
Partitioning on a Budget
Last year, I presented a solution to simulate Availability Group readable secondaries without investing in Enterprise Edition. Not to stop people from buying Enterprise Edition, as there are a lot of benefits outside of AGs, but more so for those that have no chance of ever having Enterprise Edition in the first place:
I try to be a relentless advocate for the Standard Edition customer; it is almost a running joke that surely – given the number of features it gets in each new release – that edition as a whole is on the deprecation path. In private meetings with Microsoft I have pushed for features to also be included in Standard Edition, especially with features that are much more beneficial to small businesses than those with unlimited hardware budget.
Enterprise Edition customers enjoy the manageability and performance benefits offered by table partitioning, but this feature is not available in Standard Edition. An idea struck me recently that there is a way to achieve at least some of partitioning's upsides on any edition, and it doesn't involve partitioned views. This is not to say that partitioned views are not a viable option worth considering; these are described well by others, including Daniel Hutmacher (Partitioned views over table partitioning) and Kimberly Tripp (Partitioned Tables v. Partitioned Views–Why are they even still around?). My idea is just a little simpler to implement.
Your New Hero: Filtered Indexes
Now, I know, this feature is a four-letter word to some; before you go any further, you should be happily comfortable with filtered indexes, or at least aware of their limitations. Some reading to give you some fair balance before I try to sell you on them:
- I talk about several shortcomings in How filtered indexes could be a more powerful feature, and point out plenty of Connect items for you to vote up;
- Paul White (@SQL_Kiwi) talks about tuning problems in Optimizer Limitations with Filtered Indexes and also in An Unexpected Side-Effect of Adding a Filtered Index; and,
- Jes Borland (@grrl_geek) tells us What You Can (and Can't) Do With Filtered Indexes.
Read all those? And you're still here? Great.
The TL;DR of this is that you can use filtered indexes to keep all of your "hot data" in a separate physical structure, and even on separate underlying hardware (you may have a fast SSD or PCIe drive available, but it can't hold the whole table).
A Quick Example
There are many use cases where a portion of the data is queried much more frequently than the rest – think of a retail store managing orders, a bakery scheduling wedding cake deliveries, or a football stadium measuring attendance and concession data. In these cases, most or all of the everyday query activity is concerned with "current" data.
Let's keep it simple; we'll create a database with a very narrow Orders table:
CREATE DATABASE PoorManPartition;
GO
USE PoorManPartition;
GO
CREATE TABLE dbo.Orders
(
OrderID INT IDENTITY(1,1) PRIMARY KEY,
OrderDate DATE NOT NULL DEFAULT SYSUTCDATETIME(),
OrderTotal DECIMAL(8,2) --, ...other columns...
);
Now, let's say you have enough space on your fast storage to keep a month of data (with plenty of headroom to account for seasonality and future growth). We can add a new filegroup, and place a data file on the fast drive.
ALTER DATABASE PoorManPartition ADD FILEGROUP HotData;
GO
ALTER DATABASE PoorManPartition ADD FILE
(
Name = N'HotData',
FileName = N'Z:\folder\HotData.mdf',
Size = 100MB,
FileGrowth = 25MB
)
TO FILEGROUP HotData;
Now, let's create a filtered index on our HotData filegroup, where the filter includes everything from the beginning of November 2015, and the common columns involved in time-based queries are in the key or include list:
CREATE INDEX FilteredIndex
ON dbo.Orders(OrderDate)
INCLUDE(OrderTotal)
WHERE OrderDate >= '20151101'
AND OrderDate < '20151201'
ON HotData;
We can insert a few rows and check the execution plan to be sure that covered queries can, in fact, use the index:
INSERT dbo.Orders(OrderDate) VALUES('20151001'),('20151103'),('20151127');
GO
SELECT index_id, rows
FROM sys.partitions
WHERE object_id = OBJECT_ID(N'dbo.Orders');
/*
Results:
index_id rows
-------- ----
1 3
2 2
*/
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151102'
AND OrderDate < '20151106';
The resulting execution plan, sure enough, uses the filtered index (even though the filter predicate in the query does not match the index definition exactly):
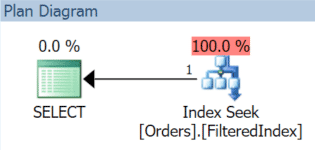
Now, December 1st rolls around, and it's time to swap out our November data and replace it with December. We can just re-create the filtered index with a new filter predicate, and use the DROP_EXISTING option:
CREATE INDEX FilteredIndex
ON dbo.Orders(OrderDate)
INCLUDE(OrderTotal)
WHERE OrderDate >= '20151201'
AND OrderDate < '20160101'
WITH (DROP_EXISTING = ON)
ON HotData;
Now, we can add a few more rows, check the partition stats, and run our previous query and a new one to check the indexes used:
INSERT dbo.Orders(OrderDate) VALUES('20151202'),('20151205');
GO
SELECT index_id, rows
FROM sys.partitions
WHERE object_id = OBJECT_ID(N'dbo.Orders');
/*
Results:
index_id rows
-------- ----
1 5
2 2
*/
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151102'
AND OrderDate < '20151106';
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151202'
AND OrderDate < '20151204';
In this case we get a clustered index scan with the November query:
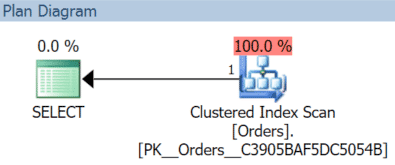
(But that would be different if we had a separate, non-filtered index with OrderDate as the key.)
And I won't show it again, but with the December query, we get the same filtered index seek as before.
You could also maintain multiple indexes, one for the current month, one for the previous month, and so on, and you can just manage them separately (on December 1st you just drop the index from October, and leave November's alone, for example). You could also maintain multiple indexes of shorter or longer time spans (current and previous week, current and previous quarter), etc. The solution is pretty flexible.
Due to the limitations of filtered indexes, I will not try to push this as a perfect solution, nor a complete replacement for table partitioning or partitioned views. Switching out a partition, for example, is a metadata operation, while re-creating an index with DROP_EXISTING can have a lot of logging (and since you're not on Enterprise Edition, can't be run online). You may also find that partitioned views are more your speed - there is more work around maintaining separate physical tables and the constraints that make the partitioned view possible, but the payoff in terms of query performance might be better in some cases.
Automation
The act of re-creating the index can be automated quite easily, using a simple job that does something like this once a month (or whatever your "hot" window size is):
DECLARE @sql NVARCHAR(MAX),
@dt DATE = DATEADD(DAY, 1-DAY(GETDATE()), GETDATE());
SET @sql = N'CREATE INDEX FilteredIndex
ON dbo.Orders(OrderDate)
INCLUDE(OrderTotal)
WHERE OrderDate >= ''' + CONVERT(CHAR(8), @dt, 112) + N'''
WITH (DROP_EXISTING = ON)
ON HotData;';
EXEC PoorManPartition.sys.sp_executesql @sql;
You could also be creating multiple indexes months in advance, much like creating future partitions in advance - after all, the future indexes won't occupy any space until there is data relevant to their predicates. And you can just drop the indexes that were segmenting the older data that you now want to become cold.
Hindsight
After I finished this article, of course, I came across another of Kimberly Tripp's posts, that you should read before proceeding with anything I'm advocating here (and which I had read before I started):
For multiple reasons, Kimberly is much more in favor of partitioned views to implement something similar to partitioning in Standard Edition; however, for certain scenarios, the use of filtered indexes still intrigues me enough to continue with my experimentation. One of the areas where filtered indexes can be beneficial is when your "hot" data has multiple criteria - not just sliced by date, but also by other attributes (maybe you want quick queries against all orders from this month that are for a specific tier of customer or above a certain dollar amount).
Up Next...
In a future post, I'll play with this concept on a higher-end system, with some real-world volume and workload. I want to discover performance differences between this solution, a non-filtered covering index, a partitioned view, and a partitioned table. Inside a VM on a laptop with only SSDs available would probably not yield realistic or fair tests at scale.
6 thoughts on “Partitioning on a Budget”
Comments are closed.

On the topic of the various editions of SQL Server, I don't understand why there are even editions of SQL Server. It seems to me that everyone would benefit if there was one edition whose license-fee was charged by the amount of RAM allocated to the instance ( In-Memory-OLTP excepted) — free up to 1GB and then on a scale upwards as the amount increases. It makes scability much easier. It makes all features of SQL Server immediately available and allows small companies to expand their DB-servers without having to re-install from one edition to the next.
Yes, I agree, there are definitely benefits to that approach, and it is largely how it works in Azure SQL DB. You'll have to ask Microsoft why it hasn't happened yet for the box product.
Aaron,
"I try to be a relentless advocate for the Standard Edition customer" – bravo! That role, and the ideas like the one presented here are really important, and appreciated. Hope you'll continue to lead the charge, you're doing good.
Andy
Nice one Aaron. Storage-tiering makes interesting point (quite often main reason behind partitioning by the way). You could expand your idea to indexed views with NOEXPAND. In both cases edition-constrained buffer pool size can hurt.
I have developed a fairly extensive semi-automated implementation of "Update-able Partitioned Views". We have a number of tables that receive a huge volume of data that we need to retain for between 30 days and 2 years. The largest receives 2.3B Rows/450GB per week and several are in the 200M Row/40GB per week range.
The overhead deleting the old data was killing us. Just the I/O was (is) bad enough but the blocking was unmanageable.
It took a little work to come up with a good set of tools to manage the partitioned views but we have been very satisfied with the results and have extended the concept to many other tables.
Kimberly's article is a good start on the requirements. Technet and MSDN also have good guidance.
While I'd love to see it too, let's be realistic about what could happen next. Hint – nowadays hardware is cheap. So at least for certain type of workloads, people will install that free & feature-full version on many cheap computers and then connect them in a clever way to the application middle-tier and essentially end up having distributed back-end serving the same purpose as the Standard or Enterprise Edition for free (almost) and Microsoft will get nothing. Currently one won't go too far using Express Edition that way since the absence of many interesting features like SQL Server Agent will make it much more limited/less flexible.
Aaron, nice article (as always) and I also wanted to thank you and the others for discussing interesting topics at sqlperformance.com which is one of my favorite sites.
Varsham Papikian