


In a recent thread on StackExchange, a user had the following issue:
I want a query that returns the first person in the table with a GroupID = 2. If nobody with a GroupID = 2 exists, I want the first person with a RoleID = 2.
Let's discard, for now, the fact that "first" is terribly defined. In actuality, the user didn't care which person they got, whether it came randomly, arbitrarily, or through some explicit logic in addition to their main criteria. Ignoring that, let's say you have a basic table:
CREATE TABLE dbo.Users
(
UserID INT PRIMARY KEY,
GroupID INT,
RoleID INT
);
In the real world there are probably other columns, additional constraints, maybe foreign keys to other tables, and certainly other indexes. But let's keep this simple, and come up with a query.
Likely Solutions
With that table design, solving the problem seems straightforward, right? The first attempt you would probably make is:
SELECT TOP (1) UserID, GroupID, RoleID
FROM dbo.Users
WHERE GroupID = 2 OR RoleID = 2
ORDER BY CASE GroupID WHEN 2 THEN 1 ELSE 2 END;
This uses TOP and a conditional ORDER BY to treat those users with a GroupID = 2 as higher priority. The plan for this query is pretty simple, with most of the cost happening in a sort operation. Here are runtime metrics against an empty table:
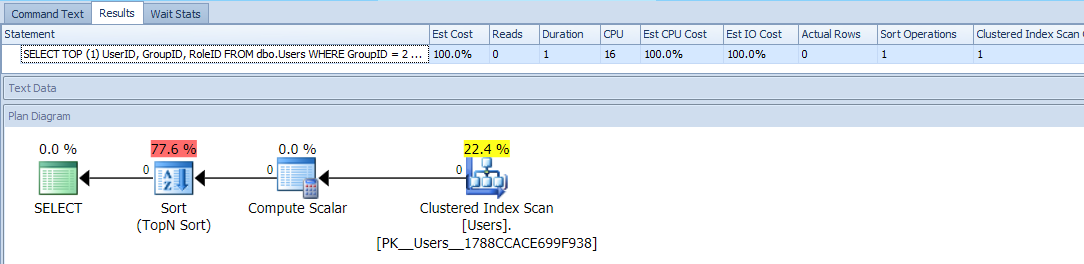
This looks to be about as good as you can do – a simple plan that only scans the table once, and other than a pesky sort that you should be able to live with, no problem, right?
Well, another answer in the thread offered up this more complex variation:
SELECT TOP (1) UserID, GroupID, RoleID FROM
(
SELECT TOP (1) UserID, GroupID, RoleID, o = 1
FROM dbo.Users
WHERE GroupId = 2
UNION ALL
SELECT TOP (1) UserID, GroupID, RoleID, o = 2
FROM dbo.Users
WHERE RoleID = 2
)
AS x ORDER BY o;
On first glance, you would probably think that this query is extremely less efficient, as it requires two clustered index scans. You'd definitely be right about that; here is the plan and runtime metrics against an empty table:
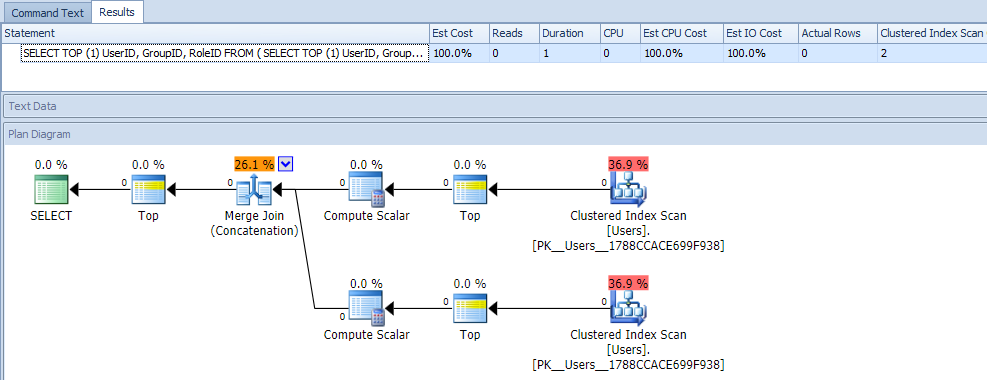
But now, let's add data
In order to test these queries, I wanted to use some realistic data. So first I populated 1,000 rows from sys.all_objects, with modulo operations against the object_id to get some decent distribution:
INSERT dbo.Users(UserID, GroupID, RoleID)
SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 7, ABS([object_id]) % 4
FROM sys.all_objects
ORDER BY [object_id];
SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 126
SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 248
SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 26 overlap
Now when I run the two queries, here are the runtime metrics:

The UNION ALL version comes in with slightly less I/O (4 reads vs. 5), lower duration, and lower estimated overall cost, while the conditional ORDER BY version has lower estimated CPU cost. The data here is pretty small to make any conclusions about; I just wanted it as a stake in the ground. Now, let's change the distribution so that most rows meet at least one of the criteria (and sometimes both):
DROP TABLE dbo.Users;
GO
CREATE TABLE dbo.Users
(
UserID INT PRIMARY KEY,
GroupID INT,
RoleID INT
);
GO
INSERT dbo.Users(UserID, GroupID, RoleID)
SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 2 + 1,
SUBSTRING(RTRIM([object_id]),7,1) % 2 + 1
FROM sys.all_objects
WHERE ABS([object_id]) > 9999999
ORDER BY [object_id];
SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 500
SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 475
SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 221 overlap
This time, the conditional order by has the highest estimated costs in both CPU and I/O:

But again, at this data size, there is relatively inconsequential impact to duration and reads, and aside from the estimated costs (which are largely made up anyway), it is hard to declare a winner here.
So, let's add a lot more data
While I rather enjoy building sample data from the catalog views, since everybody has those, this time I'm going to draw on the table Sales.SalesOrderHeaderEnlarged from AdventureWorks2012, expanded using this script from Jonathan Kehayias. On my system, this table has 1,258,600 rows. The following script will insert a million of those rows into our dbo.Users table:
-- DROP and CREATE, as before
INSERT dbo.Users(UserID, GroupID, RoleID)
SELECT TOP (1000000) SalesOrderID, SalesOrderID % 7, SalesOrderID % 4
FROM Sales.SalesOrderHeaderEnlarged;
SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 142,857
SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 250,000
SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 35,714 overlap
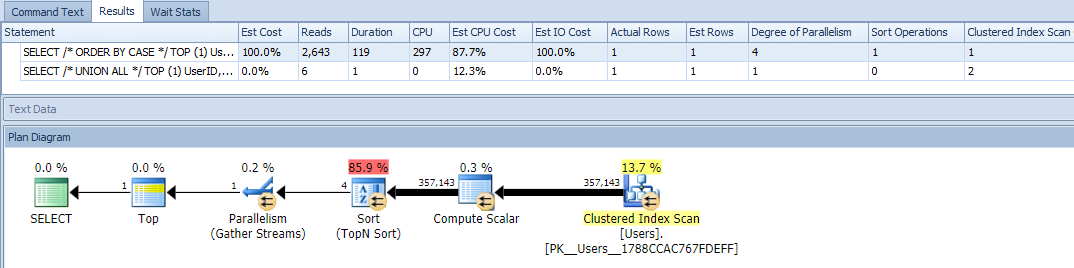
Okay, now when we run the queries, we see a problem: the ORDER BY variation has gone parallel and has obliterated both reads and CPU, yielding a nearly 120X difference in duration:
Eliminating parallelism (using MAXDOP) did not help:
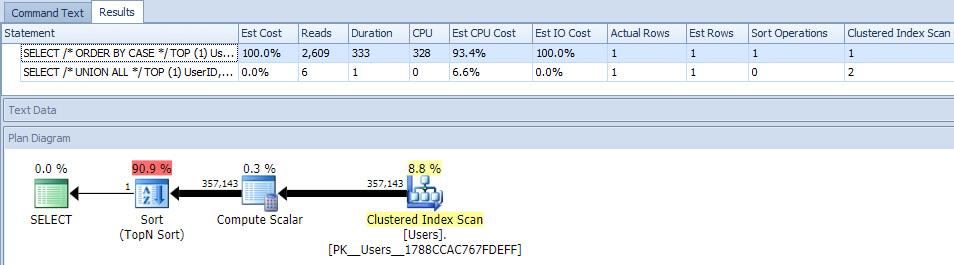
(The UNION ALL plan still looks the same.)
And if we change the skew to be even, where 95% of the rows meet at least one criteria:
-- DROP and CREATE, as before
INSERT dbo.Users(UserID, GroupID, RoleID)
SELECT TOP (475000) SalesOrderID, 2, SalesOrderID % 7
FROM Sales.SalesOrderHeaderEnlarged
WHERE SalesOrderID % 2 = 1
UNION ALL
SELECT TOP (475000) SalesOrderID, SalesOrderID % 7, 2
FROM Sales.SalesOrderHeaderEnlarged
WHERE SalesOrderID % 2 = 0;
INSERT dbo.Users(UserID, GroupID, RoleID)
SELECT TOP (50000) SalesOrderID, 1, 1
FROM Sales.SalesOrderHeaderEnlarged AS h
WHERE NOT EXISTS (SELECT 1 FROM dbo.Users
WHERE UserID = h.SalesOrderID);
SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 542,851
SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 542,851
SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 135,702 overlap
The queries still show that the sort is prohibitively expensive:

And with MAXDOP = 1 it was much worse (just look at duration):

Finally, how about 95% skew in either direction (e.g. most rows satisfy the GroupID criteria, or most rows satisfy the RoleID criteria)? This script will ensure at least 95% of the data has GroupID = 2:
-- DROP and CREATE, as before
INSERT dbo.Users(UserID, GroupID, RoleID)
SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7
FROM Sales.SalesOrderHeaderEnlarged;
INSERT dbo.Users(UserID, GroupID, RoleID)
SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2
FROM Sales.SalesOrderHeaderEnlarged AS h
WHERE NOT EXISTS (SELECT 1 FROM dbo.Users
WHERE UserID = h.SalesOrderID);
SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 957,143
SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 185,714
SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Results are quite similar (I'm just going to stop trying the MAXDOP thing from now on):

And then if we skew the other way, where at least 95% of the data has RoleID = 2:
-- DROP and CREATE, as before
INSERT dbo.Users(UserID, GroupID, RoleID)
SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7
FROM Sales.SalesOrderHeaderEnlarged;
INSERT dbo.Users(UserID, GroupID, RoleID)
SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2
FROM Sales.SalesOrderHeaderEnlarged AS h
WHERE NOT EXISTS (SELECT 1 FROM dbo.Users
WHERE UserID = h.SalesOrderID);
SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 185,714
SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 957,143
SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Results:

Conclusion
In not one single case that I could manufacture did the "simpler" ORDER BY query – even with one less clustered index scan – outperform the more complex UNION ALL query. Sometimes you have to be very wary about what SQL Server has to do when you introduce operations like sorts into your query semantics, and not rely on simplicity of the plan alone (never mind any bias you might have based on previous scenarios).
Your first instinct might often be correct, but I bet there are times when there is a better option that looks, on the surface, like it couldn't possibly work out better. As in this example. I'm getting quite a bit better about questioning assumptions I've made from observations, and not making blanket statements like "scans never perform well" and "simpler queries always run faster." If you eliminate the words never and always from your vocabulary, you may find yourself putting more of those assumptions and blanket statements to the test, and ending up much better off.



It is nice that SQL Server understands your sort-by-constant trick to make the union-all order defined.
> In not one single case that I could manufacture did the "simpler" ORDER BY query – even with one less clustered index scan – outperform the more complex UNION ALL query.
It is possible, just a bit unlikely. Taking it to the extreme, the worst case for the `UNION ALL` is when the only record that matches is the last one to be tested. In this case, that would be a single record for RoleID = 2:
The `UNION ALL` ends up scanning the table twice, while the `ORDER BY CASE` scans once, with a Top 1 Sort. On my laptop, the data set above runs for ~120ms for `ORDER BY CASE` and ~240ms for the `UNION ALL`.
The `UNION ALL` is still very preferable for non-pathological cases though.
I love this blog. It's basically one of the best blogs out there. Aaron Bertrand is wicked smart for a Canadian. "Solving the problem seems straightforward", Aaron says… umm… I didn't even understand the question. I miss you, buddy!
Sup Hanny! Where are you?
I'm in Providence. I was referencing something on stack overflow because I was helping someone with a problem… I saw some stuff that answered my question but that I had no chance of understanding. It wasn't until I clicked to another page that I thought "did that say Aaron Bertrand, the man responsible for me having a Herman Miller Chair?". Indeed it was and then I after being astonished by your reputation on stack exchange, I used my mad skills to hunt you down. After an exhaustive search, I found you right here in Rhode Island with me. Needless to say, I was extremely excited and a little bit jealous that you talk even more over my head than I remember.