
Expanding the uses of DBCC CLONEDATABASE
Service Pack 2 for SQL Server 2014 was released last month (read the release notes here) and includes a new DBCC statement: DBCC CLONEDATABASE. I was pretty excited to see this command introduced, as it provides a very easy way to copy a database schema, including statistics, which can be used for testing query performance without requiring all the space needed for the data in the database. I finally made some time to test out DBCC CLONEDATABASE and understand the limitations, and I have to say it was rather fun.
The Basics
I started out by creating a clone of the AdventureWorks2014 database and running a query against the source database and then the clone database:
DBCC CLONEDATABASE (N'AdventureWorks2014', N'AdventureWorks2014_CLONE');
GO
SET STATISTICS IO ON;
GO
SET STATISTICS TIME ON;
GO
SET STATISTICS XML ON;
GO
USE [AdventureWorks2014];
GO
SELECT *
FROM [Sales].[SalesOrderHeader] [h]
JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID]
ORDER BY [SalesOrderDetailID];
GO
USE [AdventureWorks2014_CLONE];
GO
SELECT *
FROM [Sales].[SalesOrderHeader] [h]
JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID]
ORDER BY [SalesOrderDetailID];
GO
SET STATISTICS IO OFF;
GO
SET STATISTICS TIME OFF;
GO
SET STATISTICS XML OFF;
GO
If I look at the I/O and TIME output, I can see that the query against the source database took longer and generated a lot more I/O, both of which are expected as the clone database has no data in it:
/* SOURCE database */
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 4 ms.
(121317 row(s) affected)
Table 'SalesOrderHeader'. Scan count 0, logical reads 371567, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SalesOrderDetail'. Scan count 5, logical reads 1361, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 686 ms, elapsed time = 2548 ms.
/* CLONE database */
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 12 ms, elapsed time = 12 ms.
(0 row(s) affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SalesOrderHeader'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SalesOrderDetail'. Scan count 5, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 83 ms.
If I look at the execution plans, they are the same for both databases except for the actual values (the amount of data that actually moved through the plan):
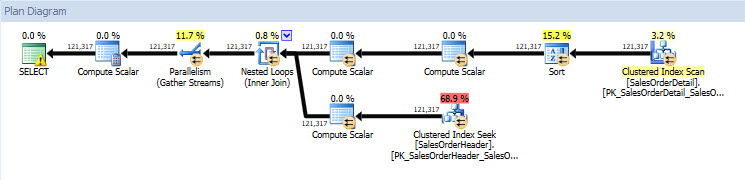 Query Plan for AdventureWorks2014 database
Query Plan for AdventureWorks2014 database
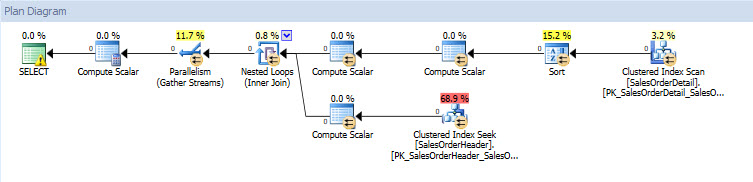 Query Plan for AdventureWorks2014_CLONE database
Query Plan for AdventureWorks2014_CLONE database
This is where the value of DBCC CLONEDATABASE is apparent – I can get an empty copy of a database to anyone (Microsoft Product Support, my fellow DBA, etc.) and have them recreate and investigate an issue, and they don't need potentially hundreds of GB of disk space to do it. Melissa’s July T-SQL Tuesday post has detailed information about what happens during the clone process, so I recommend reading that for more information.
Is that it?
But… can I do more with DBCC CLONEDATABASE? I mean, this is great, but I think there are a lot of other things I can do with an empty copy of the database. If you read the documentation for DBCC CLONEDATABASE, you’ll see this line:
My first thought was, “query optimizer – hmm… can I use this as an option for testing upgrades?”
Well, the cloned database is read-only, but I thought I’d try to change some options anyway. For example, if I could change the compatibility mode, that would be really cool, as then I could test CE changes in both SQL Server 2014 and SQL Server 2016.
USE [master];
GO
ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 110;
I get an error:
Failed to update database "AdventureWorks2014_CLONE" because the database is read-only.
Msg 5069, Level 16, State 1
ALTER DATABASE statement failed.
Hm. Can I change the recovery model?
ALTER DATABASE [AdventureWorks2014_CLONE] SET RECOVERY SIMPLE WITH NO_WAIT;
I can. That doesn’t seem fair. Well, it’s read-only, can I change that?
ALTER DATABASE [AdventureWorks2014_CLONE] SET READ_WRITE WITH NO_WAIT;
YES! Before you get too excited, let me leave this note from the documentation right here:
I'm going to repeat this line from the documentation, and bold it and put it red as a friendly but extremely important reminder:
Well that’s fine with me, I definitely wasn’t going to use this for production, but now I can use it for testing! NOW I can change the compatibility mode, and NOW I can back it up and restore it on another instance for testing!
USE [master];
GO
BACKUP DATABASE [AdventureWorks2014_CLONE]
TO DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak'
WITH INIT, NOFORMAT, STATS = 10, NAME = N'AW2014_CLONE_full';
GO
/* restore on SQL Server 2016 */
RESTORE DATABASE [AdventureWorks2014_CLONE]
FROM DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak' WITH
MOVE N'AdventureWorks2014_Data' TO N'C:\Databases\AdventureWorks2014_Data_2684624044.mdf',
MOVE N'AdventureWorks2014_Log' TO N'C:\Databases\AdventureWorks2014_Log_3195542593.ldf',
NOUNLOAD, REPLACE, STATS = 5;
GO
ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 130;
GO
THIS IS BIG.
In my last post I talked about trace flag 2389 and testing with the new Cardinality Estimator because, friends, you need to be testing with the new CE before you upgrade. If you do not test, and if you change the compatibility mode to 120 (SQL Server 2014) or 130 (SQL Server 2016) as part of your upgrade, then you run the risk of working in a fire-fighting mode if you run into regressions with the new CE. Now, you could be just fine, and performance may be even better after you upgrade. But… wouldn’t you like to be certain?
Very often when I mention testing before an upgrade, I’m told that there is no environment in which to do the testing. I know some of you have a Test environment. Some of you have Test, Dev, QA, UAT and who knows what else. You’re lucky.
For those of you that state you have no test environment at all in which to test, I give you DBCC CLONEDATABASE. With this command, you have no excuse to not run the most frequently-executed queries and the heavy-hitters against a clone of your database. Even if you don’t have a test environment, you have your own machine. Backup the clone database from production, drop the clone, restore the backup to your local instance, and then test. The clone database takes up very little space on disk and you won’t incur memory or I/O contention as there’s no data. You will be able to validate query plans from the clone against those from your production database. Further, if you restore on SQL Server 2016 you can incorporate Query Store into your testing! Enable Query Store, run through your testing in the original compatibility mode, then upgrade the compatibility mode and test again. You can use Query Store to compare queries side by side! (Can you tell I'm dancing in my chair right now?)
Considerations
Again, this shouldn't be anything you would use in production, and I know you wouldn't do that, but it bears repeating because in its current state, DBCC CLONEDATABASE is not fully complete. This is noted in the KB article under supported objects; objects such as memory optimized tables and file tables are not copied, Full-text is not supported, etc.
Now, the clone database isn’t without drawbacks. If you inadvertently run an index rebuild or an update to statistics in that database, you’ve just wiped out your test data. You will lose the original statistics which is what probably you really wanted in the first place. For example, if I check statistics for the clustered index on SalesOrderHeader right now, I get this:
USE [AdventureWorks2014_CLONE];
GO
DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 Original statistics for SalesOrderHeader
Original statistics for SalesOrderHeader
Now, if I update statistics against that table, I get this:
UPDATE STATISTICS [Sales].[SalesOrderHeader] WITH FULLSCAN;
GO
DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 Updated (empty) statistics for SalesOrderHeader
Updated (empty) statistics for SalesOrderHeader
As an additional safety, it's probably a good idea to disable auto updates to statistics:
USE [master];
GO
ALTER DATABASE [AdventureWorks2014_CLONE] SET AUTO_UPDATE_STATISTICS OFF WITH NO_WAIT;
If you do happen to update statistics unintentionally, running DBCC CLONEDATABASE and going through the backup and restore process isn’t that hard, and you’ll have it automated in no time.
You can add data to the database. This could be useful if you want to experiment with statistics (e.g. different sample rates, filtered statistics) and you have enough storage to hold a copy of the table’s data.
With no data in the database, you’re obviously not going to get reliably representative duration and I/O data. That’s ok. If you need data about true resource usage, then you need a copy of your database with all the data in it. DBCC CLONEDATABASE is really about testing query performance; that’s it. It’s not a replacement for traditional upgrade testing in any way – but it is a new option for validating how SQL Server optimizes a query with different versions and compatibility modes. Happy testing!
12 thoughts on “Expanding the uses of DBCC CLONEDATABASE”
Comments are closed.

Thanks for the article.
This feature is still not available in SQL Server 2016…curious !
You're right, it will probably be introduced in the first service pack for 2016 (or, who knows, maybe even in a cumulative update).
Interesting thanks. Anyone know if it's possible to clone the database to a separate SQL Server instance?
No, the DBCC command works locally and doesn't have arguments for targeting a different instance. But the database is empty, so you can backup / restore to a different instance after the clone is complete, right?
Great! Thanks Kevin. Copying stats (without the current hassle) as well as the database structure (without data) is so useful for validating query plans haven't changed when replaying queries, or reviewing prospective query plans on a dev system when performance tuning.
Worth mentioning that copied stats data values can often contain data privacy issues – so you likely need to keep that cloned DB secure as though live despite having 'no data'.
Very Useful Information.Nice post ! I know I'll be using that feature a lot at work :)
Thanks !!
I know this is an old post, but stumbled here and was just wondering what kind of data might the stats contain that would lead to privacy issues if Joe Bloggs got there hands on the cloned DB?
Peter-
It depends on the statistic key. If the leading column in an index (or column statistic) is account number, then the histogram would have up to 200 different account numbers in it. If the leading column is last name, then you'll see up to 200 different last names. In your database, pick any table and index, and run DBCC SHOW_STATISTICS ('tablename', indexname) and look at the last section of output (the histogram). That's the data that could be viewed if someone had access to a cloned database.
Hope that helps,
Erin
Thanks for the reply – yeah that helps a lot.
I'm mainly a C# dev and whilst I write and deal with T-SQL all the time when it comes to going beyond that SQL Server (pretty much all DBA stuff, stats and the like) I don't really know a lot.
Don't even really know how I'd use a clone DB such as this for performance tuning
I can't believe I just found out about this! Super cool!!
Pls here will be obliged if upgraded with new information abt sql 2019 sql 2017 and 2016 too.
Thx
Hi Manish-
If you're looking for updates related to the command, I recommend reviewing the documentation: https://docs.microsoft.com/en-us/sql/t-sql/database-console-commands/dbcc-clonedatabase-transact-sql?view=sql-server-2017. The principles for HOW to use DBCC CLONEDATABASE are still applicable through vNext (SQL 2019 at this point), with the main addition in 2019 being columnstore statistics.
Hope that helps