



Back in March, I started a series on pervasive performance myths in SQL Server. One belief I encounter from time to time is that you can oversize varchar or nvarchar columns without any penalty.
Let's assume you are storing e-mail addresses. In a previous life, I dealt with this quite a bit – at the time, RFC 3696 stated that an e-mail address could be 320 characters (64chars@255chars). A newer RFC, #5321, now acknowledges that 254 characters is the longest an e-mail address could be. And if any of you have an address that long, well, maybe we should chat. :-)
Now, whether you go by the old standard or the new one, you do have to support the possibility that someone will use all the characters allowed. Which means you have to use 254 or 320 characters. But what I've seen people do is not bother researching the standard at all, and just assume that they need to support 1,000 characters, 4,000 characters, or even beyond.
So let's take a look at what happens when we have tables with an e-mail address column of varying size, but storing the exact same data:
CREATE TABLE dbo.Email_V320
(
id int IDENTITY PRIMARY KEY, email varchar(320)
);
CREATE TABLE dbo.Email_V1000
(
id int IDENTITY PRIMARY KEY, email varchar(1000)
);
CREATE TABLE dbo.Email_V4000
(
id int IDENTITY PRIMARY KEY, email varchar(4000)
);
CREATE TABLE dbo.Email_Vmax
(
id int IDENTITY PRIMARY KEY, email varchar(max)
);
Now, let's generate 10,000 fictitious e-mail address from system metadata, and populate all four tables with the same data:
INSERT dbo.Email_V320(email) SELECT TOP (10000)
REPLACE(LEFT(LEFT(c.name, 64) + '@' + LEFT(o.name, 128) + '.com', 254), ' ', '')
FROM sys.all_columns AS c
INNER JOIN sys.all_objects AS o
ON c.[object_id] = o.[object_id]
INNER JOIN sys.all_columns AS c2
ON c.[object_id] = c2.[object_id]
ORDER BY NEWID();
INSERT dbo.Email_V1000(email) SELECT email FROM dbo.Email_V320;
INSERT dbo.Email_V4000(email) SELECT email FROM dbo.Email_V320;
INSERT dbo.Email_Vmax (email) SELECT email FROM dbo.Email_V320;
-- let's rebuild
ALTER INDEX ALL ON dbo.Email_V320 REBUILD;
ALTER INDEX ALL ON dbo.Email_V1000 REBUILD;
ALTER INDEX ALL ON dbo.Email_V4000 REBUILD;
ALTER INDEX ALL ON dbo.Email_Vmax REBUILD;
To validate that each table contains exactly the same data:
SELECT AVG(LEN(email)), MAX(LEN(email)) FROM dbo.Email_;
All four of those yield 35 and 77 for me; your mileage may vary. Let's also make sure that all four tables occupy the same number of pages on disk:
SELECT o.name, COUNT(p.[object_id])
FROM sys.objects AS o
CROSS APPLY sys.dm_db_database_page_allocations
(DB_ID(), o.object_id, 1, NULL, 'LIMITED') AS p
WHERE o.name LIKE N'Email[_]V[^2]%'
GROUP BY o.name;
All four of those queries yield 89 pages (again, your mileage may vary).
Now, let's take a typical query that results in a clustered index scan:
SELECT id, email FROM dbo.Email_;
If we look at things like duration, reads, and estimated costs, they all seem the same:
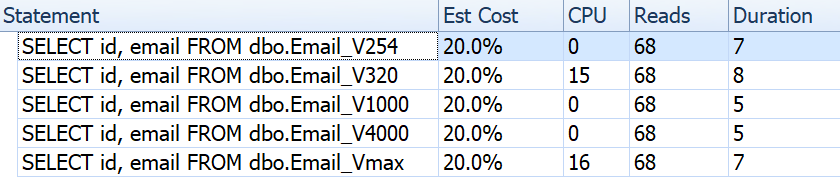
This may lull people into a false assumption that there is no performance impact at all. But if we look just a little bit closer, on the tooltip for the clustered index scan in each plan, we see a difference that may come into play in other, more elaborate queries:

From here we see that, the bigger the column definition, the higher the estimated row and data size. In this simple query, the I/O cost (0.0512731) is the same across all of the queries, regardless of definition, because the clustered index scan has to read all of the data anyway.
But there are other scenarios where this estimated row and total data size will have an impact: operations that require additional resources, such as sorts. Let's take this ridiculous query that doesn't serve any real purpose, other than to require multiple sort operations:
SELECT /* V */ ROW_NUMBER() OVER (PARTITION BY email ORDER BY email DESC),
email, REVERSE(email), SUBSTRING(email, 1, CHARINDEX('@', email))
FROM dbo.Email_V
GROUP BY REVERSE(email), email, SUBSTRING(email, 1, CHARINDEX('@', email))
ORDER BY REVERSE(email), email;
We run these four queries and we see the plans all look like this:

However that warning icon on the SELECT operator only appears on the 4000/max tables. What is the warning? It's an excessive memory grant warning, introduced in SQL Server 2016. Here is the warning for varchar(4000):

And for varchar(max):

Let's look a little closer and see what is going on, at least according to sys.dm_exec_query_stats:
SELECT
[table] = SUBSTRING(t.[text], 1, CHARINDEX(N'*/', t.[text])),
s.last_elapsed_time,
s.last_grant_kb,
s.max_ideal_grant_kb
FROM sys.dm_exec_query_stats AS s
CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t
WHERE t.[text] LIKE N'%/*%dbo.'+N'Email_V%'
ORDER BY s.last_grant_kb;
Results:

In my scenario, the duration was not impacted by the memory grant differences (except for the max case), but you can clearly see the linear progression that coincides with the declared size of the column. Which you can use to extrapolate what would happen on a system with insufficient memory. Or a more elaborate query against a much larger data set. Or significant concurrency. Any of those scenarios could require spills in order to process the sort operations, and duration would almost certainly be affected as a result.
But where do these larger memory grants come from? Remember, it's the same query, against the exact same data. The problem is that, for certain operations, SQL Server has to take into account how much data *might* be in a column. It doesn't do this based on actually profiling the data, and it can't make any assumptions based on the <= 201 histogram step values. Instead, it has to estimate that every row holds a value half of the declared column size. So for a varchar(4000), it assumes every e-mail address is 2,000 characters long.
When it's not possible to have an e-mail address longer than 254 or 320 characters, there is nothing to gain by over-sizing, and there is plenty to potentially lose. Increasing the size of a variable-width column later is much easier than dealing with all the downside now.
Of course, oversizing char or nchar columns can have much more obvious penalties.



speaking of excessive memory grant warning: http://codingsight.com/sql-server-dark-side-nvarchar/
Thank you for this nice and clear sum-up. It's one of the things I see quite a few times in Systems with performance problems.
Thanks for the article. I'm currently working on a system that has a lot of greatly oversized columns, which I know are impacting performance. Now I have a better idea of how to measure the impact. Thanks!
Not directly visible in the database engine, but oversized columns have a serious performance impact in SSIS.
Very interesting! Could you elaborate?
SSIS uses the maximum column size to calculate row length and buffer size. If the buffer is too big, not much data can be transferred at a time.
Thanks!
It's not the insert that takes a while, its the update. Run a similar test with updates and you'll see what I mean.
Just a comment. Not here to ruin anyone's day…
Not sure what you mean Jayson, I measured the duration and memory usage of select queries, not inserts or updates.
Great post Aaron. I see this all the time when folks don't know their data or understand the potential impact of their design on database (and server!) performance.
It seems that email, phone, address are easy to talk about and have guidance on because they have somewhat standard maximum lengths.
What would be the guidance for fields like a comment?
Say you defined it as VARCHAR(50), put it in stored procedures/EF/SSIS and other tooling, the problem is each one of those places needs to be touched/tested to increase it to VARCHAR(200), then later VARCHAR(500), ad nauseam (plus the ALTER TABLE for large tables may be scary)
Seems like as always "it depends" and just to know higher a maximum VAR* type length does affect performance and not for free.
Thanks for this clear presentation.
I've witnessed this type of performance degradation in systems where everything is varchar(1000), even gender, but it wasn't clear how the degradation is "implemented".
Your lucid explanation should help in dissuading others from this habit.
Indeed, wasn't meaning to suggest you can always avoid oversizing. Sometimes it just depends on the business need. My point was simply that if the business need is something like e-mail address, adhering to standards can often be better for the business than guessing.
Isn't there a slight downside to this, when it underestimates the memory required and the memory grant is filled, the query will spill to tempdb causing worse performance.
Of course, there's no perfect solution. Again, I am talking about the cases where you know e-mail addresses, for example, can't be > 320 characters by definition. So making them nvarchar(4000) and requiring memory grants of 4K per row is very wasteful. If you make it 320 characters you may still have the chance that your average e-mail address is > 160 characters, but that is unlikely. Different data may have very different patterns, but if the average length is much higher than half the defined size, you'll have to decide if (a) you make the defined size larger (and add a check constraint perhaps), and always have slightly larger memory grants, or (b) you keep it the way it is and add memory and/or better optimize tempdb so that spills are not an issue (or at least less of an issue).
Very nice explanation and useful in the context of column data similar to email address example here. Thank you.
Hi Aron,
Does this hold true for all versions of SQL server ? Thank you again for the informative article.
"Instead, it has to estimate that every row holds a value half of the declared column size."
So what estimate does it use for columns declared with a MAX length?
Half a page (4K).
Is performance affected if the "oversized" column is not part of the SELECT ? I guess not, but I wanna be sure since I have a table with many columns, some of which are VARCHAR(MAX) but are rarely queried. If it hurts performance I might move them to an other table.
It can affect performance in some cases, sure. The size of every column still has to be considered as part of the read if you do a key lookup, for example.