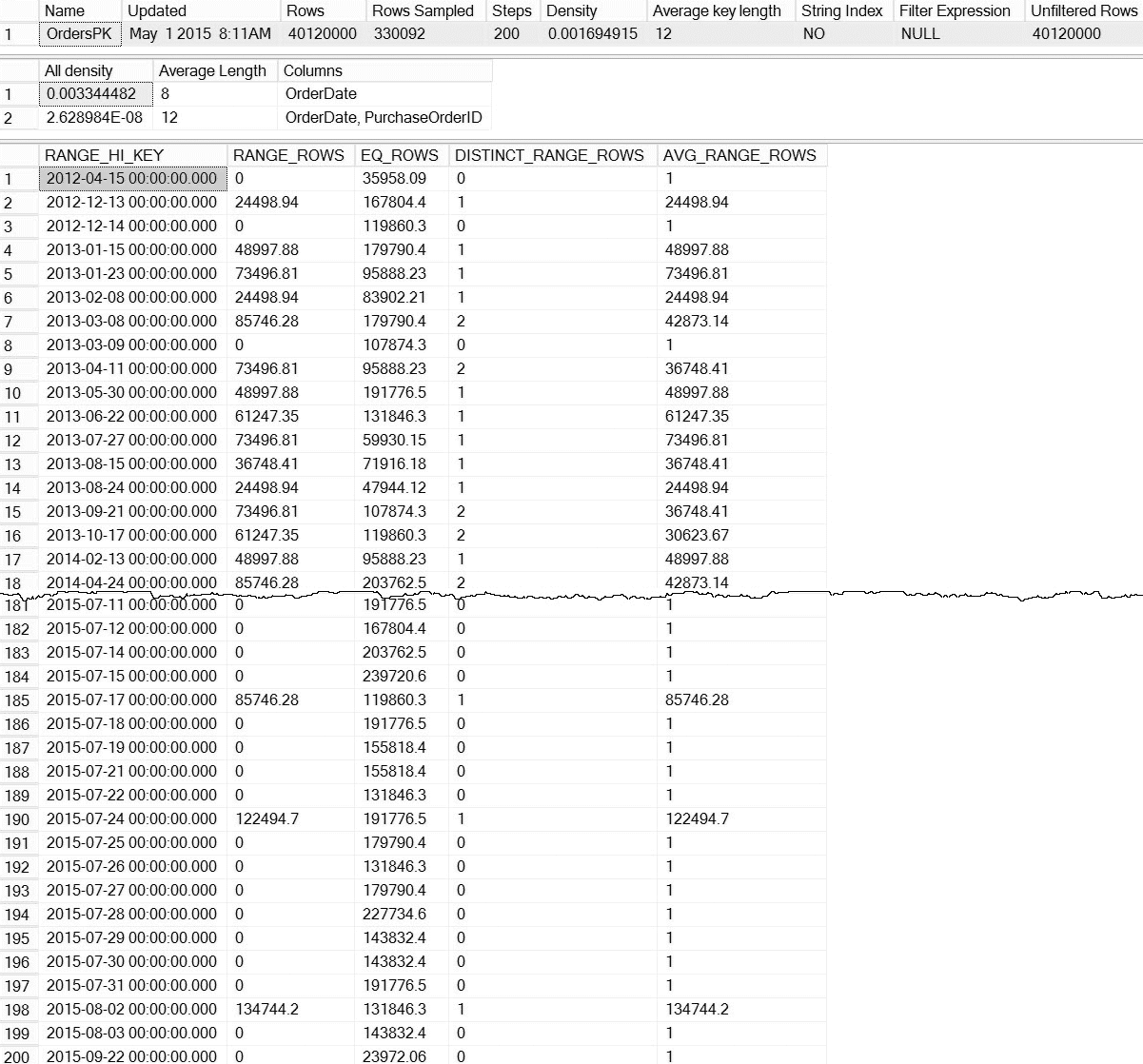
With the default DBCC SHOW_STATISTICS command, we don’t have any information about statistics at the partition level. Fear not; we are not completely doomed - there is an undocumented dynamic management function, sys.dm_db_stats_properties_internal. Remember that undocumented means it is not supported (there is no MSDN entry for the DMF), and that it can change at any time without any warning from Microsoft. That said, it’s a decent start for getting an idea of what exists for our incremental statistics:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 Histogram information from dm_db_stats_properties_internal (click to enlarge)
Histogram information from dm_db_stats_properties_internal (click to enlarge)
This is a lot more interesting. Here we can see proof that partition-level statistics (and more) exist. Because this DMF is not documented, we have to do some interpretation. For today, we’ll focus on the first seven rows in the output, where the first row represents the histogram for the entire table (note the rows value of 40 million), and the subsequent rows represent the histograms for each partition. Unfortunately, the partition_number value in this histogram does not line up with the partition number from sys.dm_db_index_physical_stats for right-based partitioning (it does correlate properly for left-based partitioning). Also note that this output also includes the last_updated and modification_counter columns, which are helpful when troubleshooting, and it can be used to develop maintenance scripts that intelligently update statistics based on age or row modifications.
Minimizing maintenance required
The primary value of incremental statistics at this time is the ability to update statistics for a partition and have those merge into the table-level histogram, without having to update the statistic for the entire table (and therefore read through the entire table). To see this in action, let’s first update statistics for the partition which holds the 2015 data, partition 5, and we’ll record the time taken and snapshot the sys.dm_io_virtual_file_stats DMF before and after to see how much I/O occurs:
SET STATISTICS TIME ON;
SELECT
fs.database_id, fs.file_id, mf.name, mf.physical_name,
fs.num_of_bytes_read, fs.num_of_bytes_written
INTO #FirstCapture
FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs
INNER JOIN sys.master_files AS mf
ON fs.database_id = mf.database_id
AND fs.file_id = mf.file_id;
UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH RESAMPLE ON PARTITIONS(6);
GO
SELECT
fs.database_id, fs.file_id, mf.name, mf.physical_name,
fs.num_of_bytes_read, fs.num_of_bytes_written
INTO #SecondCapture
FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs
INNER JOIN sys.master_files AS mf
ON fs.database_id = mf.database_id
AND fs.file_id = mf.file_id;
SELECT f.file_id, f.name, f.physical_name,
(s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read,
(s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written
FROM #FirstCapture AS f
INNER JOIN #SecondCapture AS s
ON f.database_id = s.database_id
AND f.file_id = s.file_id;
Output:
CPU time = 203 ms, elapsed time = 240 ms.
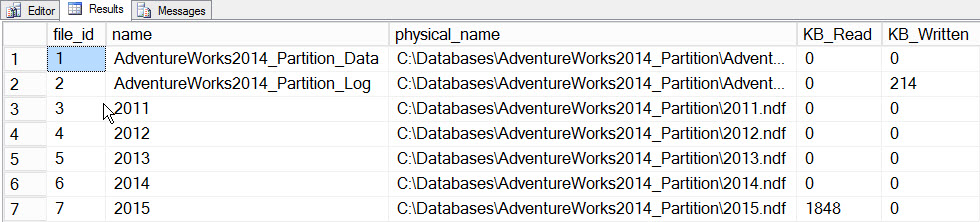 File_stats data after updating one partition
File_stats data after updating one partition
If we look at the sys.dm_db_stats_properties_internal output, we see that last_updated changed for both the 2015 histogram and the table-level histogram (as well as a few other nodes, which is for later investigation):
 Updated histogram information from dm_db_stats_properties_internal
Updated histogram information from dm_db_stats_properties_internal
Now we’ll update statistics with a FULLSCAN for the table, and we’ll snapshot file_stats before and after again:
SET STATISTICS TIME ON;
SELECT
fs.database_id, fs.file_id, mf.name, mf.physical_name,
fs.num_of_bytes_read, fs.num_of_bytes_written
INTO #FirstCapture2
FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs
INNER JOIN sys.master_files AS mf
ON fs.database_id = mf.database_id
AND fs.file_id = mf.file_id;
UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH FULLSCAN
SELECT
fs.database_id, fs.file_id, mf.name, mf.physical_name,
fs.num_of_bytes_read, fs.num_of_bytes_written
INTO #SecondCapture2
FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs
INNER JOIN sys.master_files AS mf
ON fs.database_id = mf.database_id
AND fs.file_id = mf.file_id;
SELECT
f.file_id, f.name, f.physical_name,
(s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read,
(s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written
FROM #FirstCapture2 AS f
INNER JOIN #SecondCapture2 AS s
ON f.database_id = s.database_id
AND f.file_id = s.file_id;
Output:
CPU time = 12720 ms, elapsed time = 13646 ms
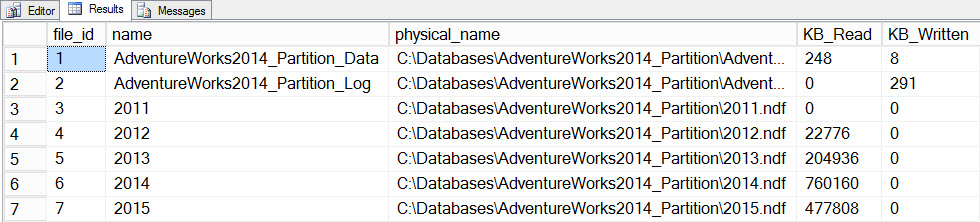 Filestats data after updating with a fullscan
Filestats data after updating with a fullscan
The update took significantly longer (13 seconds versus a couple hundred milliseconds) and generated a lot more I/O. If we check sys.dm_db_stats_properties_internal again, we find that last_updated changed for all the histograms:
 Histogram information from dm_db_stats_properties_internal after a fullscan
Histogram information from dm_db_stats_properties_internal after a fullscan
Summary
While incremental statistics are not yet used by the query optimizer to provide information about each partition, they do provide a performance benefit when managing statistics for partitioned tables. If statistics only need to be updated for select partitions, just those can be updated. The new information is then merged into the table-level histogram, providing the optimizer more current information, without the cost of reading the entire table. Going forward, we hope that those partition-level statistics will be used by the optimizer. Stay tuned…



Thanks for the great article, Erin. You've got me thinking about those rows 8-11 for your sys.dm_db_stats_properties_internal result set. Looking forward to a follow-up post giving us an insight into those rows.
Rows 8-11 are intermediate merge pages laid out in a hierarchy. They were probably more helpful before CU(5? I believe) when the partition_number column was provided. Look at node_id=8 (row 8). first_child in that row points us back to node_id=6 (row 6) which has 13,070,000 rows and next_sibling points us to node_id = 7 (row 7) which has 24,250,000 rows. When you add these two numbers together you get 37,320,000 which is also the row count for node_id = 8, the original parent with which we began.
It seems like creating incremental statistics would only have a positive effect on overall statistics, but is there any reason not to use this when designing a new partition scheme? Also, if you create indexes with STATISTICS_INCREMENTAL=ON, do you also need to enable incremental statistics at the database level to ensure that these incremental statistics are automatically updated?
Thank you and great article.