

When ESX 5 and Hyper-V in Windows Server 2012 released and changed the limitations that previously existed for VM sizes, I knew almost immediately that we'd see more large scale-up SQL Server workloads start to be virtualized. I've worked with a number of customers in the last year that were virtualizing 16-32 core SQL Servers with various reasons, from simplified Disaster Recovery strategies that matched the rest of the business, to consolidation and lower total cost of ownership on newer hardware platforms. One of the reasons for the scalability change with ESX 5+ was the introduction of virtual NUMA (vNUMA) for wide guests that exceeded the size of an individual hardware NUMA node. With vNUMA, the guest VM is optimized to match the hardware NUMA topology, allowing the guest operating system and any NUMA aware applications, like SQL Server, that are running on the VM to take advantage of the NUMA performance optimizations, just as if they were running on a physical server.
Within VMware, a vNUMA topology is available on hardware version 8 or higher, and gets configured by default if the number of vCPUs is greater than eight for the guest. It is also possible to manually configure the vNUMA topology for a VM using advanced configuration options, which can be useful for VMs that have more memory allocated to them than a physical NUMA node can provide, but still uses eight or fewer vCPUs. For the most part, the default configuration settings work for the majority of VMs that I've looked at over the last few years, but there are certain scenarios where the default vNUMA topology isn't ideal and manual configuration can provide some benefits. Recently I was working with a client with a number of 32 vCPU SQL Server VMs with 512GB RAM allocated doing some performance tuning where the vNUMA topology wasn't anything close to what was expected.
The VM host servers in this environment were four socket E5-4650 eight core processors and 1TB of RAM, each dedicated to a single SQL Server VM under typical operations, but with available capacity to sustain two VMs in a failure scenario. With this hardware layout, there are four NUMA nodes, one per socket, and the expected VM configuration would also have 4 vNUMA nodes presented to it for a 32 vCPU configuration. However, what I found while looking at the DMVs in SQL Server was that this wasn't the case:
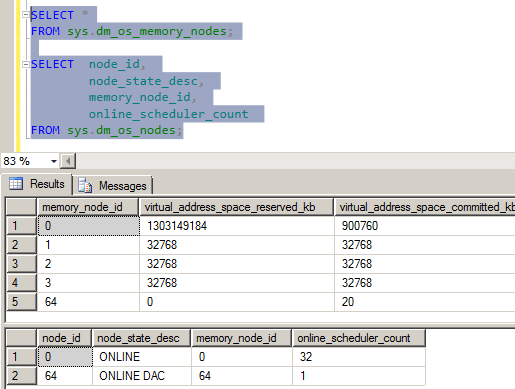
Figure 1 – Incorrect vNUMA configuration
As you can probably see in the image, something is really wrong with the NUMA configuration on this server. There are four memory nodes within SQLOS and only a single CPU Node, with all of the vCPUs allocated in it. To be perfectly honest, this blew my mind when I saw it because it went against everything I knew about how SQLOS configured the internal structures at instance startup. After digging around a bit in the ErrorLog files, Performance Monitor, and Windows Task Manager, I downloaded a copy of CoreInfo from SysInternals, and took a look at the NUMA layout being reported to Windows.
********———————— Socket 0
——–********—————- Socket 1
—————-********——– Socket 2
————————******** Socket 3
Logical Processor to NUMA Node Map:
******************************** NUMA Node 0
The CoreInfo output confirmed that the VM present the 32 vCPUs as 4 different sockets, but then grouped all 32 vCPUs into NUMA Node 0. Looking at the Windows Server 2012 performance counters on the VM I could see from the NUMA Node Memory counter group, that 4 NUMA memory nodes were presented to the OS with the memory evenly distributed across the nodes. This all lined up with what I was seeing in SQLOS, and I could also tell from the startup ERRORLOG entries that the cpu mask for the node was masking all available CPUs into CPU Node 0, but four Large Page Allocators were being created, one for each memory node.
09/22/2013 05:03:37,Server,Unknown,This instance of SQL Server last reported using a process ID of 1596 at 9/22/2013 5:00:25 AM (local) 9/22/2013 10:00:25 AM (UTC). This is an informational message only; no user action is required.
09/22/2013 05:03:35,Server,Unknown,Large Page Allocated: 32MB
09/22/2013 05:03:35,Server,Unknown,Large Page Allocated: 32MB
09/22/2013 05:03:35,Server,Unknown,Large Page Allocated: 32MB
09/22/2013 05:03:35,Server,Unknown,Large Page Allocated: 32MB
09/22/2013 05:03:35,Server,Unknown,Using locked pages in the memory manager.
09/22/2013 05:03:35,Server,Unknown,Detected 524287 MB of RAM. This is an informational message; no user action is required.
09/22/2013 05:03:35,Server,Unknown,SQL Server is starting at normal priority base (=7). This is an informational message only. No user action is required.
09/22/2013 05:03:35,Server,Unknown,SQL Server detected 4 sockets with 8 cores per socket and 8 logical processors per socket 32 total logical processors; using 32 logical processors based on SQL Server licensing. This is an informational message; no user action is required.
At this point I was sure it was something related to the VM configuration, but I couldn't identify what specifically the problem was as I had never seen this behavior on other wide SQL Server VMs that I'd assisted clients on VMware ESX 5+ in the past. After making a couple of configuration changes to a test VM server that was available, only none of them corrected the vNUMA configuration being presented inside the VM. After calling into VMware support, we were asked to disable the vCPU hotplug feature for the test VM and see if that corrected the issue. With hotplug disabled on the VM, the CoreInfo output confirmed that the vNUMA mapping of the processors for the VM now was correct:
********———————— Socket 0
——–********—————- Socket 1
—————-********——– Socket 2
————————******** Socket 3
Logical Processor to NUMA Node Map:
********———————— NUMA Node 0
——–********—————- NUMA Node 1
—————-********——– NUMA Node 2
————————******** NUMA Node 3
This behavior is actually documented in the VMware KB article, (vNUMA is disabled if VCPU hotplug is enabled), from October 2013. This happened to be the first wide VM for SQL Server that I had worked with where vCPU hotplug was enabled, and it's not a typical configuration I would expect for a 32 vCPU VM, but was a part of the standard template being used at the client and happened to affect their SQL Server.
Effects of vNUMA being disabled
There are a number of effects that vNUMA being disabled like this could have to a workload, but there are two specific problems that could affect SQL Server specifically under this type of configuration. The first is that the server could have problems with CMEMTHREAD wait accumulations since there are 32 vCPUs allocated to a single NUMA node, and the default partitioning for memory objects in SQLOS is per NUMA node. This specific problem was documented by Bob Dorr in the CSS group at Microsoft on their blog post SQL Server 2008/2008 R2 on Newer Machines with More Than 8 CPUs Presented per NUMA Node May Need Trace Flag 8048. As a part of doing wait stats review on the VM with the client I noted that CMEMTHREAD was their second highest wait type, which is abnormal from my experience and caused me to look at SQLOS NUMA configuration shown in Figure 1 above. In this case the trace flag isn't the solution, removing vCPU hotplug from the VM configuration resolves the issue.
The second problem that would affect SQL Server specifically if you are on an unpatched version is associated with NUMA memory management in SQLOS, and the way that SQLOS tracks and manages Away pages during the initial memory ramp-up phase after instance startup. This behavior was documented by Bob Dorr on the CSS blog post, How It Works: SQL Server (NUMA Local, Foreign and Away Memory Blocks). Essentially, when SQLOS attempts a local node memory allocation during initial ramp-up, if the memory address returned is from a different memory node, the page is added to the Away list, and another local memory allocation attempt occurs, and the process repeats until a local memory allocation succeeds, or the server memory target is reached. Since three fourths of our instances memory exists on NUMA nodes without any schedulers, this creates a degraded performance condition during the initial ramp-up of memory for the instance. Recent updates have changed the behavior of memory allocation during initial ramp-up to only attempt the local memory allocation a fixed number of times (the specific number is not documented) before using the foreign memory to continue processing. Those updates are documented in KB #2819662, FIX: SQL Server performance issues in NUMA environments.
Summary
For wide VMs, defined as having greater than 8 vCPUs, it is desirable to have vNUMA passed into the VM by the hypervisor to allow Windows and SQL Server to leverage the NUMA optimizations within their code base. As a result, these wider VMs should not have the vCPU hotplug configuration enabled, as this is incompatible with vNUMA and can result in degraded performance for SQL Server when virtualized.



What about the memory hot-add setting? What affect does this have? Should this be disabled also on VM's with more than 8vCPUs?
Thank you very much for the article and your studies.
Hi Jonathan,
Great Post. Will be obliged if here you elaborate about why memory_node_id=0 taking more memory than other memory_node_id>0.
Regards
Helpful post and timeless as this is a bigger issue apparently with Sql Server 2016 I have found. 2012 at least ran – 2016 froze up when the hot plug cpu was enabled. Also have question about hot plug memory – vmware best practices says "As with CPU hot plug, it is preferable to rely on rightsizing than on memory hot plug. The decision whether to use this feature should be made on a case-by-case basis and not implemented in the VM template used to deploy SQL Server." But they don't say why.