


In my last post, I showed some efficient approaches to grouped concatenation. This time around, I wanted to talk about a couple of additional facets of this problem that we can accomplish easily with the FOR XML PATH approach: ordering the list, and removing duplicates.
There are a few ways that I have seen people want the comma-separated list to be ordered. Sometimes they want the item in the list to be ordered alphabetically; I showed that already in my previous post. But sometimes they want it sorted by some other attribute that's actually not being introduced in the output; for example, maybe I want to order the list by most recent item first. Let's take a simple example, where we have an Employees table and a CoffeeOrders table. Let's just populate one person's orders for a few days:
CREATE TABLE dbo.Employees
(
EmployeeID INT PRIMARY KEY,
Name NVARCHAR(128)
);
INSERT dbo.Employees(EmployeeID, Name) VALUES(1, N'Jack');
CREATE TABLE dbo.CoffeeOrders
(
EmployeeID INT NOT NULL REFERENCES dbo.Employees(EmployeeID),
OrderDate DATE NOT NULL,
OrderDetails NVARCHAR(64)
);
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
VALUES(1,'20140801',N'Large double double'),
(1,'20140802',N'Medium double double'),
(1,'20140803',N'Large Vanilla Latte'),
(1,'20140804',N'Medium double double');
If we use the existing approach without specifying an ORDER BY, we get an arbitrary ordering (in this case, it is most likely the case that you will see the rows in the order they were inserted, but don't depend on that with larger data sets, more indexes, etc.):
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails
FROM dbo.CoffeeOrders AS c
WHERE c.EmployeeID = e.EmployeeID
FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'')
FROM dbo.Employees AS e
GROUP BY e.EmployeeID, e.Name;
Results (remember, you may get *different* results unless you specify an ORDER BY):
Jack | Large double double, Medium double double, Large Vanilla Latte, Medium double double
If we want to order the list alphabetically, it's simple; we just add ORDER BY c.OrderDetails:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails
FROM dbo.CoffeeOrders AS c
WHERE c.EmployeeID = e.EmployeeID
ORDER BY c.OrderDetails -- only change
FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'')
FROM dbo.Employees AS e
GROUP BY e.EmployeeID, e.Name;
Results:
Jack | Large double double, Large Vanilla Latte, Medium double double, Medium double double
We can also order by a column that does not appear in the result set; for example, we can order by most recent coffee order first:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails
FROM dbo.CoffeeOrders AS c
WHERE c.EmployeeID = e.EmployeeID
ORDER BY c.OrderDate DESC -- only change
FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'')
FROM dbo.Employees AS e
GROUP BY e.EmployeeID, e.Name;
Results:
Jack | Medium double double, Large Vanilla Latte, Medium double double, Large double double
Another thing we often want to do is remove duplicates; after all, there is little reason to see "Medium double double" twice. We can eliminate that by using GROUP BY:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails
FROM dbo.CoffeeOrders AS c
WHERE c.EmployeeID = e.EmployeeID
GROUP BY c.OrderDetails -- removed ORDER BY and added GROUP BY here
FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'')
FROM dbo.Employees AS e
GROUP BY e.EmployeeID, e.Name;
Now, this *happens* to order the output alphabetically, but again you can't rely on this:
Jack | Large double double, Large Vanilla Latte, Medium double double
If you want to guarantee that ordering this way, you can simply add an ORDER BY again:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails
FROM dbo.CoffeeOrders AS c
WHERE c.EmployeeID = e.EmployeeID
GROUP BY c.OrderDetails
ORDER BY c.OrderDetails -- added ORDER BY
FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'')
FROM dbo.Employees AS e
GROUP BY e.EmployeeID, e.Name;
Results are the same (but I'll repeat, this is just a coincidence in this case; if you want this order, always say so):
Jack | Large double double, Large Vanilla Latte, Medium double double
But what if we want to eliminate duplicates *and* sort the list by most recent coffee order first? Your first inclination might be to keep the GROUP BY and just change the ORDER BY, like this:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails
FROM dbo.CoffeeOrders AS c
WHERE c.EmployeeID = e.EmployeeID
GROUP BY c.OrderDetails
ORDER BY c.OrderDate DESC -- changed ORDER BY
FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'')
FROM dbo.Employees AS e
GROUP BY e.EmployeeID, e.Name;
That won't work, since the OrderDate is not grouped or aggregated as part of the query:
Column "dbo.CoffeeOrders.OrderDate" is invalid in the ORDER BY clause because it is not contained in either an aggregate function or the GROUP BY clause.
A workaround, which admittedly makes the query a little uglier, is to group the orders separately first, and then only take the rows with the max date for that coffee order per employee:
;WITH grouped AS
(
SELECT EmployeeID, OrderDetails, OrderDate = MAX(OrderDate)
FROM dbo.CoffeeOrders
GROUP BY EmployeeID, OrderDetails
)
SELECT e.Name, Orders = STUFF((SELECT N', ' + g.OrderDetails
FROM grouped AS g
WHERE g.EmployeeID = e.EmployeeID
ORDER BY g.OrderDate DESC
FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'')
FROM dbo.Employees AS e
GROUP BY e.EmployeeID, e.Name;
Results:
Jack | Medium double double, Large Vanilla Latte, Large double double
This accomplishes both of our goals: we've eliminated duplicates, and we've ordered the list by something that's not actually in the list.
Performance
You might be wondering how badly these methods perform against a more robust data set. I'm going to populate our table with 100,000 rows, see how they do without any additional indexes, and then run the same queries again with a little bit of index tuning to support our queries. So first, getting 100,000 rows spread across 1,000 employees:
-- clear out our tiny sample data
DELETE dbo.CoffeeOrders;
DELETE dbo.Employees;
-- create 1000 fake employees
INSERT dbo.Employees(EmployeeID, Name)
SELECT TOP (1000)
EmployeeID = ROW_NUMBER() OVER (ORDER BY t.[object_id]),
Name = LEFT(t.name + c.name, 128)
FROM sys.all_objects AS t
INNER JOIN sys.all_columns AS c
ON t.[object_id] = c.[object_id];
-- create 100 fake coffee orders for each employee
-- we may get duplicates in here for name
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
SELECT e.EmployeeID,
OrderDate = DATEADD(DAY, ROW_NUMBER() OVER
(PARTITION BY e.EmployeeID ORDER BY c.[guid]), '20140630'),
LEFT(c.name, 64)
FROM dbo.Employees AS e
CROSS APPLY
(
SELECT TOP (100) name, [guid] = NEWID()
FROM sys.all_columns
WHERE [object_id] < e.EmployeeID
ORDER BY NEWID()
) AS c;
Now let's just run each of our queries twice, and see what the timing is like on the second try (we'll take a leap of faith here, and assume that - in an ideal world - we'll be working with a primed cache). I ran these in SQL Sentry Plan Explorer, since it's the easiest way I know of to time and compare a bunch of individual queries:
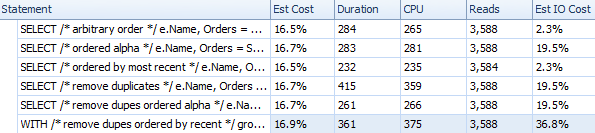 Duration and other runtime metrics for different FOR XML PATH approaches
Duration and other runtime metrics for different FOR XML PATH approaches
These timings (duration is in milliseconds) really aren't that bad at all IMHO, when you think about what's actually being done here. The most complicated plan, at least visually, seemed to be the one where we removed duplicates and sorted by most recent order:
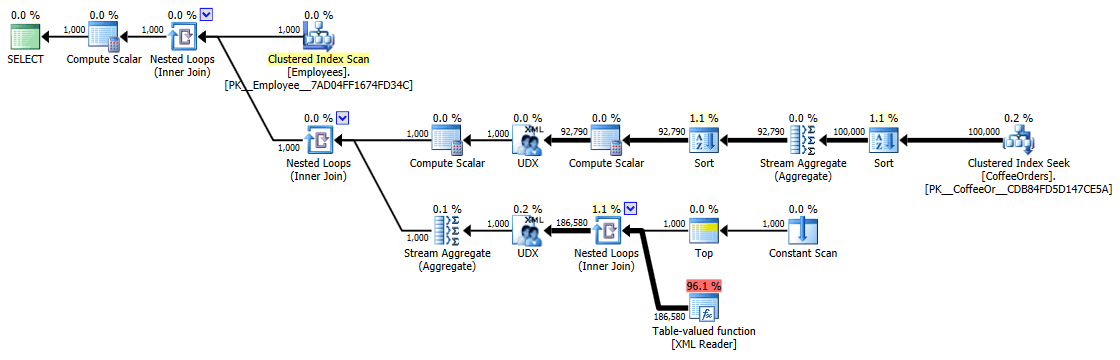 Execution plan for grouped and sorted query
Execution plan for grouped and sorted query
But even the most expensive operator here - the XML table-valued function - seems to be all CPU (even though I will freely admit that I'm not sure how much of the actual work is exposed in the query plan details):
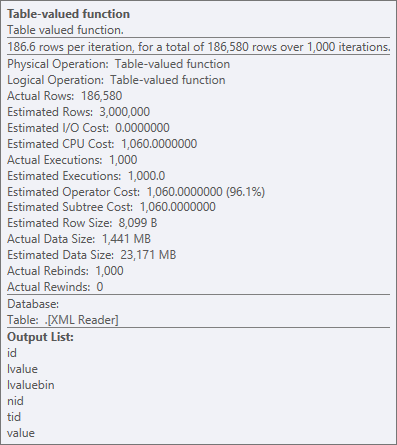 Operator properties for the XML table-valued function
Operator properties for the XML table-valued function
"All CPU" is typically okay, since most systems are I/O-bound and/or memory-bound, not CPU-bound. As I say quite often, in most systems I'll trade some of my CPU headroom for memory or disk any day of the week (one of the reasons I like OPTION (RECOMPILE) as a solution to pervasive parameter sniffing issues).
That said, I do strongly encourage you to test these approaches against similar results you can get from the GROUP_CONCAT CLR approach on CodePlex, as well as performing the aggregation and sorting at the presentation tier (particularly if you are keeping the normalized data in some sort of caching layer).



You could use aggregate in order by clause.
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails
FROM dbo.CoffeeOrders AS c
WHERE c.EmployeeID = e.EmployeeID
GROUP BY c.OrderDetails
ORDER BY Max(c.OrderDate) DESC — changed ORDER BY
FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N")
FROM dbo.Employees AS e
GROUP BY e.EmployeeID, e.Name
Hi Sviridov, thanks, that is an alternative too; while it gets the same results and generates the same plan, in my testing the duration and CPU were always a bit higher than the CTE variation I proposed. YMMV. :-)
I know I'm late to the party, but is there any significant performance increase using the GROUP BY function in the sub query over simply SELECT DISTINCT N', ' + c.OrderDetails ?
Please forgive any holes in my understanding here.
There can be, yes. Primarily because GROUP BY will work first, whereas DISTINCT applies afterward. So depending on the data you could be performing the grouped concatenation many more times, and then only weeding out duplicates after all that work is done. GROUP BY *should* weed the duplicates out first, but in the worst possible case, they'll be the same.
This approach works for Text or single digit number, but it does not work with double digit duplicate numbers. Can you please help?
Can you elaborate? Show some sample data and desired results?
All of the scenarios shown can be done using the GROUP_CONCAT SQLCLR objects on CodePlex *except* sorting by something other than the column being concatenated. However, that functionality is in development.
For output sorted by the grouped string you can use GROUP_CONCAT_S:
SELECT e.Name,
Orders = dbo.GROUP_CONCAT_S(c.OrderDetails, 1) — sorted list
FROM dbo.Employees AS e
JOIN dbo.CoffeeOrders AS c ON e.EmployeeID = c.EmployeeID
GROUP BY e.Name
ORDER BY e.Name;
For unique values you can declare DISTINCT on the column being passed into the Aggregate, like this:
SELECT e.Name,
Orders = dbo.GROUP_CONCAT_S(DISTINCT c.OrderDetails, 1) — DISTINCT, sorted list
FROM dbo.Employees AS e
JOIN dbo.CoffeeOrders AS c ON e.EmployeeID = c.EmployeeID
GROUP BY e.Name
ORDER BY e.Name;
Full disclosure, I developed the GROUP_CONCAT objects on CodePlex.
too good
Great article. Easy to follow and very thorough! Thanks this helped me out in my job today.