


Benjamin Nevarez is an independent consultant based in Los Angeles, California who specializes in SQL Server query tuning and optimization. He is the author of “SQL Server 2014 Query Tuning & Optimization” and “Inside the SQL Server Query Optimizer” and co-author of “SQL Server 2012 Internals”. With more than 20 years of experience in relational databases, Benjamin has also been a speaker at many SQL Server conferences, including the PASS Summit, SQL Server Connections and SQLBits. Benjamin’s blog can be found at http://www.benjaminnevarez.com and he can also be reached by e-mail at admin at benjaminnevarez dot com and on twitter at @BenjaminNevarez.
While most of the information, blogs and documentation about SQL Server 2014 have focused on Hekaton and other new features, not many details have been provided about the new cardinality estimator. Currently BOL only indirectly talks about it on the What’s New (Database Engine) section, saying that SQL Server 2014 “includes substantial improvements to the component that creates and optimizes query plans,” and the ALTER DATABASE statement shows how to enable or disable its behavior. Fortunately we can get some additional information by reading the research paper Testing Cardinality Estimation Models in SQL Server by Campbell Fraser et al. Although the focus of the paper is the quality assurance process of the new estimation model, it also offers a basic introduction to the new cardinality estimator, and the motivation of its redesign.
So, what is a cardinality estimator? A cardinality estimator is the component of the query processor whose job is to estimate the number of rows returned by relational operations in a query. This information, along with some other data, is used by the query optimizer to select an efficient execution plan. Cardinality estimation is inherently inexact, as it is a mathematical model which relies on statistical information. It is also based on several assumptions which, although not documented, have been known over the years – some of them include the uniformity, independence, containment and inclusion assumptions. A brief description of these assumptions follows.
- Uniformity. Used when the distribution for an attribute is unknown, for example, inside of range rows in a histogram step or when a histogram is not available.
- Independence. Used when the attributes in a relation are independent, unless a correlation between them is known.
- Containment. Used when two attributes might be the same, they are assumed to be the same.
- Inclusion. Used when comparing an attribute with a constant, it is assumed there is always a match.
It is interesting that I just recently talked about some of the limitations of these assumptions at my last talk at the PASS Summit, called Defeating the Limitations of the Query Optimizer. Yet I was surprised to read in the paper that the authors admit that, according to their experience in practice, these assumptions are “frequently incorrect.”
The current cardinality estimator was written along with the entire query processor for SQL Server 7.0, which was released back in December of 1998. Obviously this component has faced multiple changes during several years and multiple releases of SQL Server, including fixes, adjustments and extensions to accommodate cardinality estimation for new T-SQL features. So you may be thinking, why replace a component which has been successfully used in for about 15 years?
Why a New Cardinality Estimator
The paper explains some of the reasons of the redesign including:
- To accommodate the cardinality estimator to new workload patterns.
- Changes made to the cardinality estimator over the years made the component difficult to “debug, predict, and understand.”
- Trying to improve on the current model was difficult using the current architecture, so a new design was created, focused on the separation of tasks of (a) deciding how to compute a particular estimate, and (b) actually performing the computation.
I am not sure if more details about the new cardinality estimator are going to be published by Microsoft. After all, not so many details were ever published about the old cardinality estimator in 15 years; for example, how some specific cardinality estimation is calculated. On the other hand, there are new extended events which we can use to troubleshoot problems with cardinality estimation, or just to explore how it works. These events include query_optimizer_estimate_cardinality, inaccurate_cardinality_estimate, query_optimizer_force_both_cardinality_estimation_behaviors and query_rpc_set_cardinality.
Plan Regressions
A major concern that comes to mind with such a huge change inside the query optimizer is plan regressions. The fear of plan regressions has been considered the biggest obstacle to query optimizer improvements. Regressions are problems introduced after a fix has been applied to the query optimizer and sometimes referred as the classic “two wrongs make a right.” This can happen when two bad estimations, for example one overestimating a value and the second one underestimating it, cancel each other out, luckily giving a good estimate. Correcting only one of these values may now lead to a bad estimation which may negatively impact the choice of plan selection, causing a regression.
To help avoid regressions related to the new cardinality estimator, SQL Server provides a way to enable or disable it, as it depends on the database compatibility level. This can be changed using the ALTER DATABASE statement, as indicated earlier. Setting a database to the compatibility level 120 will use the new cardinality estimator, while a compatibility level less than 120 will use the old cardinality estimator. In addition, once you are using a specific cardinality estimator, there are two trace flags you can use to change to the other. Although at the moment I don’t see the trace flags documented anywhere, they are mentioned as part of the description of the query_optimizer_force_both_cardinality_estimation_behaviors extended event. Trace flag 2312 can be used to enable the new cardinality estimator, while trace flag 9481 can be used to disable it. You can even use the trace flags for a specific query using the QUERYTRACEON hint (though it is not yet documented if this will be supported either).
Examples
Finally, the paper also mentions some tested scenarios like the overpopulated primary key, simple join, or the ascending key problem. It also shows how the authors experimented with multiple scenarios (or model variations) and in some cases “relaxed” some of the assumptions made by the cardinality estimator, for example, in the case of the independency assumption, going from complete independence to complete correlation and something in between until good results were found.
Although no details are provided on the paper I decide to start testing some of these scenarios to try to understand how the new cardinality estimator works. For now I will show you example using the independence assumption and ascending keys. I also tested the uniformity assumption but so far was not able to find any difference on estimation.
Let start with the independency assumption example. First let us see the current behavior. For that, make sure you are using the old cardinality estimator by running the following statement on the AdventureWorks2012 database:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110;
Then run:
SELECT * FROM Person.Address WHERE City = 'Burbank';
We get an estimated of 196 records as shown next:

In a similar way the following statement will get an estimated of 194:
SELECT * FROM Person.Address WHERE PostalCode = '91502';
If we use both predicates we have the following query, which will have an estimated number of rows of 1.93862 (rounded up to 2 rows if using SQL Sentry Plan Explorer):
SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
This value is calculated assuming total independence of both predicates, which uses the formula (196 * 194) / 19614.0 (where 19614 is the total number of rows in the table). Using a total correlation should give us an estimate of 194, as all the records with postal code 91502 belong to Burbank. The new cardinality estimator estimates a value which does not assume total independence or total correlation. Change to the new cardinality estimator using the following statement:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120;
GO
SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Running the same statement again will give an estimate of 19.3931 rows, which you can see is a value between assuming total independence and total correlation (rounded up to 19 rows in Plan Explorer). The formula used is selectivity of most selective filter * SQRT(selectivity of next most selective filter) or (194/19614.0) * SQRT(196/19614.0) * 19614 which gives 19.393:

If you have enabled the new cardinality estimator at the database level buy want to disable it for a specific query to avoid a plan regression, you can use trace flag 9481 as explained earlier:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120;
GO
SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502'
OPTION (QUERYTRACEON 9481);
Note: The QUERYTRACEON query hint is used to apply a trace flag at the query level and currently it is only supported in a limited number of scenarios. For more information about the QUERYTRACEON query hint you can look at http://support.microsoft.com/kb/2801413.
Now let us look at the ascending key problem, a topic I’ve explained in more detail in this post. The traditional recommendation from Microsoft to fix this problem is to manually update statistics after loading data, as explained here – which describes the problem in the following way:
Statistics on ascending or descending key columns, such as IDENTITY or real-time timestamp columns, might require more frequent statistics updates than the query optimizer performs. Insert operations append new values to ascending or descending columns. The number of rows added might be too small to trigger a statistics update. If statistics are not up-to-date and queries select from the most recently added rows, the current statistics will not have cardinality estimates for these new values. This can result in inaccurate cardinality estimates and slow query performance. For example, a query that selects from the most recent sales order dates will have inaccurate cardinality estimates if the statistics are not updated to include cardinality estimates for the most recent sales order dates.
The recommendation in my article was to use trace flags 2389 and 2390, which were first published by Ian Jose in his article Ascending Keys and Auto Quick Corrected Statistics. You can read my article for an explanation and example on how to use these trace flags to avoid this problem. These trace flags still work on SQL Server 2014 CTP2. But even better, they are no longer needed if you are using the new cardinality estimator.
Using the same example in my post:
CREATE TABLE dbo.SalesOrderHeader (
SalesOrderID int NOT NULL,
RevisionNumber tinyint NOT NULL,
OrderDate datetime NOT NULL,
DueDate datetime NOT NULL,
ShipDate datetime NULL,
Status tinyint NOT NULL,
OnlineOrderFlag dbo.Flag NOT NULL,
SalesOrderNumber nvarchar(25) NOT NULL,
PurchaseOrderNumber dbo.OrderNumber NULL,
AccountNumber dbo.AccountNumber NULL,
CustomerID int NOT NULL,
SalesPersonID int NULL,
TerritoryID int NULL,
BillToAddressID int NOT NULL,
ShipToAddressID int NOT NULL,
ShipMethodID int NOT NULL,
CreditCardID int NULL,
CreditCardApprovalCode varchar(15) NULL,
CurrencyRateID int NULL,
SubTotal money NOT NULL,
TaxAmt money NOT NULL,
Freight money NOT NULL,
TotalDue money NOT NULL,
Comment nvarchar(128) NULL,
rowguid uniqueidentifier NOT NULL,
ModifiedDate datetime NOT NULL
);
Insert some data:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader
WHERE OrderDate < '2008-07-20 00:00:00.000';
CREATE INDEX IX_OrderDate ON SalesOrderHeader(OrderDate);
Since we created an index we just have new statistics. Running the following query will create a good estimate of 35 rows:
SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-19 00:00:00.000';
If we insert new data:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader
WHERE OrderDate = '2008-07-20 00:00:00.000';
You can see the estimate with the old cardinality estimator as shown next:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110;
GO
SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';

Since the small number of records inserted was not enough to trigger an automatic update of the statistics object, the current histogram is not aware of the new records added and the query optimizer uses an estimated of 1 row. Optionally you could use trace flags 2389 and 2390 to help to obtain a better estimation. But if you try the same query with the new cardinality estimator, you get the following estimation:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120;
GO
SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
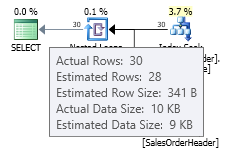
In this case we get a better estimation than the old cardinality estimator (or we get the same estimation as using trace flags 2389 or 2390). The estimated value of 27.9631 (again, rounded to 28 by Plan Explorer) is calculated using the density information of the statistics object multiplied by the number of rows of the table; that is, 0.0008992806 * 31095. The density value can be obtained using:
DBCC SHOW_STATISTICS('dbo.SalesOrderHeader', 'IX_OrderDate');
Finally, keep in mind that nothing mentioned in this article is documented, and this is the behavior I have observed so far in SQL Server 2014 CTP2. Any of this could change in a later CTP or the RTM version of the product.



This is really a great information. It is very rare to see this kind of internal information about SQL Server. I'm looking forward to read the research paper mentioned in the article too.
Thanks Benjamin. Very useful information to me :)