


From time to time I see someone express a requirement to create a random number for a key. Usually this is to create some type of surrogate CustomerID or UserID that is a unique number within some range, but is not issued sequentially, and is therefore far less guessable than an IDENTITY value.
NEWID() solves the guessing issue, but the performance penalty is usually a deal-breaker, especially when clustered: much wider keys than integers, and page splits due to non-sequential values. NEWSEQUENTIALID() solves the page split problem, but is still a very wide key, and re-introduces the issue that you can guess the next value (or recently-issued values) with some level of accuracy.
As a result, they want a technique to generate a random and unique integer. Generating a random number on its own is not difficult, using methods like RAND() or CHECKSUM(NEWID()). The problem comes when you have to detect collisions. Let's take a quick look at a typical approach, assuming we want CustomerID values between 1 and 1,000,000:
DECLARE @rc INT = 0,
@CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1;
-- or ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1;
-- or CONVERT(INT, RAND() * 1000000) + 1;
WHILE @rc = 0
BEGIN
IF NOT EXISTS (SELECT 1 FROM dbo.Customers WHERE CustomerID = @CustomerID)
BEGIN
INSERT dbo.Customers(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT @CustomerID = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@rc = 0;
END
END
As the table gets larger, not only does checking for duplicates get more expensive, but your odds of generating a duplicate go up as well. So this approach may seem to work okay when the table is small, but I suspect that it must hurt more and more over time.
A Different Approach
I am a huge fan of auxiliary tables; I've been writing publicly about calendar tables and tables of numbers for a decade, and using them for far longer. And this is a case where I think a pre-populated table could come in real handy. Why rely on generating random numbers at runtime and dealing with potential duplicates, when you can populate all of those values in advance and know – with 100% certainty, if you protect your tables from unauthorized DML – that the next value you select has never been used before?
CREATE TABLE dbo.RandomNumbers1
(
RowID INT,
Value INT, --UNIQUE,
PRIMARY KEY (RowID, Value)
);
;WITH x AS
(
SELECT TOP (1000000) s1.[object_id]
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
ORDER BY s1.[object_id]
)
INSERT dbo.RandomNumbers(RowID, Value)
SELECT
r = ROW_NUMBER() OVER (ORDER BY [object_id]),
n = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM x
ORDER BY r;
This population took 9 seconds to create (in a VM on a laptop), and occupied around 17 MB on disk. The data in the table looks like this:
(If we were worried about how the numbers were getting populated, we could add a unique constraint on the Value column, which would make the table 30 MB. Had we applied page compression, it would have been 11 MB or 25 MB, respectively.)
I created another copy of the table, and populated it with the same values, so that I could test two different methods of deriving the next value:
CREATE TABLE dbo.RandomNumbers2
(
RowID INT,
Value INT, -- UNIQUE
PRIMARY KEY (RowID, Value)
);
INSERT dbo.RandomNumbers2(RowID, Value)
SELECT RowID, Value FROM dbo.RandomNumbers1;
Now, anytime we want a new random number, we can just pop one off the stack of existing numbers, and delete it. This prevents us from having to worry about duplicates, and allows us to pull numbers – using a clustered index – that are actually already in random order. (Strictly speaking, we don't have to delete the numbers as we use them; we could add a column to indicate whether a value has been used – this would make it easier to reinstate and reuse that value in the event that a Customer later gets deleted or something goes wrong outside of this transaction but before they are fully created.)
DECLARE @holding TABLE(CustomerID INT);
DELETE TOP (1) dbo.RandomNumbers1
OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers(CustomerID, ...other columns...)
SELECT CustomerID, ...other params...
FROM @holding;
I used a table variable to hold the intermediate output, because there are various limitations with composable DML that can make it impossible to insert into the Customers table directly from the DELETE (for example, the presence of foreign keys). Still, acknowledging that it won't always be possible, I also wanted to test this method:
DELETE TOP (1) dbo.RandomNumbers2
OUTPUT deleted.Value, ...other params...
INTO dbo.Customers(CustomerID, ...other columns...);
Note that neither of these solutions truly guarantee random order, particularly if the random numbers table has other indexes (such as a unique index on the Value column). There is no way to define an order for a DELETE using TOP; from the documentation:
So, if you want to guarantee random ordering, you could do something like this instead:
DECLARE @holding TABLE(CustomerID INT);
;WITH x AS
(
SELECT TOP (1) Value
FROM dbo.RandomNumbers2
ORDER BY RowID
)
DELETE x OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers(CustomerID, ...other columns...)
SELECT CustomerID, ...other params...
FROM @holding;
Another consideration here is that, for these tests, the Customers tables have a clustered primary key on the CustomerID column; this will certainly lead to page splits as you insert random values. In the real world, if you had this requirement, you would probably end up clustering on a different column.
Note that I've also left out transactions and error handling here, but these too should be a consideration for production code.
Performance Testing
To draw some realistic performance comparisons, I created five stored procedures, representing the following scenarios (testing speed, distribution, and collision frequency of the different random methods, as well as the speed of using a predefined table of random numbers):
- Runtime generation using
CHECKSUM(NEWID()) - Runtime generation using
CRYPT_GEN_RANDOM() - Runtime generation using
RAND() - Predefined numbers table with table variable
- Predefined numbers table with direct insert
They use a logging table to track duration and number of collisions:
CREATE TABLE dbo.CustomerLog
(
LogID INT IDENTITY(1,1) PRIMARY KEY,
pid INT,
collisions INT,
duration INT -- microseconds
);
The code for the procedures follows (click to show/hide):
/* Runtime using CHECKSUM(NEWID()) */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Checksum]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_Checksum
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_Checksum(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 1, @collisions, @duration;
END
GO
/* runtime using CRYPT_GEN_RANDOM() */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_CryptGen]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_CryptGen
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_CryptGen(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 2, @collisions, @duration;
END
GO
/* runtime using RAND() */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Rand]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = CONVERT(INT, RAND() * 1000000) + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_Rand
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_Rand(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = CONVERT(INT, RAND() * 1000000) + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 3, @collisions, @duration;
END
GO
/* pre-defined using a table variable */
CREATE PROCEDURE [dbo].[AddCustomer_Predefined_TableVariable]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @start DATETIME2(7) = SYSDATETIME(), @duration INT;
DECLARE @holding TABLE(CustomerID INT);
DELETE TOP (1) dbo.RandomNumbers1
OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers_Predefined_TableVariable(CustomerID)
SELECT CustomerID FROM @holding;
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, duration) SELECT 4, @duration;
END
GO
/* pre-defined using a direct insert */
CREATE PROCEDURE [dbo].[AddCustomer_Predefined_Direct]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @start DATETIME2(7) = SYSDATETIME(), @duration INT;
DELETE TOP (1) dbo.RandomNumbers2
OUTPUT deleted.Value INTO dbo.Customers_Predefined_Direct;
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, duration) SELECT 5, @duration;
END
GO
And in order to test this, I would run each stored procedure 1,000,000 times:
EXEC dbo.AddCustomer_Runtime_Checksum;
EXEC dbo.AddCustomer_Runtime_CryptGen;
EXEC dbo.AddCustomer_Runtime_Rand;
EXEC dbo.AddCustomer_Predefined_TableVariable;
EXEC dbo.AddCustomer_Predefined_Direct;
GO 1000000
Not surprisingly, the methods using the predefined table of random numbers took slightly longer *at the beginning of the test*, since they had to perform both read and write I/O every time. Keeping in mind that these numbers are in microseconds, here are the average durations for each procedure, at different intervals along the way (averaged over the first 10,000 executions, the middle 10,000 executions, the last 10,000 executions, and the last 1,000 executions):
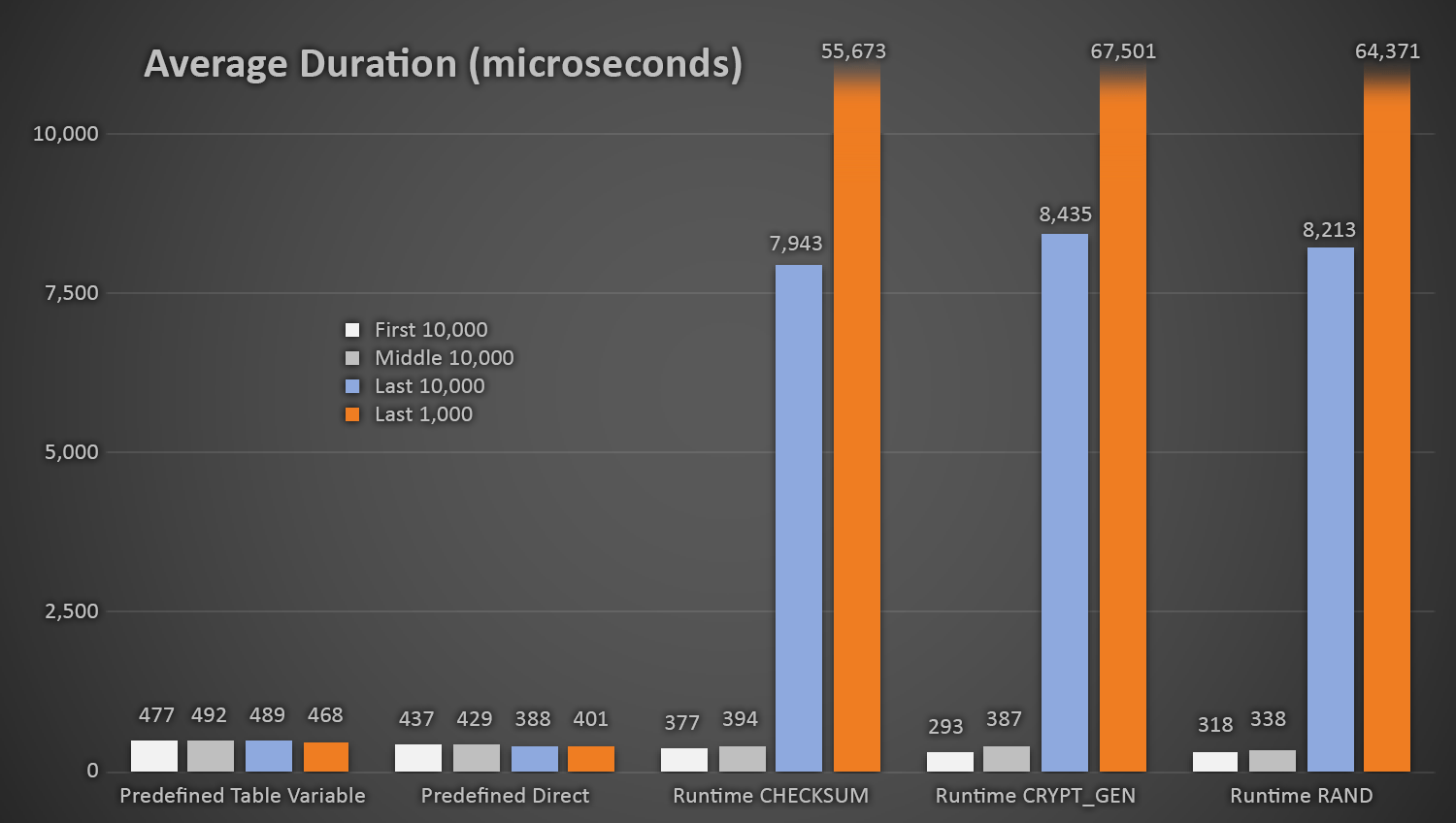
Average duration (in microseconds) of random generation using different approaches
This works out well for all methods when there are few rows in the Customers table, but as the table gets larger and larger, the cost of checking the new random number against the existing data using the runtime methods increases substantially, both because of increased I/O and also because the number of collisions goes up (forcing you to try and try again). Compare the average duration when in the following ranges of collision counts (and remember that this pattern only affects the runtime methods):
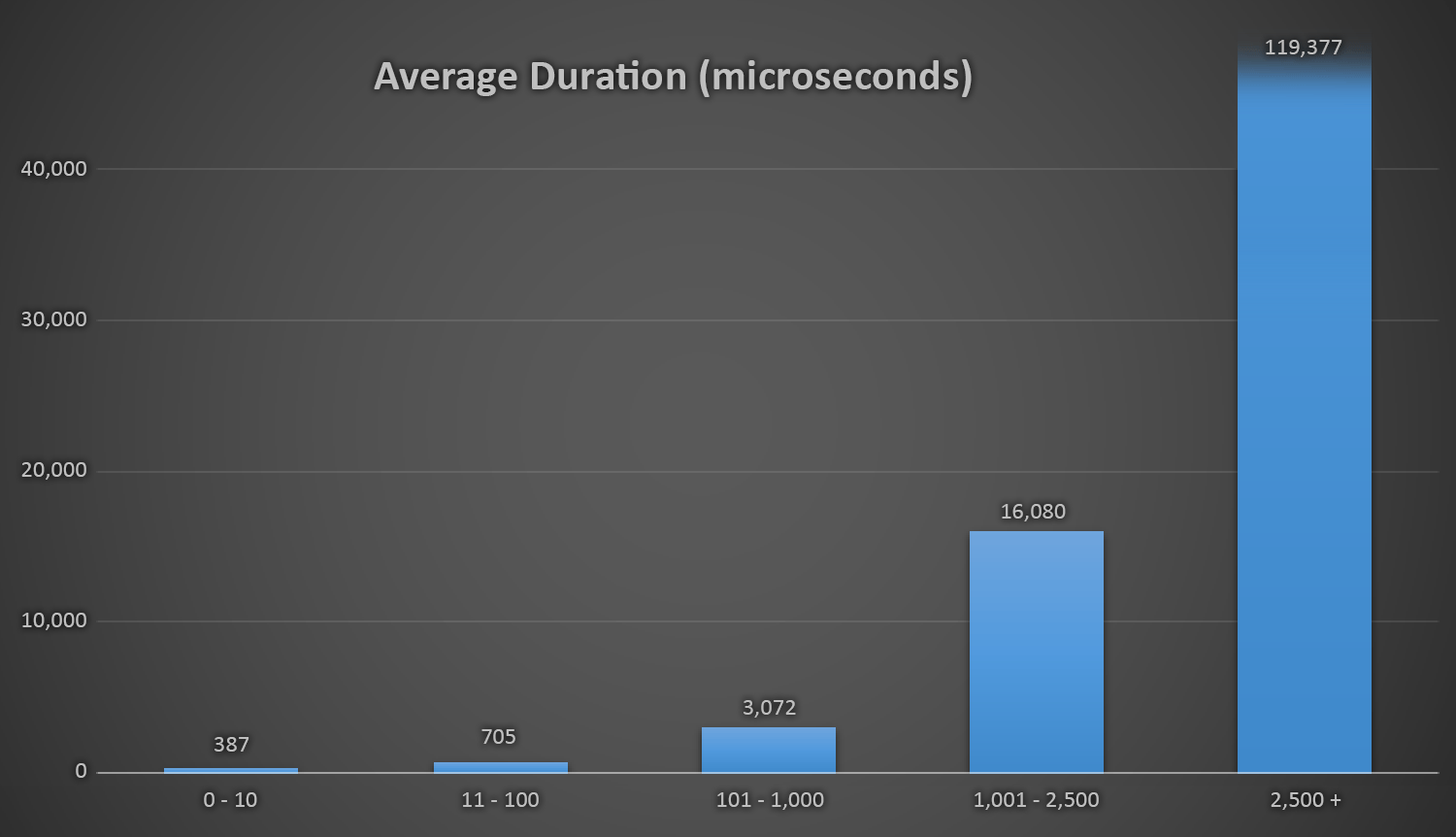
Average duration (in microseconds) during different ranges of collisions
I wish there were a simple way to graph duration against collision counts. I'll leave you with this tidbit: on the last three inserts, the following runtime methods had to perform this many attempts before they finally stumbled upon the last unique ID they were looking for, and this is how long it took:
| Number of collisions | Duration (microseconds) | ||
|---|---|---|---|
| CHECKSUM(NEWID()) | 3rd to last row | 63,545 | 639,358 |
| 2nd to last row | 164,807 | 1,605,695 | |
| Last row | 30,630 | 296,207 | |
| CRYPT_GEN_RANDOM() | 3rd to last row | 219,766 | 2,229,166 |
| 2nd to last row | 255,463 | 2,681,468 | |
| Last row | 136,342 | 1,434,725 | |
| RAND() | 3rd to last row | 129,764 | 1,215,994 |
| 2nd to last row | 220,195 | 2,088,992 | |
| Last row | 440,765 | 4,161,925 | |
Excessive duration and collisions near the end of the line
It is interesting to note that the last row isn't always the one that yields the highest number of collisions, so this can start to be a real problem long before you've used up 999,000+ values.
Another consideration
You may want to consider setting up some kind of alert or notification when the RandomNumbers table starts getting below some number of rows (at which point you can re-populate the table with a new set from 1,000,001 – 2,000,000, for example). You would have to do something similar if you were generating random numbers on the fly – if you are keeping that to within a range of 1 – 1,000,000, then you'd have to change the code to generate numbers from a different range once you've used up all of those values.
If you are using the random number at runtime method, then you can avoid this situation by constantly changing the pool size from which you draw a random number (which should also stabilize and drastically reduce the number of collisions). For example, instead of:
DECLARE @CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1;
You could base the pool on the number of rows already in the table:
DECLARE @total INT = 1000000 + ISNULL(
(SELECT SUM(row_count) FROM sys.dm_db_partition_stats
WHERE [object_id] = OBJECT_ID('dbo.Customers') AND index_id = 1),0);
Now your only real worry is when you approach the upper bound for INT…
Note: I also recently wrote a tip about this at MSSQLTips.com.



Aaron –
Love the post!
There is another method out there I've personally found useful – "primitive ploynomials.' I learned of it while reading one of Joe Celko's books. The algorithm is very lean (even in T-SQL), and the overhead minimal and linear for all values – requires only storing the last used value (read last, compute & write the new). Here's a link to more details: http://joecelkothesqlapprentice.blogspot.com/2006/11/one-to-one-random-mapping-between-int.html
Thanks for a great post,
Michael Smith,
Microsoft Certified Master – SQL Server 2008
Nice tip.
Only I need like ten billion non colliding ids and I am curious how to go about it
Thanks.
Hello Aaron –
Thank you for the post it was something great to look into and to see. I have a different method that worked for me and my group, that was similar to your first example and something that "we" on 5/17/2016 had asked about.
I adjusted the table that I had to have a "uniqueidentifier" as a field and then to have a calculated column based on that field to give me a 10 digit ID, which would be 9.99 billion (possibly what "we" was asking for.
CREATE TABLE [dbo].[tblClubID](
[uidNewID] [uniqueidentifier] NOT NULL,
[intClubID] AS (abs(checksum([uidNewID])))
)
Then I had a Stored Procedure for the entry/insert into the table. Instead of using the "NOT EXISTS" or "EXISTS" clauses /functions, I just did a search in the table looking for that ID already with an equal and put that, plus the variable creation, inside a while loop. So if the number / ID exists, it would loop through again and try to create a new number / id.
Performance wise, I did not see any slowdown as we were adding 50k ID's and there was already 500k in there. I am sorry I don't have the tools handy for this example that Aaron had, but I am interested.
I would assume that after about 500 million records in there it would slow down (and leading up to that as well), as the odds of creating a number that already exists would be approaching 50%, causing another loop or more.
We had initial plans for 250k, knowing that one day we might need a full million, and we are already there, so needing 10 million is something that was on the radar for us.
The requirement we also had was that when someone was making a new entry, they would also be returned what their ID was right away. That is the extra "OUTPUT" line in the middle of the INSERT AND VALUE clauses.
One other thing to note with the OUTPUT, I have the calculated field stored as an INT but the OUTPUT is a 10 character nvarchar. There is a view that also does this conversion, as well as another lookup stored proc. I noticed that when the ID had the CAST and then the 0-padding and then the RIGHT operators all on it, it really slowed things down just for the INSERT, which is the part that I really cared about speed. I *think* (and I could be wrong), I would have to perform that operation on the CHECKSUM result and then the comparison became really slow. I think that the speed of comparison for integers is faster than that of strings (I don't have anything handy to back that up, but please let me know). If there is a person that needs a single entry, its already going to be quick, so I tried to put the "formatting" functions on the value at the time when there would need to be a format visible (ie – the OUTPUT).
The Stored Procedure below….
CREATE PROCEDURE [dbo].[sprocClubInsertNewMember]
— procedure variables
— data associated with the club id
AS
BEGIN
DECLARE @NewID UNIQUEIDENTIFIER;
DECLARE @newCKS INT;
DECLARE @noDups int = 1;
WHILE @noDups >= 1
BEGIN
SET @NewID = NEWID();
SET @newCKS = (abs(checksum(@NewID)));
SET @noDups = COALESCE((SELECT intClubID FROM myClubTable WHERE intClubID = @newCKS),0)
END
INSERT INTO myClubTable (…, …, …, …)
OUTPUT RIGHT('000000000' + CAST(Inserted.intClubID AS VARCHAR(10)),10)
VALUES (…, …, …, …)
END
GO