


Like any programming language, T-SQL has its share of common bugs and pitfalls, some of which cause incorrect results and others cause performance problems. In many of those cases, there are best practices that can help you avoid getting into trouble. I surveyed fellow Microsoft Data Platform MVPs asking about the bugs and pitfalls that they see often or that they just find to be particularly interesting, and the best practices that they employ to avoid those. I got lots of interesting cases.
Many thanks to Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser and Chan Ming Man for sharing your knowledge and experience!
This article is the first in a series on the topic. Each article focuses on a certain theme. This month I focus on bugs, pitfalls and best practices that are related to determinism. A deterministic calculation is one that is guaranteed to produce repeatable results given the same inputs. There are many bugs and pitfalls that result from the use of nondeterministic calculations. In this article I cover the implications of using nondeterministic order, nondeterministic functions, multiple references to table expressions with nondeterministic calculations, and the use of CASE expressions and the NULLIF function with nondeterministic calculations.
I use the sample database TSQLV5 in many of the examples in this series.
Nondeterministic order
One common source for bugs in T-SQL is the use of nondeterministic order. That is, when your order by list doesn’t uniquely identify a row. It could be presentation ordering, TOP/OFFSET-FETCH ordering or window ordering.
Take for example a classic paging scenario using the OFFSET-FETCH filter. You need to query the Sales.Orders table returning one page of 10 rows at a time, ordered by orderdate, descending (most recent first). I’ll use constants for the offset and fetch elements for simplicity, but typically they are expressions that are based on input parameters.
The following query (call it Query 1) returns the first page of 10 most-recent orders:
USE TSQLV5;
SELECT orderid, orderdate, custid
FROM Sales.Orders
ORDER BY orderdate DESC
OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY;
The plan for Query 1 is shown in Figure 1.
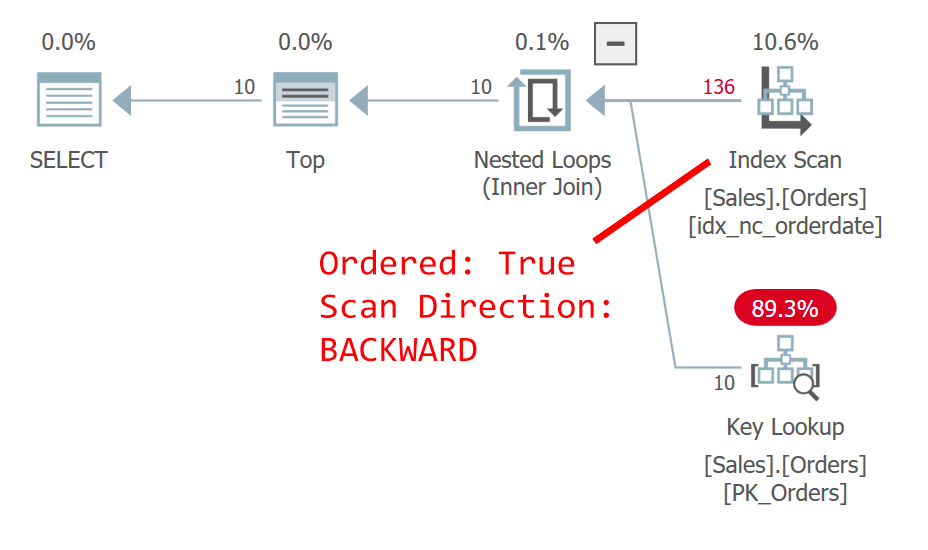 Figure 1: Plan for query 1
Figure 1: Plan for query 1
The query orders the rows by orderdate, descending. The orderdate column doesn’t uniquely identify a row. This nondeterministic order means that conceptually, there’s no preference between the rows with the same date. In case of ties, what determines which row SQL Server will prefer are things like plan choices and physical data layout—not something that you can rely on as being repeatable. The plan in Figure 1 scans the index on orderdate ordered backward. It so happens that this table has a clustered index on orderid, and in a clustered table the clustered index key is used as a row locator in nonclustered indexes. It actually gets implicitly positioned as the last key element in all nonclustered indexes even though theoretically SQL Server could have placed it in the index as an included column. So, implicitly, the nonclustered index on orderdate is actually defined on (orderdate, orderid). Consequently, in our ordered backward scan of the index, between tied rows based on orderdate, a row with a higher orderid value is accessed before a row with a lower orderid value. This query generates the following output:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 *** 11068 2019-05-04 62
Next, use the following query (call it Query 2) to get the second page of 10 rows:
SELECT orderid, orderdate, custid
FROM Sales.Orders
ORDER BY orderdate DESC
OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
The plan for Query is shown in Figure 2.
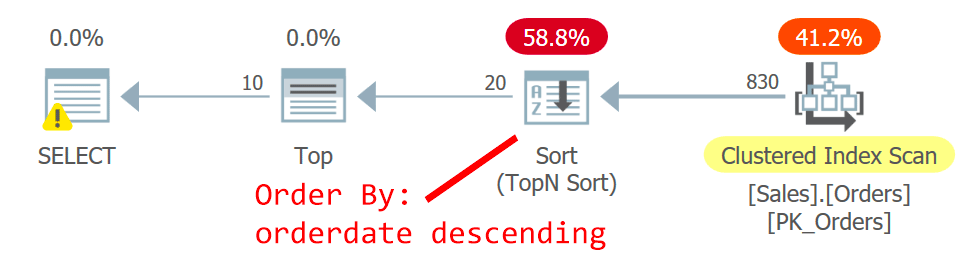
Figure 2: Plan for query 2
The optimizer chooses a different plan—one the scans the clustered index in an unordered fashion, and uses a TopN Sort to support the Top operator’s request to handle the offset-fetch filter. The reason for the change is that the plan in Figure 1 uses a nonclustered noncovering index, and the farther the page you’re after, the more lookups are required. With the second page request, you crossed the tipping point that justifies using the noncovering index.
Even though the scan of the clustered index, which is defined with orderid as the key, is an unordered one, the storage engine employs an index order scan internally. This has to do with the size of the index. Up to 64 pages the storage engine generally prefers index order scans to allocation order scans. Even if the index was bigger, under the read committed isolation level and data that is not marked as read only, the storage engine uses an index order scan to avoid double-reading and skipping of rows as a result of page splits that occur during the scan. Under the given conditions, in practice, between rows with the same date, this plan accesses a row with a lower orderid before one with a higher orderid.
This query generates the following output:
orderid orderdate custid ----------- ---------- ----------- 11069 2019-05-04 80 *** 11064 2019-05-01 71 11065 2019-05-01 46 11066 2019-05-01 89 11060 2019-04-30 27 11061 2019-04-30 32 11062 2019-04-30 66 11063 2019-04-30 37 11057 2019-04-29 53 11058 2019-04-29 6
Observe that even though the underlying data didn’t change, you ended up with the same order (with order ID 11069) returned in both the first and the second pages!
Hopefully, the best practice here is clear. Add a tiebreaker to your order by list to get a deterministic order. For instance, order by orderdate descending, orderid descending.
Try again asking for the first page, this time with a deterministic order:
SELECT orderid, orderdate, custid
FROM Sales.Orders
ORDER BY orderdate DESC, orderid DESC
OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY;
You get the following output, guaranteed:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 11068 2019-05-04 62
Ask for the second page:
SELECT orderid, orderdate, custid
FROM Sales.Orders
ORDER BY orderdate DESC, orderid DESC
OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
You get the following output, guaranteed:
orderid orderdate custid ----------- ---------- ----------- 11067 2019-05-04 17 11066 2019-05-01 89 11065 2019-05-01 46 11064 2019-05-01 71 11063 2019-04-30 37 11062 2019-04-30 66 11061 2019-04-30 32 11060 2019-04-30 27 11059 2019-04-29 67 11058 2019-04-29 6
As long as there were no changes in the underlying data, you’re guaranteed to get consecutive pages with no repetitions or skipping of rows between the pages.
In a similar manner, using window functions like ROW_NUMBER with nondeterministic order, you could get different results for the same query depending on the plan shape and actual access order among ties. Consider the following query (call it Query 3), implementing the first page request using row numbers (forcing the use of the index on orderdate for illustration purposes):
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders WITH (INDEX(idx_nc_orderdate))
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10;
The plan for this query is shown in Figure 3:
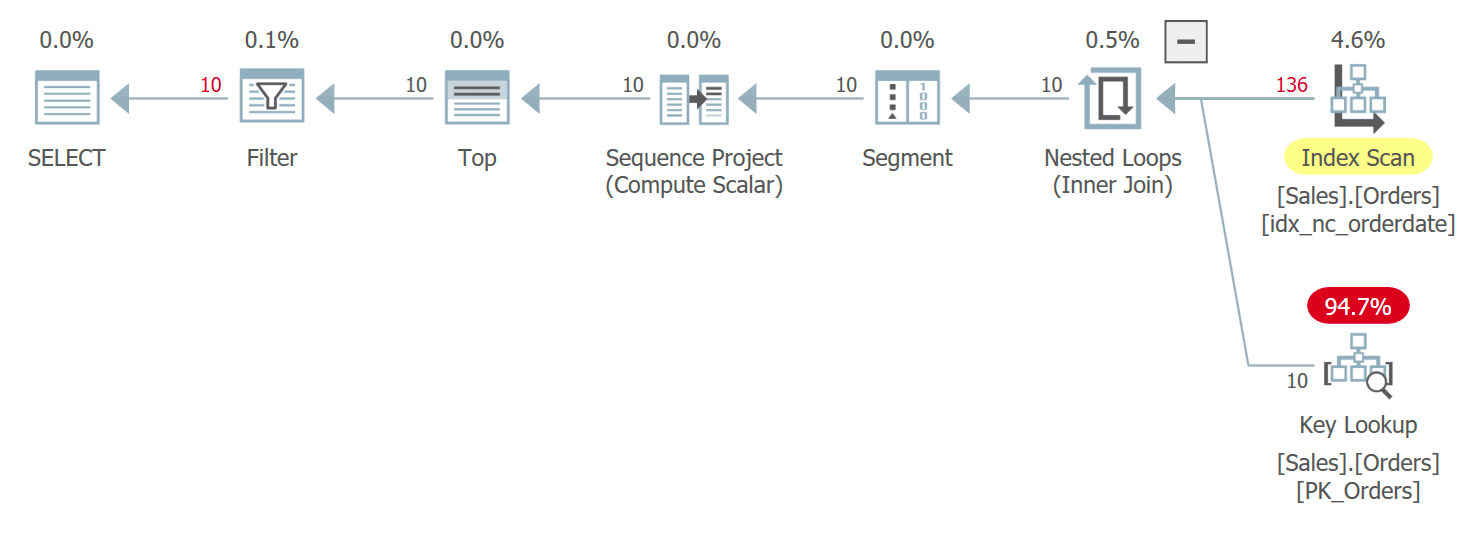
Figure 3: Plan for query 3
You have very similar conditions here to the ones I described earlier for Query 1 with its plan that was shown earlier in Figure 1. Between rows with ties in the orderdate values, this plan accesses a row with a higher orderid value before one with a lower orderid value. This query generates the following output:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 *** 11068 2019-05-04 62
Next, run the query again (call it Query 4), requesting the first page, only this time force the use of the clustered index PK_Orders:
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders WITH (INDEX(PK_Orders))
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10;
The plan for this query is shown in Figure 4.

Figure 4: Plan for query 4
This time you have very similar conditions to the ones I described earlier for Query 2 with its plan that was shown earlier in Figure 2. Between rows with ties in the orderdate values, this plan accesses a row with a lower orderid value before one with a higher orderid value. This query generates the following output:
orderid orderdate custid ----------- ---------- ----------- 11074 2019-05-06 73 11075 2019-05-06 68 11076 2019-05-06 9 11077 2019-05-06 65 11070 2019-05-05 44 11071 2019-05-05 46 11072 2019-05-05 20 11073 2019-05-05 58 11067 2019-05-04 17 *** 11068 2019-05-04 62
Observe that the two executions produced different results even though nothing changed in the underlying data.
Again, the best practice here is simple—use deterministic order by adding a tiebreaker, like so:
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n
FROM Sales.Orders
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10;
This query generates the following output:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 11068 2019-05-04 62
The returned set is guaranteed to be repeatable irrespective of the plan shape.
It’s probably worthwhile mentioning that since this query doesn’t have a presentation order by clause in the outer query, there’s no guaranteed presentation order here. If you need such a guarantee, you do have to add a presentation order by clause, like so:
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n
FROM Sales.Orders
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10
ORDER BY n;
Nondeterministic functions
A nondeterministic function is a function that given the same inputs, can return different results in different executions of the function. Classic examples are SYSDATETIME, NEWID, and RAND (when invoked without an input seed). The behavior of nondeterministic functions in T-SQL can be surprising to some, and could result in bugs and pitfalls in some cases.
Many people assume that when you invoke a nondeterministic function as part of a query, the function gets evaluated separately per row. In practice, most nondeterministic functions get evaluated once per reference in the query. Consider the following query as an example:
SELECT orderid, SYSDATETIME() AS dt, RAND() AS rnd
FROM Sales.Orders;
Since there’s only one reference to each of the nondeterministic functions SYSDATETIME and RAND in the query, each of these functions is evaluated only once, and its result is repeated across all result rows. I got the following output when running this query:
orderid dt rnd ----------- --------------------------- ---------------------- 11008 2019-02-04 17:03:07.9229177 0.962042872007464 11019 2019-02-04 17:03:07.9229177 0.962042872007464 11039 2019-02-04 17:03:07.9229177 0.962042872007464 11040 2019-02-04 17:03:07.9229177 0.962042872007464 11045 2019-02-04 17:03:07.9229177 0.962042872007464 11051 2019-02-04 17:03:07.9229177 0.962042872007464 11054 2019-02-04 17:03:07.9229177 0.962042872007464 11058 2019-02-04 17:03:07.9229177 0.962042872007464 11059 2019-02-04 17:03:07.9229177 0.962042872007464 11061 2019-02-04 17:03:07.9229177 0.962042872007464 ...
As an example where not understanding this behavior can result in a bug, suppose that you need to write a query that returns three random orders from the Sales.Orders table. A common initial attempt is to use a TOP query with ordering based on the RAND function, thinking that the function would get evaluated separately per row, like so:
SELECT TOP (3) orderid
FROM Sales.Orders
ORDER BY RAND();
In practice, the function gets evaluated only once for the entire query; therefore, all rows get the same result, and ordering is completely unaffected. In fact, if you check the plan for this query, you will see no Sort operator. When I ran this query multiple times, I kept getting the same result:
orderid ----------- 11008 11019 11039
The query is actually equivalent to one without an ORDER BY clause, where presentation ordering is not guaranteed. So technically the ordering is nondeterministic, and theoretically different executions could result in different order, and hence in a different selection of top 3 rows. However, the likelihood for this is low, and you cannot think of this solution as producing three random rows in each execution.
An exception to the rule that a nondeterministic function is invoked once per reference in the query is the NEWID function, which returns a globally unique identifier (GUID). When used in a query, this function is invoked separately per row. The following query demonstrates this:
SELECT orderid, NEWID() AS mynewid
FROM Sales.Orders;
This query generated the following output:
orderid mynewid ----------- ------------------------------------ 11008 D6417542-C78A-4A2D-9517-7BB0FCF3B932 11019 E2E46BF1-4FA6-4EF2-8328-18B86259AD5D 11039 2917D923-AC60-44F5-92D7-FF84E52250CC 11040 B6287B49-DAE7-4C6C-98A8-7DB8A879581C 11045 2E14D8F7-21E5-4039-BF7E-0A27D1A0E186 11051 FA0B7B3E-BA41-4D80-8581-782EB88836C0 11054 1E6146BB-FEE7-4FF4-A4A2-3243AA2CBF78 11058 49302EA9-0243-4502-B9D2-46D751E6EFA9 11059 F5BB7CB2-3B17-4D01-ABD2-04F3C5115FCF 11061 09E406CA-0251-423B-8DF5-564E1257F93E ...
The value of NEWID itself is quite random. If you apply the CHECKSUM function on top of it, you get an integer result with an even better random distribution. So one way to get three random orders is to use a TOP query with ordering based on CHECKSUM(NEWID()), like so:
SELECT TOP (3) orderid
FROM Sales.Orders
ORDER BY CHECKSUM(NEWID());
Run this query repeatedly and notice that you get a different set of three random orders each time. I got the following output in one execution:
orderid ----------- 11031 10330 10962
And the following output in another execution:
orderid ----------- 10308 10885 10444
Other than NEWID, what if you do need to use a nondeterministic function like SYSDATETIME in a query, and you do need it to be evaluated separately per row? One way to achieve this is to use a user defined function (UDF) that invokes the nondeterministic function, like so:
CREATE OR ALTER FUNCTION dbo.MySysDateTime() RETURNS DATETIME2
AS
BEGIN
RETURN SYSDATETIME();
END;
GO
You then invoke the UDF in the query like so (call it Query 5):
SELECT orderid, dbo.MySysDateTime() AS mydt
FROM Sales.Orders;
The UDF does get executed per row this time. You do need to be aware, though, that there’s a pretty sharp performance penalty associated with the per row execution of the UDF. Furthermore, invoking a scalar T-SQL UDF is a parallelism inhibitor.
The plan for this query is shown in Figure 5.
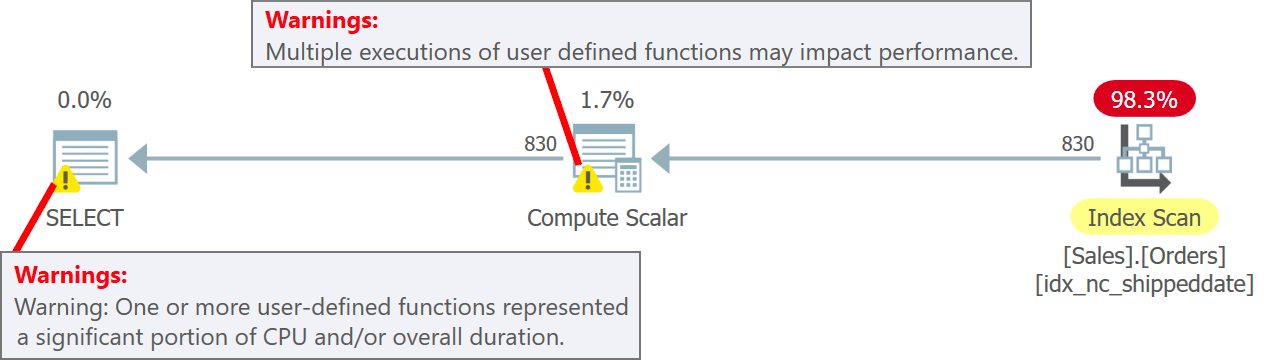
Figure 5: Plan for query 5
Notice in the plan that indeed the UDF gets invoked per source row in the Compute Scalar operator. Also notice that SentryOne Plan Explorer does warn you about the potential performance penalty associated with the use of the UDF both in the Compute Scalar operator and in the plan’s root node.
I got the following output from the execution of this query:
orderid mydt ----------- --------------------------- 11008 2019-02-04 17:07:03.7221339 11019 2019-02-04 17:07:03.7221339 11039 2019-02-04 17:07:03.7221339 ... 10251 2019-02-04 17:07:03.7231315 10255 2019-02-04 17:07:03.7231315 10248 2019-02-04 17:07:03.7231315 ... 10416 2019-02-04 17:07:03.7241304 10420 2019-02-04 17:07:03.7241304 10421 2019-02-04 17:07:03.7241304 ...
Observe that the output rows have multiple different date and time values in the mydt column.
You may have heard that SQL Server 2019 addresses the common performance problem caused by scalar T-SQL UDFs by inlining such functions. However, the UDF has to meet a list of requirements in order to be inlineable. One of the requirements is that the UDF does not invoke any nondeterministic intrinsic function such as SYSDATETIME. The reasoning for this requirement is that perhaps you created the UDF exactly to get a per row execution. If the UDF got inlined, the underlying nondeterministic function would get executed only once for the entire query. In fact, the plan in Figure 5 was generated in SQL Server 2019, and you can clearly see that the UDF didn’t get inlined. That’s due to the use of the nondeterministic function SYSDATETIME. You can check if a UDF is inlineable in SQL Server 2019 by querying the is_inlineable attribute in the sys.sql_modules view, like so:
SELECT is_inlineable
FROM sys.sql_modules
WHERE object_id = OBJECT_ID(N'dbo.MySysDateTime');
This code generates the following output telling you that the UDF MySysDateTime isn’t inlineable:
is_inlineable ------------- 0
To demonstrate a UDF that is inlineable, here’s the definition of a UDF called EndOfyear that accepts an input date and returns the respective end-of-year date:
CREATE OR ALTER FUNCTION dbo.EndOfYear(@dt AS DATE) RETURNS DATE
AS
BEGIN
RETURN DATEADD(year, DATEDIFF(year, '18991231', @dt), '18991231');
END;
GO
There’s no use of nondeterministic functions here, and the code also meets the other requirements for inlining. You can verify that the UDF is inlineable by using the following code:
SELECT is_inlineable
FROM sys.sql_modules
WHERE object_id = OBJECT_ID(N'dbo.EndOfYear');
This code generates the following output:
is_inlineable ------------- 1
The following query (call it Query 6) uses the UDF EndOfYear to filter orders that were placed on an end-of-year date:
SELECT orderid
FROM Sales.Orders
WHERE orderdate = dbo.EndOfYear(orderdate);
The plan for this query is shown in Figure 6.
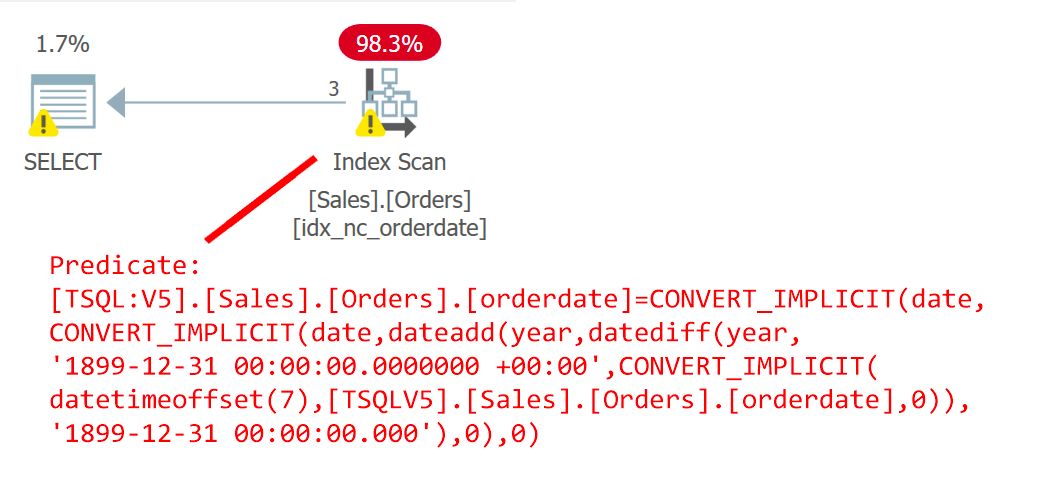
Figure 6: Plan for query 6
The plan clearly shows that the UDF got inlined.
Table expressions, nondeterminism and multiple references
As mentioned, nondeterministic functions like SYSDATETIME are invoked once per reference in a query. But what if you reference such a function once in a query in a table expression like a CTE, and then have an outer query with multiple references to the CTE? Many people don’t realize that each reference to the table expression gets expanded separately, and the inlined code results in multiple references to the underlying nondeterministic function. With a function like SYSDATETIME, depending on the exact timing of each of the executions, you could end up getting a different result for each. Some people find this behavior surprising.
This can be illustrated with the following code:
DECLARE @i AS INT = 1, @rc AS INT = NULL;
WHILE 1 = 1
BEGIN;
WITH C1 AS
(
SELECT SYSDATETIME() AS dt
),
C2 AS
(
SELECT dt FROM C1
UNION
SELECT dt FROM C1
)
SELECT @rc = COUNT(*) FROM C2;
IF @rc > 1 BREAK;
SET @i += 1;
END;
SELECT @rc AS distinctvalues, @i AS iterations;
If both references to C1 in the query in C2 represented the same thing, this code would have resulted in an infinite loop. However, since the two references get expanded separately, when the timing is such that each invocation takes place in a different 100-nanosecond interval (the precision of the result value), the union results in two rows, and the code should break from the loop. Run this code and see for yourself. Indeed, after some iterations it breaks. I got the following result in one of the executions:
distinctvalues iterations -------------- ----------- 2 448
The best practice is to avoid using table expressions like CTEs and views, when the inner query uses nondeterministic calculations and the outer query refers to the table expression multiple times. That’s of course unless you understand the implications and you’re OK with them. Alternative options could be to persist the inner query result, say in a temporary table, and then to query the temporary table any number of times that you need.
To demonstrate examples where not following the best practice can get you into trouble, suppose that you need to write a query that pairs employees from the HR.Employees table randomly. You come up with the following query (call it query 7) to handle the task:
WITH C AS
(
SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n
FROM HR.Employees
)
SELECT
C1.empid AS empid1, C1.firstname AS firstname1, C1.lastname AS lastname1,
C2.empid AS empid2, C2.firstname AS firstname2, C2.lastname AS lastname2
FROM C AS C1
INNER JOIN C AS C2
ON C1.n = C2.n + 1;
The plan for this query is shown in Figure 7.
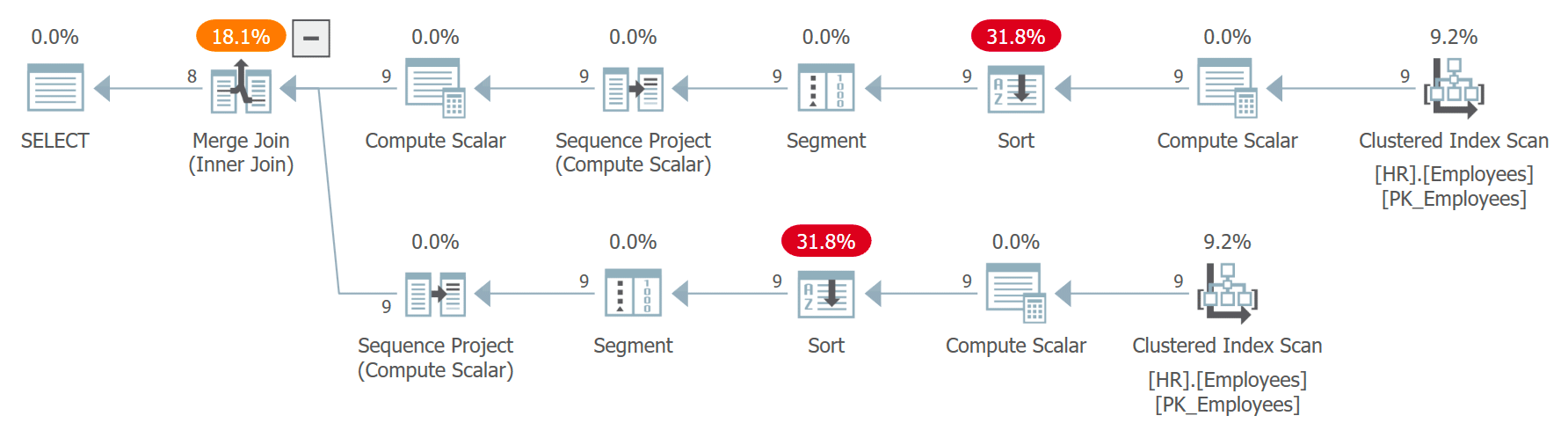
Figure 7: Plan for Query 7
Observe that the two references to C are expanded separately, and the row numbers are computed independently for each reference ordered by independent invocations of the CHECKSUM(NEWID()) expression. This means that the same employee is not guaranteed to get the same row number in the two expanded references. If an employee gets row number x in C1 and row number x – 1 in C2, the query will pair the employee with him or herself. For example, I got the following result in one of the executions:
empid1 firstname1 lastname1 empid2 firstname2 lastname2 ----------- ---------- -------------------- ----------- ---------- -------------------- 3 Judy Lew 6 Paul Suurs 9 Patricia Doyle *** 9 Patricia Doyle *** 5 Sven Mortensen 4 Yael Peled 6 Paul Suurs 8 Maria Cameron 8 Maria Cameron 5 Sven Mortensen 2 Don Funk *** 2 Don Funk *** 4 Yael Peled 3 Judy Lew 7 Russell King *** 7 Russell King ***
Observe that there are three cases here of self-pairs. This is easier to see by adding a filter to the outer query that specifically looks for self-pairs, like so:
WITH C AS
(
SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n
FROM HR.Employees
)
SELECT
C1.empid AS empid1, C1.firstname AS firstname1, C1.lastname AS lastname1,
C2.empid AS empid2, C2.firstname AS firstname2, C2.lastname AS lastname2
FROM C AS C1
INNER JOIN C AS C2
ON C1.n = C2.n + 1
WHERE C1.empid = C2.empid;
You might need to run this query a number of times to see the problem. Here’s an example for the result that I got in one of the executions:
empid1 firstname1 lastname1 empid2 firstname2 lastname2 ----------- ---------- -------------------- ----------- ---------- -------------------- 5 Sven Mortensen 5 Sven Mortensen 2 Don Funk 2 Don Funk
Following the best practice, one way to solve this problem is to persist the inner query result in a temporary table and then query multiple instances of the temporary table as needed.
Another example illustrates bugs that can result from the use of nondeterministic order and multiple references to a table expression. Suppose that you need to query the Sales.Orders table and in order to do trend analysis, you want to pair each order with the next based on orderdate ordering. Your solution has to be compatible with pre-SQL Server 2012 systems meaning that you cannot use the obvious LAG/LEAD functions. You decide to use a CTE that computes row numbers to position rows based on orderdate ordering, and then join two instances of the CTE, pairing orders based on an offset of 1 between the row numbers, like so (call this Query 8):
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders
)
SELECT
C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1,
C2.orderid AS orderid2, C2.orderdate AS orderdate2
FROM C AS C1
LEFT OUTER JOIN C AS C2
ON C1.n = C2.n + 1;
The plan for this query is shown in Figure 8.
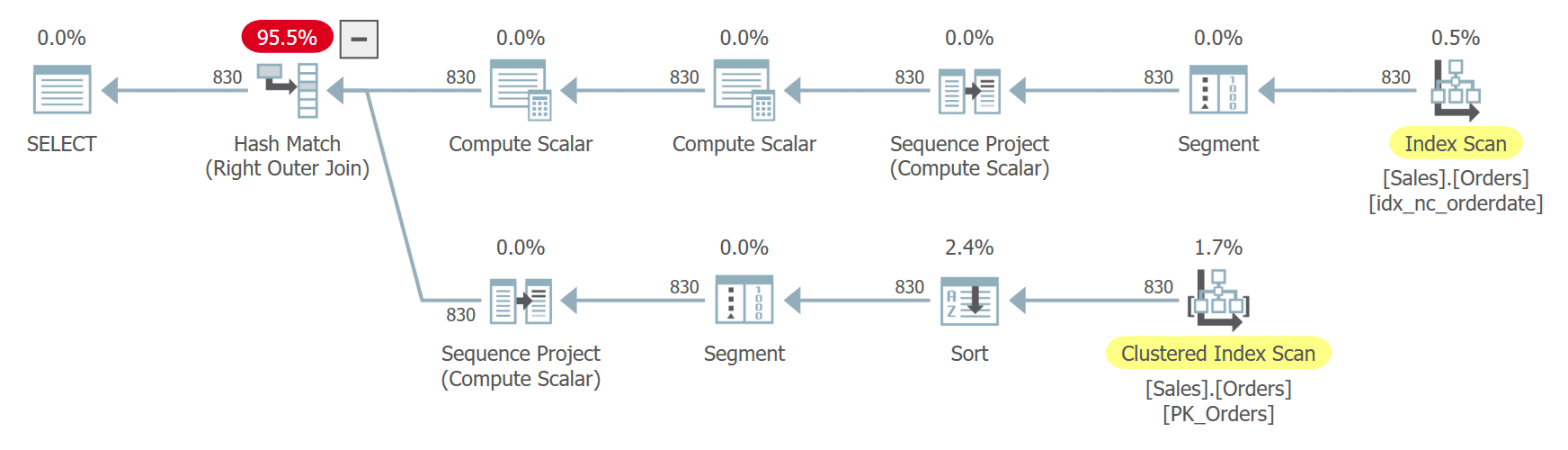 Figure 8: Plan for Query 8
Figure 8: Plan for Query 8
The row number ordering isn’t deterministic since orderdate isn’t unique. Observe that the two references to the CTE get expanded separately. Curiously, since the query is looking for a different subset of columns from each of the instances, the optimizer decides to use a different index in each case. In one case it uses an ordered backward scan of the index on orderdate, effectively scanning rows with the same date based on orderid descending ordering. In the other case it scans the clustered index, ordered false and then sorts, but effectively among rows with the same date, it accesses the rows in orderid ascending order. That’s due to similar reasoning that I provided in the section about nondeterministic order earlier. This can result in the same row getting row number x in one instance and row number x – 1 in the other instance. In such a case, the join will end up matching an order with itself instead of with the next one like it should.
I got the following result when executing this query:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ----------- ---------- 11074 2019-05-06 73 NULL NULL 11075 2019-05-06 68 11077 2019-05-06 11076 2019-05-06 9 11076 2019-05-06 *** 11077 2019-05-06 65 11075 2019-05-06 11070 2019-05-05 44 11074 2019-05-06 11071 2019-05-05 46 11073 2019-05-05 11072 2019-05-05 20 11072 2019-05-05 *** ...
Observe the self-matches in the result. Again, the problem can be more easily identified by adding a filter looking for self-matches, like so:
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders
)
SELECT
C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1,
C2.orderid AS orderid2, C2.orderdate AS orderdate2
FROM C AS C1
LEFT OUTER JOIN C AS C2
ON C1.n = C2.n + 1
WHERE C1.orderid = C2.orderid;
I got the following output from this query:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ----------- ---------- 11076 2019-05-06 9 11076 2019-05-06 11072 2019-05-05 20 11072 2019-05-05 11062 2019-04-30 66 11062 2019-04-30 11052 2019-04-27 34 11052 2019-04-27 11042 2019-04-22 15 11042 2019-04-22 ...
The best practice here is to make sure that you use unique order to guarantee determinism by adding a tiebreaker like orderid to the window order clause. So even though you have multiple references to the same CTE, the row numbers are going to be the same in both. If you do wish to avoid the repetition of the calculations, you could also consider persisting the inner query result, but then you do need to consider the added cost of such work.
CASE/NULLIF and nondeterministic functions
When you have multiple references to a nondeterministic function in a query, each reference gets evaluated separately. What could be surprising and even result in bugs is that sometimes you write one reference, but implicitly it gets converted into multiple references. Such is the situation with some uses of the CASE expression and IIF function.
Consider the following example:
SELECT CASE ABS(CHECKSUM(NEWID())) % 2 WHEN 0 THEN 'Even' WHEN 1 THEN 'Odd' END;
Here the outcome of the tested expression is a nonnegative integer value, so clearly it has to be either even or odd. It cannot be neither even nor odd. However, if you run this code enough times, you will sometimes get a NULL indicating that the implied ELSE NULL clause of the CASE expression was activated. The reason for this is that the above expression translates to the following:
SELECT
CASE
WHEN ABS(CHECKSUM(NEWID())) % 2 = 0 THEN 'Even'
WHEN ABS(CHECKSUM(NEWID())) % 2 = 1 THEN 'Odd'
ELSE NULL
END;
In the converted expression there are two separate references to the tested expression that generates a random nonnegative value, and each gets evaluated separately. One possible path is that the first evaluation produces an odd number, the second produces an even number, and then the ELSE NULL clause is activated.
Here’s a very similar situation with the NULLIF function:
SELECT NULLIF(ABS(CHECKSUM(NEWID())) % 2, 0);
This expression generates a random nonnegative value, and is supposed to return 1 when it’s odd, and NULL otherwise. It’s never supposed to return 0 since in such a case the 0 is supposed to be replaced with a NULL. Run it a few times and you will see that in some cases you get a 0. The reason for this is that the above expression internally translates to the following one:
SELECT
CASE
WHEN ABS(CHECKSUM(NEWID())) % 2 = 0 THEN NULL
ELSE ABS(CHECKSUM(NEWID())) % 2
END;
A possible path is that the first WHEN clause generates a random odd value, so the ELSE clause is activated, and the ELSE clause generates a random even value so the % 2 calculation results in a 0.
In both cases this behavior is standard, so the bug is more in the eyes of the beholder based on your expectations and your choice of how to write the code. The best practice in both cases is to persist the result of the original calculation and then interact with the persisted result. If it’s a single value, store the result in a variable first. If you’re querying tables, first persist the result of the nondeterministic calculation in a column in a temporary table, and then apply the CASE/IIF logic in the query against the temporary table.
Conclusion
This article is the first in a series about T-SQL bugs, pitfalls and best practices, and is the result of discussions with fellow Microsoft Data Platform MVPs who shared their experiences. This time I focused on bugs and pitfalls that resulted from using nondeterministic order and nondeterministic calculations. In future articles I’ll continue with other themes. If you have bugs and pitfalls that you often stumble into, or that you find as particularly interesting, please do share!



Hi Itzik,
Great idea and article. I once fallen victim to a bad date ordering when casting to binary, like we sometimes do when – for instance – we don't have a suitable index.. I did something like cast(mydate as varbinary(9)) + cast(myid as varbinary(8)) and then tried to order by the joint binary value.
While it worked with datetime it created incorrect result with datetime2 due to a different "design" of that data type. I will never forget that one :-)
Hi Kamil,
That's indeed a common pitfall when relying on the physical representation of the data.
In such a case it would have probably been safer to convert to a character string with a YYYYMMDD format (style 112) and a fixed size string for the inter ID with leading zeroes.